
L’essor de l’IA générative et des Large Language Models (LLM) comme ChatGPT ont bouleversé les usages numériques. De plus en plus d’entreprises choisissent de déployer des applications intégrant ces modèles de langage, mais cette intégration s’accompagne de nouveaux risques de sécurité (recensés par le top 10 LLM de l’OWASP). Pour faire face à ces nouveaux risques et à l’évolution règlementaire (AI Act), des solutions de filtrage spécialisées, nommées guardrails, ont émergé pour sécuriser les interactions avec les LLM et deviennent incontournable pour assurer la sécurité et la conformité de ces applications.
Objectifs
Face à la multiplication des solutions de filtrage pour les modèles de langage (LLM) ainsi que des modèles de langages en eux-mêmes, notre travail a consisté à comparer ces différentes solutions afin d’identifier les plus pertinentes pour répondre aux enjeux de sécurité et d’intégration selon les différents cas d’usage dont une organisation peut faire face.
Méthodologie
Afin d’évaluer ces solutions, plusieurs critères ont été retenus :
- D’abord, l’efficacité du filtrage portant à la fois sur la capacité à détecter les prompts malveillants et sur la proportion de faux positifs, pour éviter que le filtrage ne détériore l’expérience des utilisateurs finaux.
- Ensuite, la latence engendrée par cette analyse, pour s’assurer que ces solutions puissent être utiliser en production sans ralentir les temps de réponses du modèle.
- Enfin, la capacité de personnalisation de ces filtres, pour s’adapter aux différents cas d’usage souhaités par les organisations.
Pour réaliser l’évaluation, deux séries de tests ont été réalisés : d’abord, pour évaluer l’efficacité du filtrage, un dataset de prompts a été soumis à chaque solution contenant à la fois des prompts malveillants et des prompts légitimes, et ensuite au travers d’un outils de tests automatiques de « Red Teaming IA » permettant d’évaluer la robustesse de ces éléments de filtrage face à des prompt injections et des tentatives d’exploitation classiques.
Implémentation Technique
Afin de tester les différentes solutions, nous avons implémenté un environnement de tests consistant en un pipeline d’évaluation de prompts, séparé en plusieurs étapes :
- Le prompt passe au travers du premier filtre, permettant d’analyser les prompts de l’utilisateur avant de les transmettre au modèle, qui génèrera la réponse.
- Une fois la réponse générée, elle est évaluée par un filtre de sortie pour s’assurer qu’elle ne comporte pas de contenu indésirable avant d’être renvoyée à l’utilisateur.
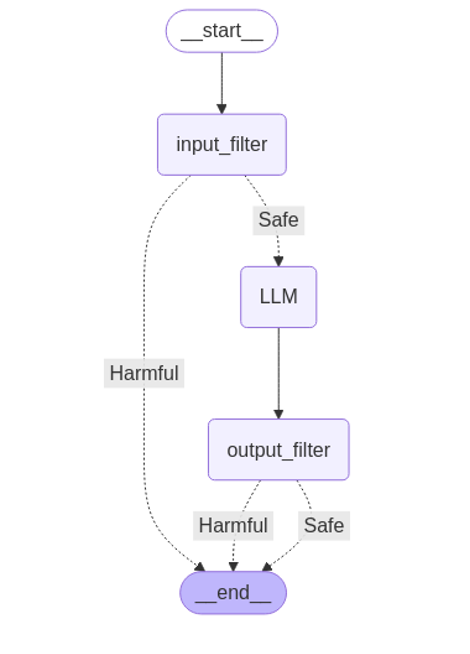
Cet environnement de tests a été développé en Python, en s’appuyant sur des frameworks et services classiques pour les systèmes d’IA génératives :
- LangChain & LangGraph pour l’orchestration et l’abstraction des interactions avec les modèles,
- Groq Cloud pour l’environnement d’exécution du LLM (le modèle utilisé était gemma2-9b-it).
- Le jeu de données de prompts malveillants utilisé est publiquement disponible sur HuggingFace et contient des prompts malveillants (33%) et légitimes (66%), dont certains contiennent des questions volontairement floues, afin de tester les limites des filtres.
- Promptfoo, pour l’évaluation automatique des solutions face à des attaques classiques contre les systèmes d’IA.
Solutions évaluées
Parmi les nombreuses solutions identifiées au moment de l’étude, neuf ont été sélectionnées, séparées en plusieurs catégories : les guardrails proposées par les fournisseurs Cloud (AWS Bedrock Guardrails, Azure Content Safety, GCP Model Armor), les solutions open source telles que Llamaguard, et les filtres proposés par des start-ups spécialisées dans la sécurité de l’IA, telles que Lakera Guard.
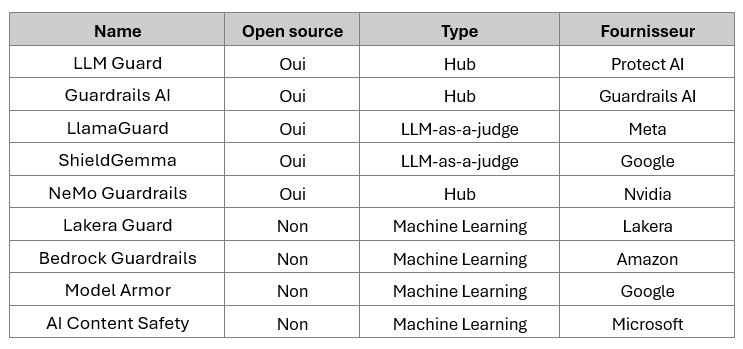
Pour permettre d’évaluer les solutions sur une même base, chacune a été utilisée dans sa configuration par défaut, sans personnalisation des règles de filtrage.
Premiers Résultats
Pour comparer les résultats de classification, le F1-Score a été choisi, afin de prendre en compte efficacement la proportion de faux positifs et faux négatif :

Avec :
- Vrais positifs (TP) pour les prompts malveillants classifiés comme dangereux.
- Faux positifs (FP) pour les prompts légitimes considérés comme dangereux par le filtre.
- Vrai négatifs (TN) pour les prompts légitimes considérés comme tels.
- Faux négatifs (FN) pour les prompts malveillants considérés comme légitimes.
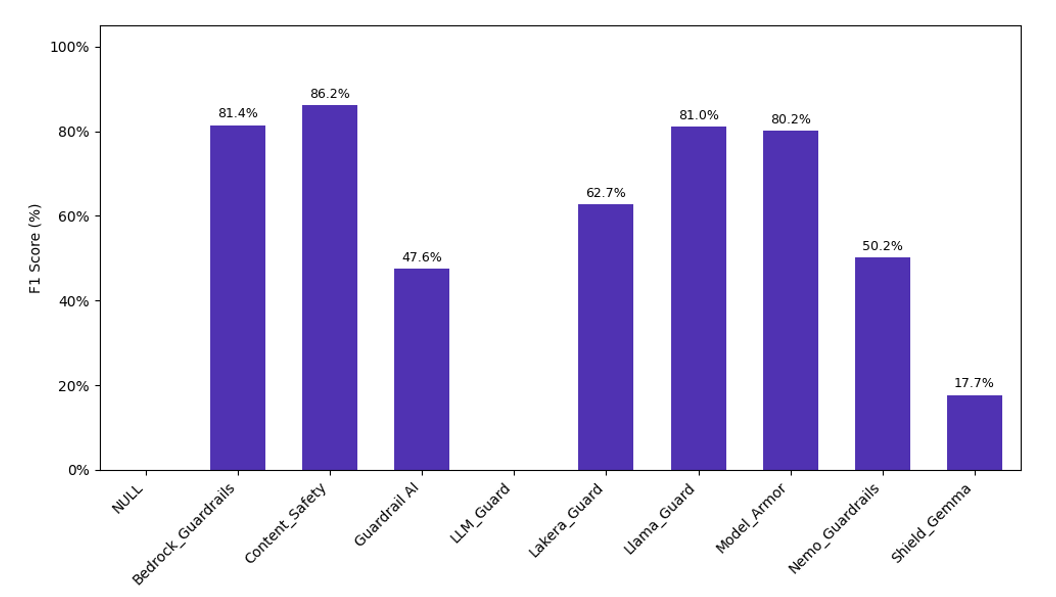
A partir de cette première évaluation, quelques résultats importants peuvent être identifiés. D’abord, chacune des trois solutions intégrées aux offres des fournisseurs cloud ont obtenu des bons résultats sur nos tests (>80%), alors que certains filtres tels que Guardrails AI et NeMo Guardrails souffrent de mauvais scores du fait de leur sévérité, en marquant tous les prompts comme malveillant et d’autres, comme LLM Guard ont au contraire considéré tous les prompts comme légitimes.
Cependant, selon le cas d’usage, le choix de la bonne solution n’est pas aussi simple :
- Dans les cas où le confort des utilisateurs est le plus important, il est intéressant de considérer Azure Content Safety, qui a obtenu le moins de faux positifs.
- En revanche, pour les applications plus critiques, pour lesquels le maximum de prompts malveillants doit être bloqués, Bedrock Guardrails est une meilleure option.
Focus sur les guardrails des fournisseur Cloud
Pour approfondir cette analyse, nous nous sommes penchés plus en détails sur les solutions proposées par les fournisseurs Cloud, puisqu’ils affichent les performances les plus élevées et sont les plus utilisés.
Cette seconde évaluation repose sur Promptfoo, un outil automatique de tests de sécurité offensive spécialisé pour les systèmes d’IA, permettant d’évaluer la robustesse des guardrails face à diverses techniques de prompt injection et jailbreak, en se concentrant sur la génération de contenu malveillant et la fuite de données personnelles.
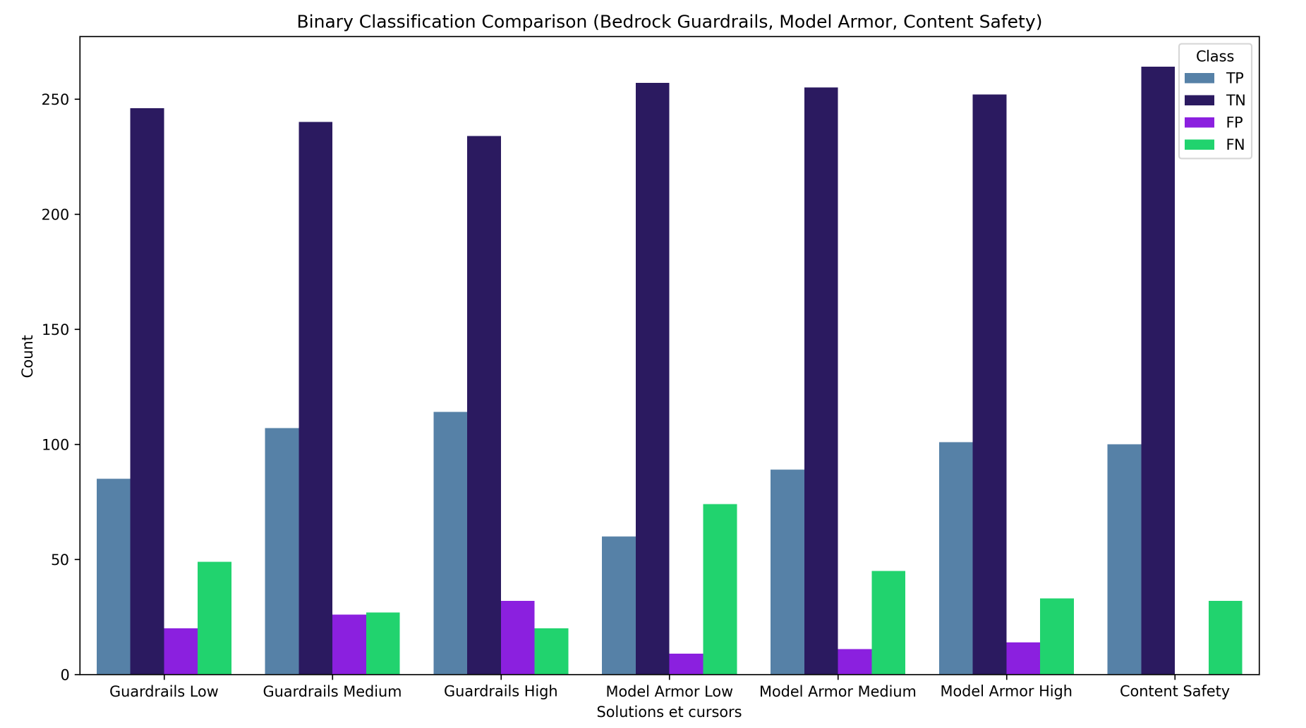
A partir de cette série de tests, nous avons observé que les trois filtres sélectionnés permettent de bloquer la majorité des attaques, et obtiennent des performances équivalentes :

Configuration du niveau de sensibilité
La configuration de GCP Model Armor et AWS Bedrock Guardrails permet de fixer un niveau de sensibilité aux filtres appliqués, afin d’adapter la détection au niveau requis par le cas d’usage.
Nous avons testé chacun de ces niveaux pour Model Armor et Bedrock Guardrails afin de mesurer leur impact sur les vulnérabilités identifiées par Promptfoo.
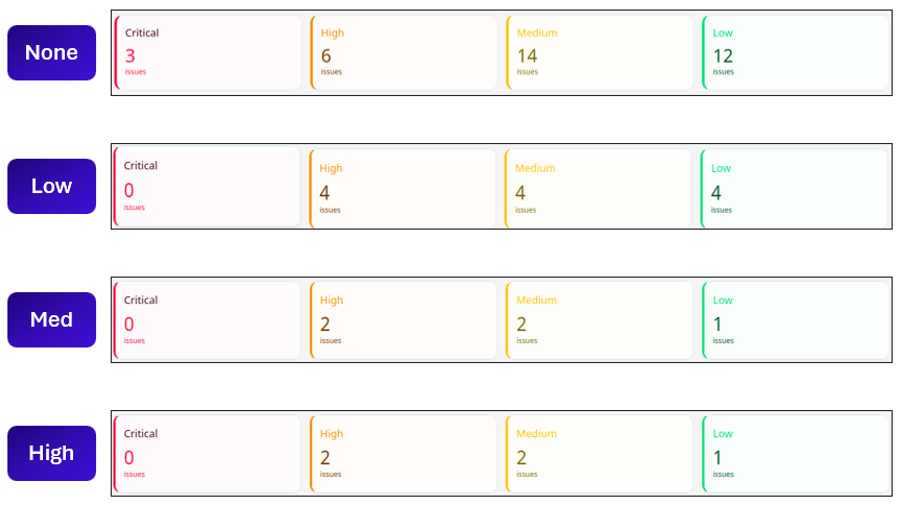

Pour les deux outils, le choix d’un niveau de détection plus contraignant a permis de bloquer plus de prompts malveillants, mais le niveau le plus bas suffit à éviter la majorité des attaques. Pour Azure Content Safety, les vulnérabilités les plus importantes sont bloquées, mais même les configurations les plus basses des deux outils précédents sont plus performantes.
Il est également important de noter qu’augmenter la sensibilité de détection augmente également la proportion de prompts légitimes bloqués par les filtre, ce qui peut impacter l’expérience utilisateurs.
Coût
Chacune des trois solutions est facturée à l’utilisation, où Model Armor émerge comme solution la moins chère, avec seulement $0.10 par millions de tokens (au-delà des 2 millions gratuits), suivi de Bedrock Guardrails avec $0.15 par million de caractères, et enfin Azure Content Safety avec $0.38 par millions de caractères.
Insights
Les principaux éléments à retenir de notre étude sont :
- Les guardrails disponibles via AWS, Azure et GCP sont parmi les plus performantes et offrent des performances similaires.
- Le déploiement de guardrails avec une configuration par défaut permet de bloquer la majorité des prompts malveillants, mais certains parviennent toujours à passer. Il est donc important de configurer les filtres pour les adapter au mieux à l’application à protéger.
- Pour des applications on-premise, ou lorsqu’une personnalisation avancée des filtres est nécessaire, des solutions plus complexes telles que NeMo Guardrails (Nvidia) peuvent être étudiées.
Piste d’amélioration
Notre travail offre une première comparaison entre les solutions de filtrage spécialisées pour les applications d’IA, il peut être étendu en incluant d’autres guardrails et en étudiant l’impact de la personnalisation sur l’efficacité des filtres.

