
Il est bien maintenant connu que le mot de passe présente à la fois une grande surface d’attaque (phishing, brute force, password spreading, rainbow table, etc.) tout en offrant une expérience utilisateur frustrante. L’objectif de cet article n’est pas de revenir sur ces aspects, mais c’est pour ces raisons qu’il est attaqué depuis plusieurs années au profit du passwordless. Cependant, de nombreux freins, autant techniques qu’humains, font qu’il est encore très répandu, et restera probablement présent encore quelques années.
Que faire alors de ce mot de passe en attendant sa potentielle disparition ? Comment réduire l’impact de ce qui est aujourd’hui le principal point de friction du parcours utilisateur, tout en sécurisant mieux ses services ?
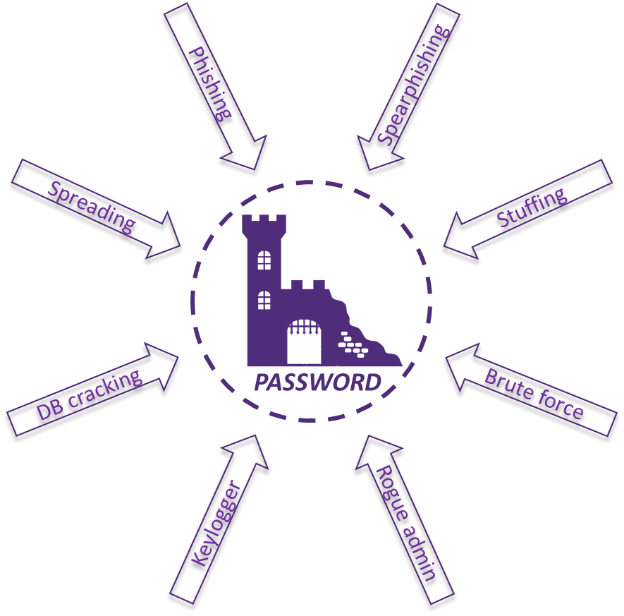
Pourquoi le mot de passe est-il si répandu ?
Les mots de passe sont utilisés depuis longtemps comme un moyen d’accès, par exemple aux clubs secrets et/ou clandestins. Ce système historique de gestion des accès « si j’ai le secret, alors j’ai le droit d’entrer » s’est transformé lors de son passage dans le monde informatique en un moyen de prouver son identité – « si j’ai le secret, alors je suis qui je dis que je suis ». L’insertion de caractères dans un certain ordre connu uniquement de l’utilisateur ayant droit d’accès, est ainsi devenue la solution pour lui permettre de prouver son identité.
Si les faiblesses de ce système se sont très vite révélées, tant que les systèmes informatiques n’étaient pas connectés et nécessitait donc un accès physique, la surface d’attaque restait limitée. Le mot de passe est donc devenu un pilier de la sécurité IT et est utilisé dans quasiment tous les services demandant une gestion de l’utilisateur.
Cependant, l’arrivée des réseaux, notamment internet, et par conséquent l’agrandissement de la surface d’exposition ont fait évoluer ces faiblesses en de réelles vulnérabilités.
Comment en est-on arrivé à mettre sur le chemin de l’utilisateur une telle complexité ?

Le nombre élevé de possibilités d’attaque sur les mots de passe ont petit à petit amené les experts de la sécurité à multiplier les mesures de protection censées sécuriser l’utilisation des mots de passe.
Ainsi, sont apparus un certain nombre de mesures autour du mot de passe et des processus associés complexifiant toujours plus les parcours utilisateurs. Par exemple:
- Nombre de caractères minimum
- Complexité (1 chiffre, une lettre, un caractère spécial, etc.)
- Liste de mots interdits
- Recommandation d’unicité du mot de passe entre les services
- Renouvellement périodique & historique
Ces règles, en grande partie issues des recommandations passées du National Institute of Standards and Technology (NIST), NIST.SP.800-63-2, 2015, et que l’on retrouvait dans la plupart des frameworks de sécurité (UK, français, etc.) impactent négativement l’expérience utilisateur. Souvent peu intuitives et différentes d’un service à l’autre, leur compréhension par l’utilisateur peut relever du défi : manque d’explication claire sur la complexité attendue, pas de compteur de tentatives erronés avant le verrouillage du compte, ou encore expérience variant en fonction du canal d’accès utilisé (l’accessibilité de certains caractères spéciaux variant grandement d’un terminal à l’autre, par exemple : le caractère « § » sur un iPhone ou un iPad).
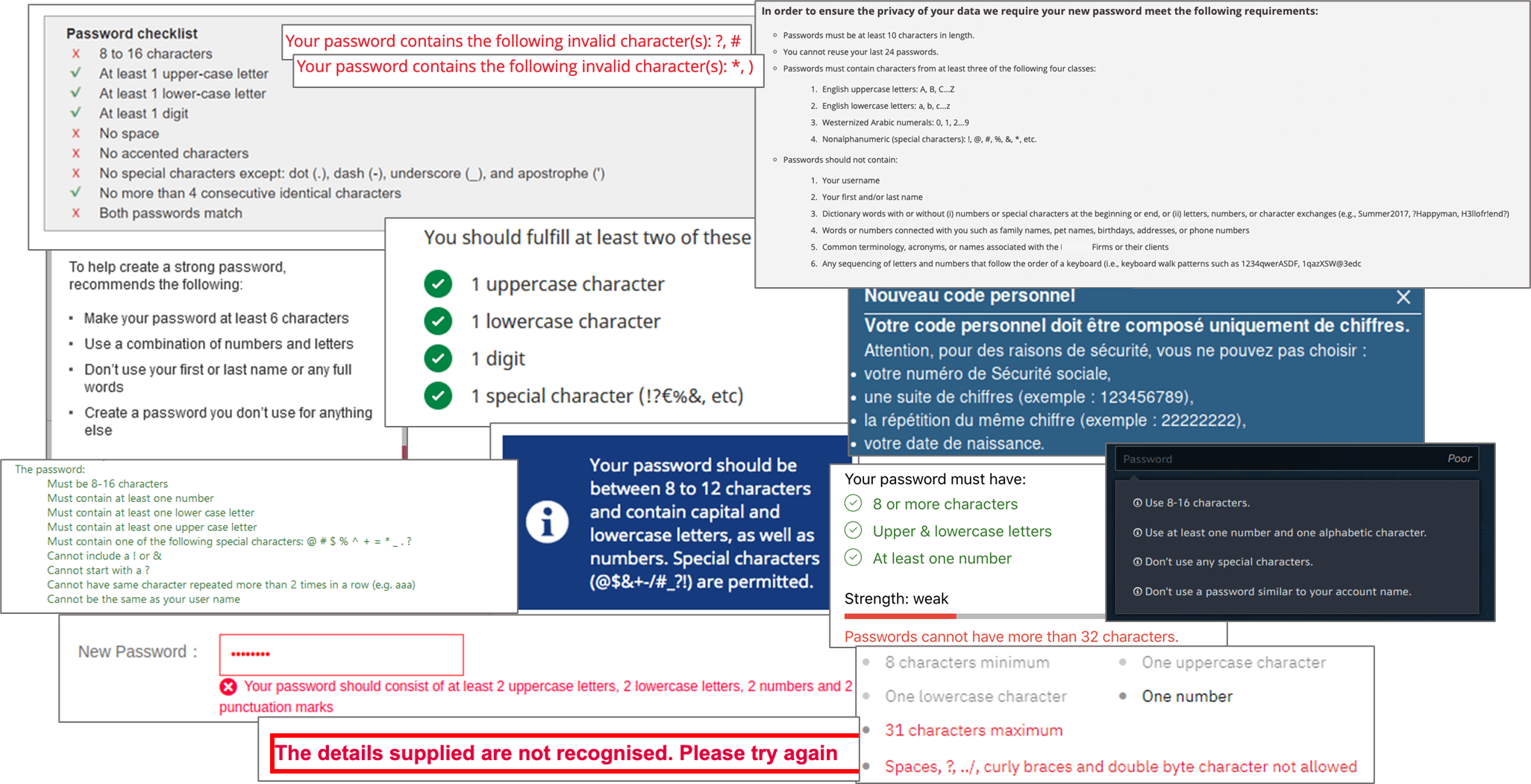
Et pour quelle efficacité ?
Malgré toutes ces mesures, le mot de passe reste largement décrié pour son faible niveau de sécurité, car il repose sur deux principes peu compatibles avec un fort niveau de sécurité.
Le principe même sur lequel le mot de passe repose, le secret partagé, entraine deux vecteurs d’attaque :
- Données en transit – transmettre le secret régulièrement : le mot de passe peut alors fuiter/être volé via un proxy trop informatif dans ses logs, une mise en cache dans la mémoire partagée d’un Smartphone, ou des malwares de type keylogger.
- Données au repos – stocker le mot de passe entreprise pour le vérifier : l’utilisation de méthodes de stockage avec des niveaux de sécurité faible reste trop répandu (chiffrement réversible au lieu de hash non-réversible, protocole ancien type sha-1, pas de salage, ou pire, stockage en clair).
Et même des protocoles de hachage plus récents restent potentiellement faillibles face aux puissances de calcul actuelles. Par exemple, même avec un protocole récent de hashage type sha256, retrouver un mot de passe de 8 caractères depuis son hash prendra… moins d’une journée.
Les attaquants peuvent ainsi récupérer directement le mot de passe faisant fi de sa complexité (si ce n’est la longueur pour le brute force et le stockage si utilisation d’un protocole de hash récent, robuste et régulièrement mise à jour).
La place prépondérante de l’humain dans le système et sa capacité à commettre des impairs – error humanum est – a un impact encore plus important :
- Nous sommes de mauvais générateurs d’aléatoire : cela explique notamment les listes de mots de passe les plus courants paraissant chaque année. De plus, les contraintes de création trop fortes, réduisant les possibilités de variations, limitent la création de mot de passe différent, baissant le niveau d’entropie. La complexité devient contre-productive.
- Nous avons mauvaise mémoire : favorisant des pratiques abaissant le niveau de sécurité (utilisation d’un dérivé voir du même mot de passe – 63% des utilisateurs admettant cette pratique – post-it sur le bureau, fichier .txt non chiffré, etc.)
- Nous sommes faciles à tromper : le phishing, le spearphishing et l’ingénierie sociale sont ainsi des vecteurs d’attaque largement répandue et toujours très efficaces.
Si l’utilisateur fournit son mot de passe à l’attaquant, il ne fait aucune importance qu’il fasse 60 caractères de long ou soit composé de lettre de différents alphabets.
La complexité du mot de passe n’a ainsi pas d’influence pour les types d’attaque les plus courants, et n’induit donc que du désagrément pour l’utilisateur.
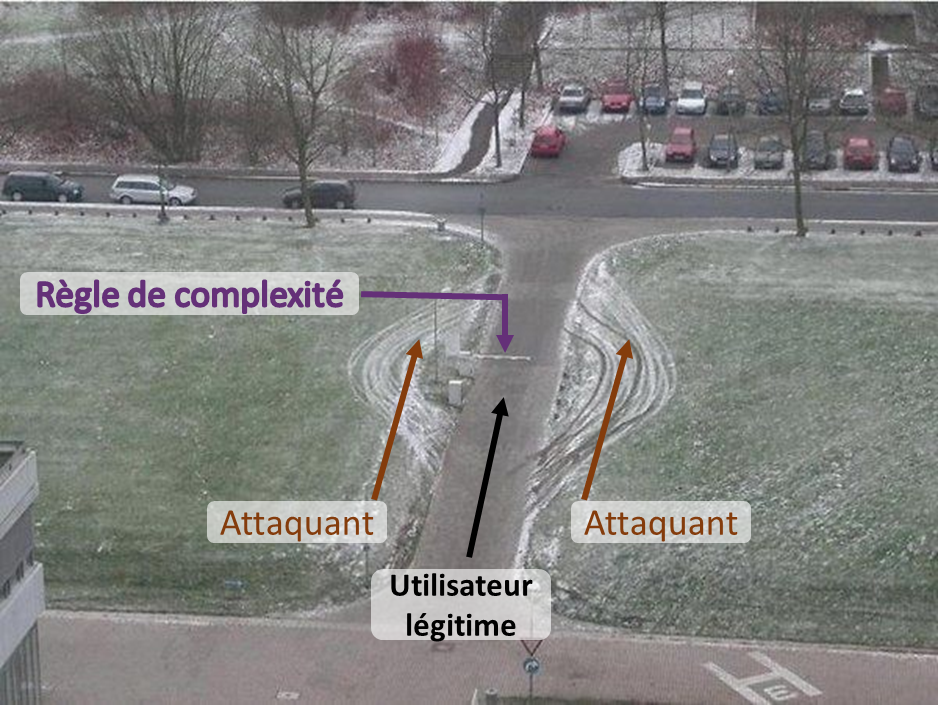
Que faire ?
Les problématiques autour des mots de passe n’étant pas récentes, il existe plusieurs solutions possibles et combinables pour réduire les problèmes et leurs impacts. La délégation de l’authentification vers des services tiers (social login, IAM d’entreprise, etc.), et la mise en place de Single Sign-On ont ainsi facilité les parcours utilisateurs et limité les rejeux / transitions du mot de passe et les endroits où le mot de passe est stocké au repos.
L’utilisation de seconds facteurs d’authentification (OTP SMS ou mail, notification push, hard tokens, etc.), les plus récents étant moins intrusifs et moins perturbateurs, est indispensable pour élever le niveau de sécurité.
En plus de ces solutions, déjà éprouvées et largement déployées, et dans l’attente d’être prêt à entrer dans le monde du passwordless qui représente un projet à part entière, le NIST et d’autres frameworks ont récemment révisé leurs recommandations concernant la complexité requise autour des mots de passe (NIST.SP.800-63b, 2017, NCSC UK, Password policy : updating your approach, 2018 par exemple).
Ainsi, d’un point de vue utilisateur, les contraintes sur les mots de passe ont été réduites à un nombre de caractères minimal (8) et la blacklist des mots de passe courant/compromis. En contrepartie, des mesures offrant plus de liberté à l’utilisateurs sont recommandés :
- Tous les caractères Unicode, incluant l’espace doivent être autorisés, sans être forcés
- La limite de taille maximale doit être au moins de 64 caractères
- Les rotations ne doivent plus se faire sur une notion de temps, mais uniquement en cas de compromission
- L’utilisateur doit avoir au moins 10 tentatives avant d’être bloqué
- Différents agréments de parcours sont à prendre en compte (information sur la complexité attendues, capacité d’afficher le mot de passe en cours de saisie, capacité de coller des valeurs)
Ces nouvelles recommandations visent à orienter les utilisateurs vers l’utilisation de mot de passe plus long et surtout plus aléatoires en réduisant les contraintes. Elles peuvent être accompagnées par la mise en place / la sensibilisation à l’utilisation de coffre-fort de mot de passe, évitant à l’utilisateur d’avoir à se souvenir de trop de mot de passe.
Les autres recommandations, indispensables pour ne pas abaisser le niveau de sécurité, affinent certains aspects précédemment évoqués. Ces mesures visent également à renforcer la transmission (chiffrement, etc.) et le stockage (hashage, salage) afin d’augmenter le niveau de sécurité des activités de l’entreprise et d’empêcher l’utilisation de certaines pratiques qui diminuent la sécurité (utilisation de questions secrètes pour la réinitialisation du mot de passe, etc.)

Conclusion
Si la disparition du mot de passe est un objectif, sa réalisation est encore loin d’être effective. Il est nécessaire, avant d’en arriver à ce Graal, de mettre en œuvre les mesures visant à la fois à sécuriser les données de l’utilisateur. Par exemple en implémentant de l’authentification multi-facteur sur les services sensibles, tout en facilitant les parcours et en encourageant l’utilisateur à se protéger lui-même. Cela passe par la mise en place d’éléments évitant à l’utilisateur de se connecter trop souvent ou de créer trop de mots de passe, mais également par une refonte de la complexité des mots de passe, afin d’augmenter la part d’aléatoire, et par une mise à niveau technique des moyens de transmissions et de stockage.
L’utilisation des processus existants pour préparer les facteurs de demain est aussi indispensable. Ainsi, refondre le parcours de récupération du mot de passe pour orienter l’utilisateur vers de l’authentification passwordless peut aider à une transition en douceur vers plus de sécurisation tout en améliorant l’expérience utilisateur.

