
Wavestone était présent lors de l’édition 2025 de Barb’hack, une conférence française dédiée à la cybersécurité qui se tient chaque année à Toulon. Vous trouverez ci-dessous quelques extraits de ce que nous avons jugé être les présentations les plus intéressantes.
Faire vivre Responder avec son temps: le potentiel caché de l’empoisonnement de résolution de noms
Conférencier : Quentin Roland
ChatGPT said:
L’astuce du repli vers WebDAV
Dans un environnement Windows typique, l’authentification SMB est omniprésente. L’empoisonnement des requêtes SMB avec des outils comme Responder permet de capturer des identifiants, mais la plupart du temps il s’agit de comptes machine ou d’authentifications qui ne peuvent pas être relayées parce que SMB applique des contrôles stricts d’intégrités. En conséquence, beaucoup d’authentifications capturées sont en pratique inutilisables pour un attaquant.
La conférence a mis en lumière un comportement souvent négligé : Windows réessaie parfois des connexions SMB échouées en se repliant vers HTTP et en utilisant le protocole WebDAV. Cela se fait via le service WebClient, installé par défaut sur la plupart des machines. L’astuce tient à la façon dont Windows interprète certains codes d’erreur. Par défaut, lorsqu’une authentification SMB échoue, le serveur renvoie le statut « STATUS_ACCESS_DENIED » et Windows s’arrête là. Mais si le serveur renvoie à la place « STATUS_LOGON_FAILURE », le système d’exploitation interprète cela comme un problème lié au protocole plutôt qu’aux identifiants. Il retente alors la connexion via le protocole WebDAV, transformant de facto une authentification SMB en une authentification HTTP.
Ce mécanisme de repli ouvre une voie surprenante pour les attaquants. Les authentifications HTTP n’exigent pas la signature par défaut, ce qui signifie qu’elles peuvent être relayées vers des services comme LDAP sans être bloquées par les protections qui rendent SMB moins exploitables. Une requête SMB empoisonnée qui serait sinon perdue devient soudainement une authentification relayée en direct pouvant servir à énumérer Active Directory, effectuer du spray de mots de passe, ou même créer de nouveaux comptes machine.
La principale limitation est que le service WebClient doit être en cours d’exécution. Bien qu’il soit installé par défaut, il n’est pas toujours actif sauf si l’utilisateur ou un processus a accédé à un partage WebDAV. Néanmoins, lorsqu’il est activé, ce repli constitue un moyen discret mais puissant de pivoter au sein d’un réseau.
Repli WebDAV + relais Kerberos : une combinaison dangereuse
La seconde partie de la présentation a exploré comment ce mécanisme de repli pouvait être étendu à Kerberos, ce qui est particulièrement pertinent dans des environnements où NTLM a été désactivé. Le relais Kerberos est en général complexe, car les tickets sont liés à des services spécifiques. Toutefois, en contrôlant la résolution de noms via LLMNR ou NBNS, un attaquant peut piéger un client et l’amener à demander un ticket Kerberos pour n’importe quel service de son choix.
Avec un empoisonnement LLMNR, l’attaquant prend le contrôle de la résolution de noms. En répondant avec un nom de service choisi — par exemple en le faisant pointer vers une instance ADCS (Active Directory Certificate Services) — la victime génère un ticket Kerberos pour ce service et l’envoie directement à l’attaquant. En utilisant krbrelayx, ce dernier peut alors relayer le ticket vers ADCS et demander un certificat. Une fois un certificat valide obtenu, il peut servir à demander un TGT, ouvrant la voie à une compromission complète du domaine.
Vient ensuite la partie ingénieuse : enchaîner les deux idées. En combinant le repli WebDAV (flag -E de Responder) avec l’astuce du relais Kerberos (flag -N de Responder), le trafic SMB peut être transformé en tentatives WebDAV via HTTP qui transportent des tickets Kerberos. Ces tickets peuvent alors être directement relayés vers ADCS. La chaîne d’attaque est étonnamment courte :
- La victime tente de se connecter à un partage SMB inexistant.
- Responder empoisonne la requête, forçant un repli WebDAV.
- Le repli s’effectue en HTTP avec une authentification Kerberos, utilisant le nom de service choisi par l’attaquant.
- Le ticket Kerberos est relayé vers ADCS avec krbrelayx.
- ADCS délivre un certificat, que l’attaquant utilise pour obtenir un TGT.
La démonstration a mis en avant exactement ce scénario : ce qui n’était au départ qu’une requête SMB anodine s’est terminé par l’obtention d’un certificat valide et la possibilité d’usurper l’identité d’utilisateurs du domaine.
Points clés
- Il faut considérer les solutions alternatives aux protocoles connus : le service WebClient de Windows peut transformer silencieusement du trafic SMB en HTTP, contournant les protections censées empêcher le relais.
- LLMNR reste dangereux : même lorsque NTLM est désactivé, les tickets Kerberos peuvent être contraints et relayés si LLMNR est actif.
- Défense : désactiver le service WebClient, bloquer ou désactiver LLMNR/NBNS, et renforcer les protections d’ADCS. Sinon, les attaquants peuvent enchaîner ces primitives pour réaliser des relays dévastateurs.
En conclusion, la présentation a montré comment les comportements de repli intégrés à Windows et les détails de certains protocoles souvent négligés peuvent transformer un trafic réseau apparemment anodin en une menace sérieuse. Des authentifications SMB qui seraient autrement ignorées peuvent être converties en requêtes HTTP pouvant être relayées, et des tickets Kerberos peuvent être redirigés vers des services sensibles pour obtenir des certificats valides. Pour les équipes Blue Team, les leçons sont claires : désactiver LLMNR et NBNS, arrêter le service WebClient sauf si nécessaire, et durcir les politiques de délivrance de certificats ADCS. Sans ces mesures, ce qui semble être un simple bruit de fond réseau peut devenir une voie d’accès menant à la compromission complète du domaine.
Lien vers l’article :
Piratage d’un ticket de métro
Conférencier : Raphael Attias (rapatt)
Cette présentation était à la fois amusante et un peu inquiétante : elle montrait à quel point il peut être facile de pirater des tickets de métro avec un Flipper Zero.
Pour ceux qui ne connaissent pas, le Flipper Zero est un outil multi-fonctions de poche capable d’interagir avec divers protocoles radio, RFID, NFC, et plus encore. Même s’il ne peut pas lire tous les types de NFC, il fonctionne avec beaucoup de cartes courantes — y compris les MiFare Ultralight utilisées dans de nombreux systèmes de métro, festivals, voire hôpitaux.
Le conférencier a commencé par expliquer l’évolution des tickets de métro : d’abord le papier perforé, puis les bandes magnétiques, et maintenant RFID/NFC. Dans la ville dans laquelle il réside, les tickets utilisent MiFare Ultralight, qui offrent entre 48 et 144 octets de mémoire et un UID de 7 octets : très petits et simples comparés aux cartes plus modernes.
Le détail clé : lors de la validation d’un ticket à une porte de métro, le système met simplement à jour un octet sur la page 3 de la carte pour le marquer comme « utilisé ». Cela signifie que si l’on peut lire et écrire dans ce secteur, il est possible de remettre le ticket à « non utilisé » et de voyager à nouveau. Le conférencier a passé neuf mois à analyser sa carte, en extrayant les données avant et après validation et en cartographiant quels octets contrôlaient quoi. Finalement, il a réussi à modifier les données pour obtenir des trajets illimités.
Mais cela ne s’est pas arrêté là. Il a même pu cloner le ticket sur son Flipper Zero, l’utiliser directement aux portillons, le montrer aux contrôleurs, et même le recharger sur les bornes officielles. Tout cela parce que le système faisait confiance aux données stockées sur la carte plutôt que de tout gérer côté serveur.
Bien sûr, cette attaque a ses limites. Elle dépend fortement du système de billetterie — toutes les villes n’utilisent pas MiFare Ultralight, et des implémentations plus avancées détecteraient ce type de manipulation. De plus, gérer des fonctionnalités comme les correspondances ou les dates d’expiration nécessite de modifier des champs supplémentaires, ce qui complique le piratage. Pourtant, dans ce cas précis, la conception faible du système rendait possible le voyage illimité.
La solution semble simple : ne conserver que l’UID sur la carte et déplacer toute la logique du ticket côté serveur. Ainsi, même si quelqu’un restaure ou clone sa carte, le système serveur saura si elle est valide ou non. Pour l’instant, la ville en question n’a pas corrigé le problème, ce qui signifie que des trajets gratuits restent techniquement possibles.
AsRepCatcher – ASRepRoast pour le VLAN utilisateur!
Conférencier : Yassine OUKESSOU
Un nouvel outil nommé AsRepCatcher a été développé par le SOC Team Leader de l’équipe ITrust. Comme l’auteur doit réaliser des audits internes réguliers, il se trouve confronté au problème suivant : comment compromettre un compte de domaine valide sans disposer des identifiants ?
Bien qu’il existe de nombreuses techniques pour obtenir un accès initial, les environnements deviennent de plus en plus sécurisés et les remédiations sont appliquées de manière croissante :
- EternalBlue / PrintNightmare / ZeroLogon : machines patchées
- LLMNR / NBT-NS / mDNS Poisoning : protocoles désactivés
- AsRep Roasting : pré-authentification activée par défaut sur tous les comptes
- Kerberoasting : SPN placés uniquement sur les comptes de service et utilisation de gMSA
- Partages réseau : lecture désactivée pour les comptes anonymes ou invités
- Brute force sur mots de passe faibles : politique de mot de passe forte
- Relais : protocoles signés
- Phishing : sensibilisation des utilisateurs
Bien que cette liste ne soit pas exhaustive, elle représente la majorité des tests réalisés par un auditeur interne.
Cependant, l’auteur a remarqué que l’accès réseau est toujours fourni à l’auditeur, généralement dans la zone réservée aux utilisateurs standard : le VLAN utilisateur. Dans ce VLAN, si un utilisateur capture le trafic, il pourra observer des paquets liés à l’authentification, en particulier avec les protocoles NTLM ou Kerberos.
Il se trouve qu’avec le protocole Kerberos, une dérivée du mot de passe de l’utilisateur est utilisée (appelée hash) pour créer la requête KRB_AS_REP (dans la clé de session).
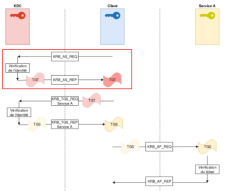
Ainsi, un attaquant capable de récupérer cette requête pourrait ensuite tenter de casser le mot de passe de l’utilisateur. C’est exactement ce que tente de faire l’outil AsRepCatcher (d’où son nom).
Pour récupérer la requête KRB_AS_REP, l’outil utilise une technique bien connue appelée ARP Spoofing :
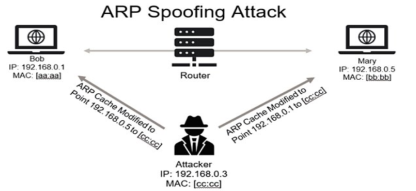
Un article de Veracode explique ce qu’est l’ARP Spoofing et comment s’en protéger : https://www.veracode.com/security/arp-spoofing/
AsRepCatcher modifie la table ARP des utilisateurs légitimes du VLAN, qui enverront désormais leurs requêtes KRB_AS_REQ vers l’attaquant. Ce dernier peut les modifier à la volée en changeant l’adresse IP source par la sienne et en ajustant également les algorithmes de chiffrement utilisés pour créer le hash.
Cette information est cruciale car elle permet à l’attaquant de récupérer des hashes chiffrés avec un algorithme faible (dans ce cas RC4, si le KDC autorise son utilisation), ce qui facilite grandement le craquage de mots de passe (quelques secondes avec RC4 contre plusieurs jours avec AES).
L’outil propose également des fonctionnalités pour rester plus discret sur le réseau, comme l’option --disable-spoofing permettant de réinitialiser les tables ARP des utilisateurs dont le hash a déjà été capturé.
Pour se protéger contre cet outil, il est donc recommandé de mettre en place des remédiations contre l’ARP Spoofing et de ne pas autoriser l’algorithme de chiffrement RC4 sur le domaine.
Lien vers l’outil : https://github.com/Yaxxine7/ASRepCatcher
OSINT : comment la police nationale piste les personnes recherchées ?
Conférencier : Nidhal BEN ALOUI
Chaque année, 580 000 personnes sont inscrites dans le Fichier des Personnes Recherchées. Chaque dossier contient des informations sur l’identité de la personne (nom, prénom, âge, etc.), une photographie, le motif de la recherche et les mesures à prendre si l’individu est retrouvé.
![]()
- AL : personnes atteintes de troubles mentaux
- IT : interdites de territoire
- M : mineurs en fuite
- PJ : recherches de la police judiciaire
- R : opposition à la résidence en France
- S : sécurité de l’État
- T : débiteurs du Trésor
- V : évadés
- X : personnes disparues
- etc.
La gendarmerie française est souvent sollicitée pour rechercher les personnes figurant sur cette liste dans le cadre d’enquêtes. Pour les retrouver, elle utilise une combinaison de renseignements en source ouverte (OSINT) et de renseignements en source fermée.
Pour la partie OSINT, l’utilisation des réseaux sociaux, d’outils et de sites web publics est largement privilégiée. Une attention particulière est portée aux résultats fournis par ces outils publics, qui ne sont jamais considérés comme sûrs par la gendarmerie.
En ce qui concerne les sources fermées, la gendarmerie dispose d’outils internes, de bases de données et de registres nationaux partagés qu’elle peut consulter lors des enquêtes.
Il est également possible pour les officiers de police judiciaire (OPJ) de demander l’accès à des informations privées détenues par des entreprises via des « demandes dérogatoires », ou même de communiquer en ligne avec de potentiels suspects dans le cadre d’une « enquête sous pseudonyme ».
Cependant, la loi encadre très précisément les actions autorisées par la gendarmerie, généralement :
- Les demandes dérogatoires ne sont autorisées que dans le cadre d’enquêtes pénales.
- Les enquêtes menées sous pseudonyme nécessitent une certification du Commandement de la Cyberdéfense (ComCyber).
- Chaque pseudonyme et avatar utilisé dans le cadre d’une enquête sous pseudonyme est unique et enregistré dans une liste accessible à tous les officiers de police judiciaire, afin d’éviter qu’ils s’enquêtent mutuellement.
- Il est interdit d’inciter quelqu’un à commettre un délit (par exemple, demander à un suspect potentiel d’acheter des biens illégaux).
Purple Team: méthodologie et outillage
Conférencier: Mael Auzias
Cette présentation, réalisée par Naval Group, abordait la problématique de la création d’une méthodologie et d’outils permettant de mettre en œuvre des Purple Teams et de les intégrer dans un plan d’audit plus large, afin de suivre l’évolution du niveau de sécurité et de comparer différents périmètres audités.
En effet, dans le cadre des missions d’une équipe d’audit interne, il est essentiel de disposer de référentiels d’audit définis afin de mener correctement les évaluations et de comparer leurs résultats.
Pour cela, un membre de la Red Team a collaboré avec la Blue Team de Naval Group afin de définir un cadre spécifique de tests et de restitution des résultats, qui sera utilisé pour évaluer les capacités de détection et de réponse de chaque entité auditée.
Présentation Purple Team
Une Purple Team est un exercice au cours duquel la Red Team et la Blue Team collaborent étroitement, en partageant librement les actions malveillantes exécutées ainsi que les détections réalisées. L’objectif final est d’améliorer à la fois les capacités de détection et les réponses apportées.
Pour bien préparer un exercice Purple Team, il est donc essentiel de définir :
- Quel type de profil d’attaquant doit être simulé ?
- Quels TTPs (Techniques, Tactiques et Procédures) seront ciblées pendant l’exercice ?
- Quels sont les objectifs de la mission ?
- Quelles sont les détections et réponses attendues ?
Une fois ces éléments clarifiés, l’exercice Purple Team peut débuter.
Méthodologie et outils dédiés aux exercices internes de Purple Team
Phase de test
Tout d’abord, la méthodologie mise en place par Naval Group repose sur VECTR, un outil destiné à automatiser les tests et mesurer l’efficacité de la détection, en offrant un espace de collaboration entre les Red et Blue Teams. Dans ce cas précis, il n’est utilisé que comme interface pour lancer automatiquement des attaques spécifiques et collecter les résultats des réponses.
Système de notation
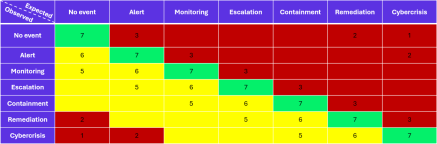
Quatre situations peuvent être identifiées :
- Si une détection observée correspond à celle attendue, l’action malveillante testée obtient la note la plus élevée (ici, 7).
- Si une détection observée est « inférieure » à celle attendue, elle reçoit une mauvaise note (entre 1 et 3 ici).
- Si une détection observée est légèrement supérieure (par exemple, le déclenchement d’une enquête d’incident plutôt qu’un simple événement), elle obtient une note plutôt élevée (entre 5 et 6 ici).
- Enfin, si une réaction observée est disproportionnée par rapport à celle attendue, elle reçoit une note faible : déclencher une crise cyber globale pour une action qui n’aurait pas dû générer d’alerte peut s’avérer très impactant pour le quotidien du système d’information.
PS : ici, les différentes catégories ne correspondent pas exactement à celles présentées lors de l’événement.
Note finale
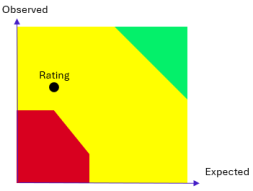
Cette note finale permet de déduire les performances de la Blue Team, mais également de suivre l’évolution de cet indicateur dans le temps.
Conclusion
Ainsi, en définissant un cadre d’audit clair pour réaliser les exercices de Purple Team, Naval Group s’assure de pouvoir évaluer correctement les performances des détections effectuées dans les différents périmètres de l’entreprise, de les comparer et de suivre leur évolution dans le temps.
Cela s’avérera d’autant plus efficace que le nombre d’exercices de Purple Team sera élevé.
Logiciels peu populaires : comment les attaquants dupent les chercheurs
Confériencier : Georgy Kucherin
Le conférencier, un chercheur en vulnérabilités chez Kaspersky, présente une étude de cas rencontrée lors d’une mission réelle.
En tant qu’analyste réseau pour un client, le chercheur a été interpellé par un résultat collecté dans le SIEM.
Le domaine eventuallogic.com est récupéré et analysé sur la célèbre plateforme VirusTotal, avec un score de 1/97 (c’est-à-dire qu’un seul antivirus considère le domaine comme suspect ou dangereux, contre 96 qui le jugent sûr).
Face à ce résultat, beaucoup se seraient arrêtés là, mais Georgy a poursuivi son investigation par curiosité.
En visitant le site web, il constate que la société propose un logiciel de compression de fichiers. Georgy le télécharge dans une machine virtuelle et le teste. L’outil fonctionne correctement malgré la présence récurrente de publicités.
À ce stade, de nombreux chercheurs auraient classé le logiciel comme PUA (Potentially Unwanted Application), c’est-à-dire application potentiellement indésirable, signifiant que le logiciel n’est pas souhaité sur un poste professionnel (principalement à cause des publicités), mais n’est pas considéré comme dangereux. Cependant, seul le département informatique peut décider d’interdire ce type de logiciel ; il n’appartient pas aux analystes du SOC (Security Operations Center) de trancher, sauf en cas de preuves d’activité malveillante liée au logiciel.
Georgy décide de prendre le temps d’analyser le logiciel plus en profondeur, en commençant par une sandbox en ligne : joesandbox.com.
La sandbox exécute le logiciel dans un environnement contrôlé et l’analyse. Cette fois, le résultat est 56/100, indiquant que le logiciel a échoué à certains tests.
Un fichier nommé decrypt.exe est trouvé dans la mémoire de l’ordinateur pendant l’exécution du logiciel. Ce fichier est récupéré par Georgy et analysé sur VirusTotal, avec un score de 5/97. Toujours peu élevé, mais dans l’onglet des relations, un autre domaine apparaît : decryptables.com.
En répétant cette méthode plusieurs fois, Georgy remonte le fichier jusqu’à un autre domaine proposant un logiciel de compression : Let’s Compress.
Le logiciel est de nouveau analysé sur joesandbox, et cette fois Georgy découvre que le logiciel de compression exécute un fichier Python compilé avec PyInstaller.
Georgy a ensuite réalisé les analyses suivantes :
- Extraire le contenu avec pyinstxtractor
- Convertir le fichier main.pyc en script Python lisible
- Déobfusquer le script .py obtenu
- Déchiffrer un fichier .json créé par le script
- Identifier un appel à une infrastructure de Command & Control (C2) dans ce fichier .json
Ces investigations réalisées, le chercheur tient la preuve que le fichier est malveillant.
Il a ensuite suffi de suivre le chemin en sens inverse afin de vérifier le lien entre le fichier malveillant et le domaine de base détecté.
L’objectif de tout cela est de montrer que les acteurs malveillants mettent en place de nombreuses couches pour tromper les chercheurs, et que même un score faible sur un outil largement reconnu comme VirusTotal n’est pas suffisant pour juger de la fiabilité d’un binaire ou d’un domaine.
Analyse de binaires Linux malveillants avec r2ai
Conférencière : Axelle Apvrille
À une époque où l’IA et la cybersécurité travaillent plus que jamais de concert, il était impossible de ne pas aborder ce type de sujet. Lors de cette présentation, Axelle a présenté r2ai, un nouveau plugin pour radare2, le célèbre framework de reverse engineering. L’idée est simple mais puissante : combiner les capacités de désassemblage de radare2 avec un Large Language Model (LLM) afin de traduire l’assembleur brut en un code source plus intelligible.
La conférence a illustré le potentiel de l’outil à travers l’analyse de deux échantillons de malwares réels, mettant en évidence à la fois ses forces et ses limites.
Étude de cas #1 : Un shellcode petit mais astucieux
Le premier échantillon était un shellcode ELF léger de 4 Ko, rempli d’astuces pour complexifier l’analyse statique. La recherche de chaînes dans la section .data n’a rien donné d’intéressant, et même Ghidra n’a fourni guère plus qu’une instruction swi cryptique.
Avec r2ai, cependant, les résultats furent différents : le désassemblage est devenu beaucoup plus lisible. Le modèle a mis en évidence la création de sockets et une routine connect-back suspecte. Mais un avertissement important est à noter : les LLM peuvent « halluciner ». Par exemple, le modèle a initialement suggéré une connexion vers 127.0.0.1:4444, ce qui s’est révélé incorrect après un examen plus approfondi de l’assembleur réel.
Pour autant, le plugin a correctement souligné un autre comportement clé : un appel à mprotect modifiant les permissions de la pile en RWX, un indicateur typique d’un stager se préparant à récupérer et exécuter une charge utile depuis un serveur C2.
Dans ce premier cas, r2ai a montré comment il pouvait accélérer la découverte de la logique à haut niveau, tandis que les analystes humains restaient essentiels pour valider et corriger son interprétation.
Étude de cas #2 : Ransomware Trigona sur Linux
Le second échantillon était Trigona, une famille de ransomware généralement observée dans des environnements Windows, mais avec une variante Linux inattendue datant de mai 2023. Fait intéressant, le code avait été écrit en Delphi — un choix surprenant qui a intrigué de nombreux participants.
Bien que Trigona soit supposé inactif, des échantillons circulaient encore en avril 2025, rendant l’analyse particulièrement pertinente.
Ici, r2ai a nécessité un ajustement supplémentaire (augmentation du nombre maximum de tokens dans le contexte du modèle) pour compenser la taille du binaire, mais il a révélé des comportements cruciaux :
- Arrêt de machines virtuelles pour maximiser la perturbation,
- Localisation et chiffrement de documents,
- Exfiltration de données avant chiffrement.
Les chercheurs ont souligné la rapidité avec laquelle ils ont pu cartographier toute la kill chain, comparé aux flux de travail traditionnels dans IDA Pro ou Ghidra.
Limites et leçons tirées de l’analyse
La présentation s’est terminée par une discussion sur les limites de r2ai :
- Contraintes de tokens : les analyses longues peuvent provoquer des plantages ou devenir coûteuses,
- Précision : bien que les LLM puissent expliquer les appels systèmes et le flux de contrôle, ils inventent parfois des valeurs ou une logique que les analystes doivent vérifier,
- Usage complémentaire : r2ai ne remplace pas les outils standards, mais les complète, en accélérant la formulation d’hypothèses.
Peut-on scanner le réseau sans adresse IP ?
Conférenciers : Julien M. & Francis H.
Cette présentation, donnée par Naval Group, a présenté une méthode de scan réseau sans révéler son adresse IP, en combinant le fonctionnement de deux protocoles de base. Deux employés étaient sur scène, un de la Red Team et un de la Blue Team.
Fondamentaux protocolaires
ARP
ARP est un protocole dédié à la découverte des équipements présents sur un réseau, en associant une adresse MAC à une adresse IP.
Pour réaliser cette étape de découverte, des requêtes broadcast sont envoyées afin de demander l’adresse MAC correspondant à une adresse IP de destination spécifique, si celle-ci n’est pas connue par l’équipement réseau (par exemple, un routeur).
TCP
TCP est un protocole de communication garantissant la livraison fiable, ordonnée et vérifiée des données. Il repose sur l’envoi de requêtes SYN par une source vers une destination. Différentes réponses peuvent être attendues selon l’accessibilité du port de destination :
- Port filtré : aucune réponse n’est renvoyée, car le paquet SYN n’atteint pas la destination.
- Port fermé : un paquet RST est renvoyé à la source.
- Port ouvert : un paquet SYN+ACK est renvoyé.
Un autre cas peut être distingué : si le port est ouvert mais que la source disparaît du réseau (par exemple après une coupure), le paquet SYN+ACK est renvoyé plusieurs fois (par exemple 5 fois pour certains équipements) par la destination afin de poursuivre l’échange TCP.
Aller plus loin avec TCP & ARP
Ainsi, une nouvelle méthodologie de scan émerge de la combinaison du fonctionnement d’ARP et de TCP.
L’objectif est de fabriquer un paquet SYN spécifique, en falsifiant l’adresse source pour choisir une adresse IP qui n’est pas actuellement utilisée sur le réseau, et de l’envoyer à la victime sur le port choisi. Selon la réponse de la destination, et puisque l’adresse IP source est inconnue du routeur, ce dernier enverra des requêtes ARP broadcast pour localiser la source. De plus, le nombre de requêtes ARP dépendra de l’état du port :
- Port filtré : aucune réponse n’est renvoyée par la destination, donc aucune requête ARP broadcast.
- Port fermé : un paquet RST est envoyé par la destination à la source inconnue, donc une requête ARP broadcast.
- Port ouvert : plusieurs paquets SYN+ACK sont envoyés, car aucun paquet ACK ne sera renvoyé par la source inconnue, donc plusieurs requêtes ARP broadcast.
L’attaquant n’aura alors qu’à surveiller le nombre de requêtes ARP broadcast liées à l’IP inconnue usurpée pour déduire l’état du port scanné.
Cependant, certaines limites existent : par exemple, le fait que le nombre de paquets SYN+ACK varie peut induire des faux positifs et rendre plus difficile le développement d’outils fiables.
Qu’en dit le SOC ?
Suite à la présentation de cette technique, le membre de la Blue Team a expliqué le point de vue du SOC la concernant.
Tout d’abord, il est important de préciser que bien que cette technique de scan soit assez difficile à détecter dans des scénarios réels, elle représente une des nombreuses méthodes possibles pour scanner un réseau, et constitue donc une fraction minime des scénarios de scan (au regard de la matrice MITRE ATT&CK) qu’un SOC doit couvrir.
De plus, ce scénario de scan ne se produit que lorsqu’une intrusion sur le réseau a déjà eu lieu, et ne constitue pas la fin de la kill chain. La Blue Team dispose de plusieurs autres mécanismes de défense pour stopper les attaques, que ce soit en amont ou en aval de cette action malveillante.
Conclusion
Ainsi, même si cette méthode de scan est assez ingénieuse, les équipes Blue Team ne sont pas forcément contraintes de la prendre en compte et de passer du temps à résoudre le problème. Cette conclusion peut même être généralisée à d’autres découvertes futures : une Blue Team doit choisir ses combats, en fonction de la criticité des techniques d’attaque et des ressources humaines disponibles.
Deux rapports, deux réalités : ce qu’on nous dit et ce qu’on nous cache
Conférencier : Koreth
Cette présentation portait sur un problème que tout le monde connaît trop bien : nous sommes ensevelis sous les alertes, notifications et rapports, alors que les plus importants sont souvent les premiers à passer inaperçus.
Silent Ghost a commencé par quelques exemples bien connus. Prenons la faille Target : 70 millions de cartes de crédit ont été compromises, et l’alerte était là, mais elle ressemblait trop à du spam, donc personne n’a agi. Même histoire à Rouen (2019), où un email de phishing a déposé un malware se propageant latéralement sur le réseau. L’alerte initiale a été signalée, mais ignorée. Colonial Pipeline en 2021 ? Là encore, une notification existait — mais personne n’y a prêté attention.
Et ce n’est pas un problème nouveau. En 2016, la NSA a subi un vol de données sensibles parce qu’un employé a simplement utilisé une clé USB pour les exfiltrer. SolarWinds en 2019 a montré le danger d’une pipeline CI/CD compromise, pourtant très peu de personnes ont remarqué les signes précoces. Plus récemment, Kiabi (2024) a subi une fraude de 100 millions d’euros par un comptable interne — les signaux d’alerte étaient là, mais noyés dans le bruit.
Le problème structurel est clair : seulement 0,13 % des pull requests sont étiquetées « security », alors qu’en réalité près de 15 % impliquent la sécurité. Cet écart signifie que de vraies vulnérabilités restent visibles mais ignorées. Silent Ghost a souligné un CVE qui a nécessité plus de 100 correctifs non documentés avant d’être officiellement reconnu.
Les programmes de bug bounty subissent le même sort. Lorsqu’il gèrait des programmes privés chez YesWeHack, il constatait que les boîtes mail sont saturées de rapports exagérés ou mal rédigés : des emails décrivant des vulnérabilités « CVSS 10 » qui ne sont en réalité que des en-têtes mal configurés ou une clé API Google Maps exposée. Le volume de ce bruit risque d’enterrer les quelques découvertes vraiment critiques.
La conclusion est claire : en tant qu’industrie, nous devons travailler sur la réduction du bruit. Moins de notifications inutiles, un meilleur tri et des standards de reporting plus clairs aideraient à faire passer les alertes importantes. Sinon, la prochaine alerte majeure sera ignorée, tout comme la précédente.
OASIS – Ollama Automated Security Intelligence Scanner
Conférencier : psyray (Raynald Coupé)
Une autre présentation sur l’utilisation de l’IA en cybersécurité portait sur OASIS, un framework open source conçu pour effectuer des revues de code avec l’aide de modèles d’IA, en mettant l’accent sur la confidentialité.
Son créateur a développé l’outil par nécessité : les solutions d’IA traditionnelles basées sur le SaaS posent problème lorsqu’il s’agit de travailler sur du code client sensible, rendant un déploiement local indispensable.
Comme son nom l’indique, OASIS s’appuie sur Ollama, un système léger permettant aux développeurs d’exécuter des modèles de langage de grande taille sur leur propre infrastructure. Le résultat est une solution pratique pour des audits de code sécurisés, évolutifs et personnalisables.
Architecture et fonctionnement
Sur le plan technique, **OASIS repose sur un système d’embedding sémantique : le code source est transformé en vecteurs, permettant une analyse contextuelle dépassant le simple pattern matching. Cette base permet à l’IA de repérer les vulnérabilités d’une manière proche du raisonnement humain. L’outil propose plusieurs modes de fonctionnement :
- Mode Audit : un scan rapide pour identifier les zones à haut risque dans de grandes bases de code. En ajustant les seuils, les analystes peuvent minimiser les faux positifs tout en obtenant un aperçu global efficace.
- Scan Standard (deux phases) :
- Un modèle léger met en évidence le code potentiellement suspect,
- Un modèle plus puissant effectue une analyse approfondie des sections signalées. Idéal pour les projets volumineux avec des profils de risque cohérents.
- Scan Adaptatif (multi-niveaux) :
- Un scan statique avec patterns et regex (rapide et sans IA),
- Un modèle léger pour détecter les problèmes de surface,
- Une analyse contextuelle avec scoring de risque,
- Une revue approfondie avec un modèle lourd.
Cette approche échelonnée garantit flexibilité, allant d’un audit rapide à une analyse complète et détaillée.
Couverture des vulnérabilités
OASIS est conçu pour détecter un large éventail de problèmes, notamment :
- Vulnérabilités web : XSS, XXE, CSRF,
- Failles d’authentification,
- Exposition de données sensibles,
- Erreurs de configuration, comme le path traversal ou des suites cryptographiques faibles.
Le framework supporte plusieurs langages de programmation et peut même générer des requêtes Burp Suite pour valider les résultats.
Rapport et résultats
Au-delà de la détection, OASIS génère des rapports structurés au format PDF, Markdown ou HTML, documentant :
- La chaîne d’attaque complète pour chaque vulnérabilité (point d’entrée, chemin d’exploitation, impact potentiel),
- Des recommandations de remédiation, aidant les développeurs à corriger rapidement les problèmes.
Ces rapports sont donc utilisables à la fois par les équipes techniques et par les managers ayant besoin d’une vision plus globale du risque projet.
Enseignements tirés d’une intrusion cyber en milieu industriel
Conférenciers : Hack’im et Antxine
Cette présentation a été donnée par deux intervenants à propos d’un retour d’expérience post-incident.
En effet, l’un de leurs clients les a contactés après avoir branché une clé USB sur un poste de travail standard, déclenchant une alerte de l’EDR. La situation était suspicieuse, car cette clé USB n’avait jamais généré d’alerte auparavant, et elle était uniquement utilisée pour mettre à jour un serveur autonome, séparé du reste du réseau.
Démarrage de l’investigation
L’attention s’est donc portée sur le serveur, probablement infecté par un programme malveillant qui s’était propagé à la clé USB.
En utilisant des outils classiques pour récupérer les 900 Go du serveur et analyser le système de fichiers et les fichiers EVTX, les enquêteurs ont découvert un programme suspect caché dans le dossier %APPDATA%, nommé aL4N.exe. Un exécutable inconnu dans ce dossier est anormal, ce qui a attiré l’attention des enquêteurs.
aL4N.exe
En utilisant VirusTotal pour évaluer le niveau de dangerosité de l’exécutable, celui-ci a obtenu un indice de détection de 52/94, ce qui était préoccupant et a poussé les enquêteurs à poursuivre leur analyse dans cette direction.
Grâce à cette piste, ils ont découvert que ce malware était présent sur le serveur depuis sa masterisation en 2016, et avait été introduit via une clé USB.
Des traces d’investigations internes précédentes ont été retrouvées, notamment un fichier mentionnant la présence de aL4N.exe identifié par des employés.
Écrit en AutoIT, ce malware établit un tunnel de communication vers un serveur C2 (Command & Control). Cependant, dans ce cas précis, le serveur distant avait été configuré sur localhost, ce qui révèle un manque de connaissances de l’acteur malveillant.
Le système de réplication de ce malware est atypique. Dès qu’un stockage externe de plus de 1 Go est connecté à une cible infectée, aL4N.exe crée un dossier My Pictures, le cache, s’y copie lui-même, et crée un raccourci pour My Pictures qui exécute aL4N.exe lorsqu’on clique dessus.
Conclusion
Le principal enseignement de cette présentation est d’installer des mécanismes de détection sur tous les composants d’un SI, même s’ils sont séparés du réseau principal. Il est également possible de mettre en place des stations de détection et de nettoyage efficaces pour les clés USB afin de sanitiser les supports amovibles, même si, dans le cas de cette entreprise, les dispositifs existants n’avaient pas détecté aL4N.exe.

