
Les audits et missions de redteam menés par Wavestone ont mis en évidence un déséquilibre frappant entre la maturité des protections des infrastructures on-premise et celles déployées dans le cloud. Les infrastructures on-premise sont généralement bien identifiées, maîtrisées et protégées selon des standards éprouvés, tandis que leurs équivalents cloud restent souvent sous-évalués en termes de risques et par conséquent insuffisamment sécurisés.
Le principe de tiering préconisé sur les infrastructures on-premise est-il applicable au cloud ?
Évolution du modèle de sécurité
Dans les environnements on-premise, en particulier Active Directory, la sécurité des infrastructures s’appuie généralement sur une segmentation stricte en trois niveaux (T0, T1 et T2) permettant d’isoler les systèmes d’administration critiques (T0), les serveurs (T1) et les postes utilisateurs (T2) afin de limiter les risques de propagation.
Cette organisation hiérarchique et périmétrique est inhérente au monde AD et ne peut être directement appliquée au cloud pour ces deux principales raisons :
- Les portails sont centralisés: une grande diversité d’administrateurs aux droits différents interagit avec la même URL.
- La frontière entre les niveaux d’administration est complexifiée: le principe de permission fine, par rôle (RBAC), par attribut de ressources (ABAC), selon certaines conditions (provenance, risque, conformité, méthode d’authentification…) permet de configurer des accès très précisément, mais complexifie et floute la vision globale des permissions.
Afin de proposer une réponse à ce nouveau paradigme, Microsoft a publié son Enterprise Access Model (décrit ici), mettant en évidence 3 principaux plans : le Control Plane, Management Plane et Data Plane.
Ce modèle reprend la criticité « en cascade », mais simplifiant :
- les 3 tiers en 2 accès : administrateur vs utilisateur ;
- les flux d’administration en accès au portail ;
- la criticité des serveurs en les centralisant dans le Data plane.
Une illustration de l’ancien et du nouveau modèle :
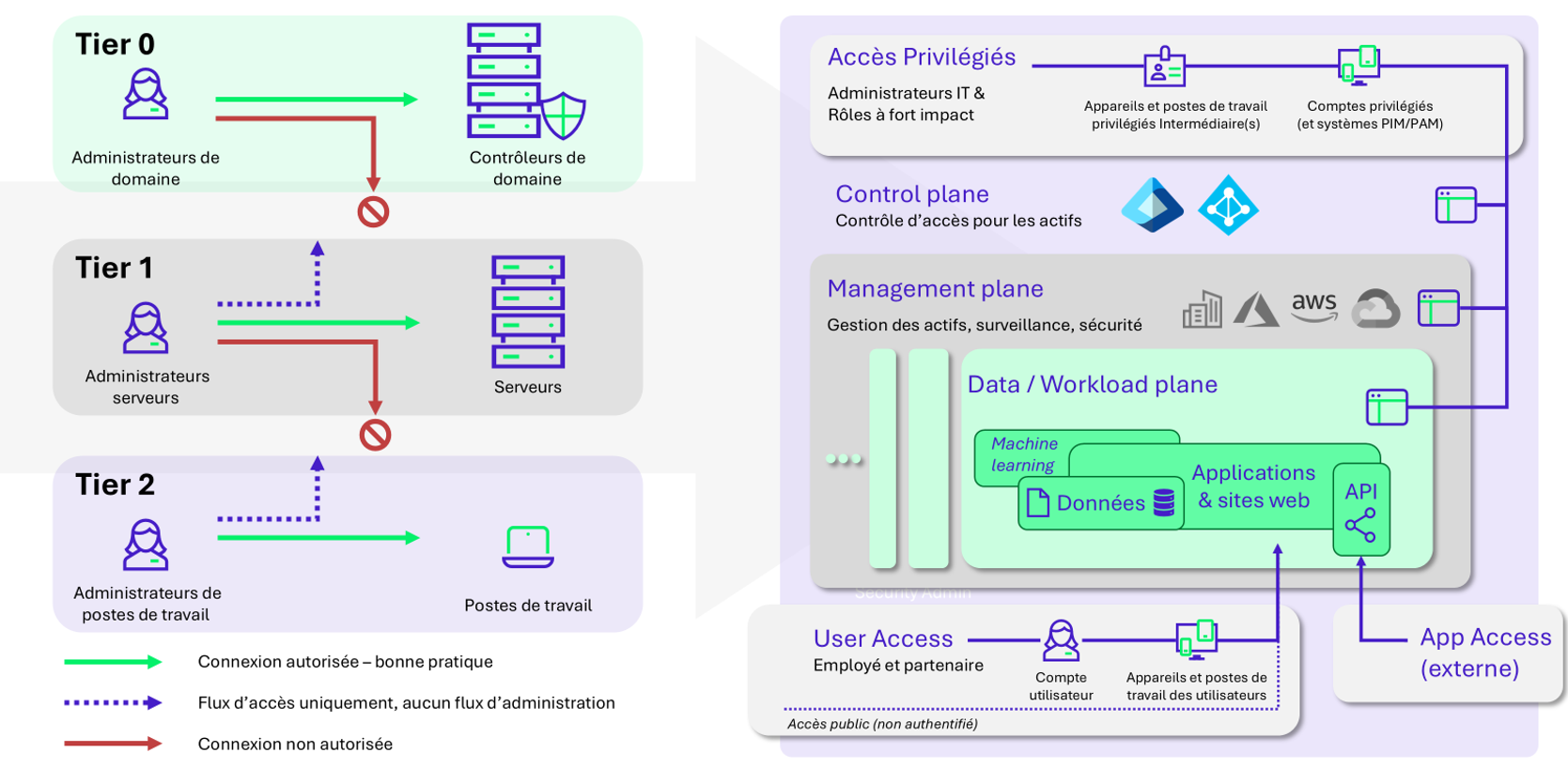
Ce nouveau modèle met particulièrement en valeur 3 éléments :
- L’identité de l’utilisateur : accès privilégié vs accès utilisateur ;
- La donnée et les services : au détriment des serveurs ;
- La méthode d’accès aux portails web d’administration.
L’inversion des importances entre « serveurs » et « portails web » abstrayant l’Active Directory est un changement radical.
Cependant, très peu (si ce n’est aucune) grande structure en est à ce niveau d’abandon de son SI « legacy », une grande partie sera dans un état transitoire où ce SI aura été virtualisé sur un Cloud afin de se séparer de ses datacenters, mais dont les modalités d’administration sont restées les mêmes.
Ces entreprises doivent donc traiter avec un tiering model désuet et un Enterprise Access Model décoléré des risques et besoins de sécurité actuels.
Pour la suite de cet article, nous prendrons comme exemple la société Tartampion, qui vient de terminer un programme Move-to-Cloud de 3 ans sur AWS. Le bilan est le suivant :
- Une Landing Zone a été créée, les applications déjà sur AWS y ont été intégrées
- Les Data Center ont été fermés
- Pris par le manque de temps et de moyens, une majeure partie du SI a été incorporé en lift and shift, incluant des solutions métiers, réseau, bastion et AD.
Un SI hybride et virtualisé qui pose problème
Selon l’EAM, les portails Azure et AWS sont affichés au même niveau (le management plane) au rang T1, sans autre forme de distinction. Or ces 2 environnements cloud sont à eux seuls le support de nombreux SI, utilisés par de multiples collaborateurs avec des niveaux de droits et d’impacts très variés.
Pour illustrer les précédents propos, mettons de côté l’aspect Digital Workplace (suite O365) et prenons 3 comptes AWS issus d’une Landing Zone de Tartampion, supportant différents services d’infrastructure :
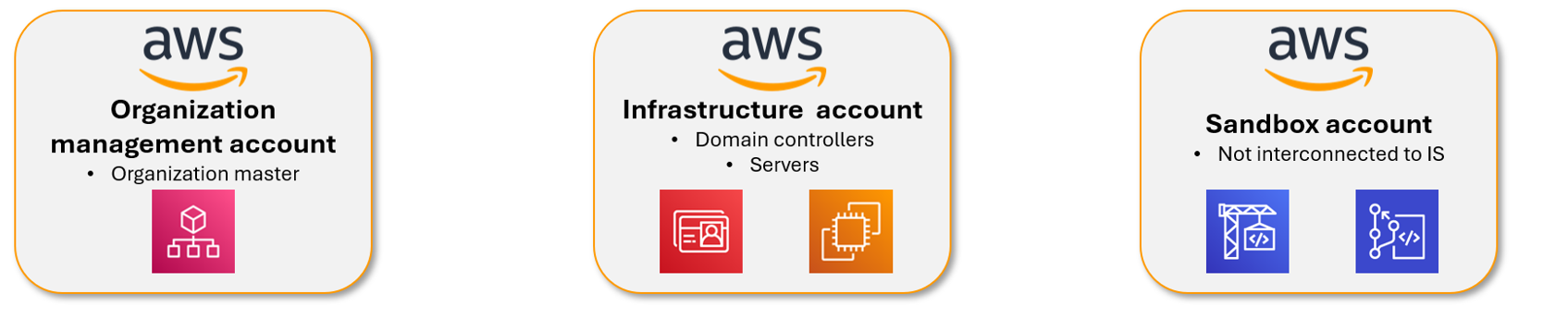
En se fiant au référentiel proposé par Microsoft, ces trois comptes AWS devraient appartenir au Management plane avec un niveau de sécurité T1. Cependant, en cas de compromission d’un des 3 comptes par un attaquant, les impacts seraient très différents.
Si la Landing Zone est correctement implémentée, la compromission d’un compte de Sandbox n’aurait que très peu d’impact, tandis que celle du Master Account entrainerait celle de tous les comptes et ressources sous-jacentes.
Un exemple de découpage plus adéquat serait le suivant :
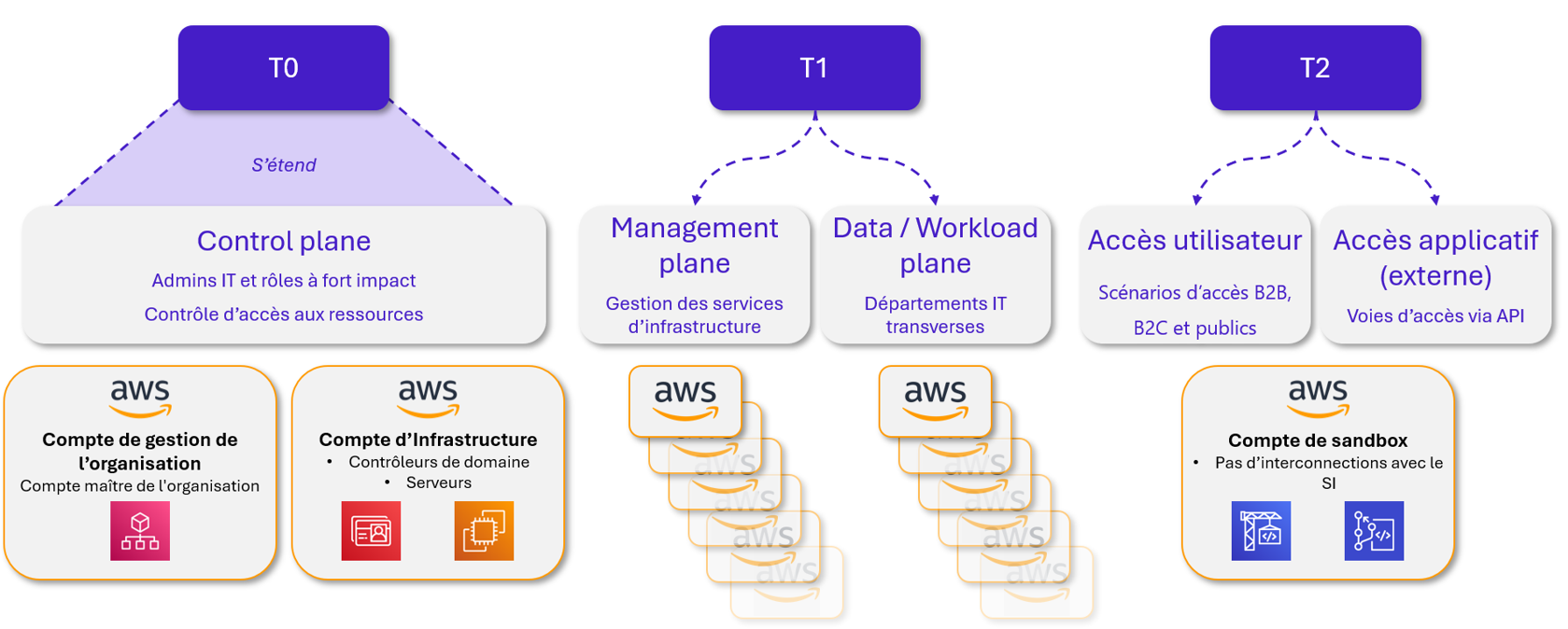
L’Enterprise Access Model par Microsoft est un framework macroscopique permettant d’initier une base de découpage des services cloud, mais qui reste à adapter selon la criticité des SI concernés.
Comment le rendre pertinent ? Pour répondre, il faut comprendre les scénarios d’attaque exploitant les services cloud.
Le Cloud vu de l’attaquant
5 principes du cloud favorisant les attaques
Premièrement, les infrastructures cloud sont par défaut exposées sur Internet, contrairement aux ressources sensibles d’un SI. Ainsi, un phishing réussi conduit très probablement à un accès sur le Cloud.
Deuxièmement, les entreprises ont aujourd’hui des organisations hybrides (on-premise et cloud) :
- Les infrastructures cloud sont reliées au reste du SI on-premise ;
- Les postes de travail peuvent également être hybrides et gérés par un service cloud comme Intune. Les permissions pour utiliser ce service sont gérées dans Entra ID ;
- Les identités sont souvent des comptes synchronisés, cela concerne également les comptes d’administration.
Les organisations hybrides peuvent faciliter les latéralisations entre le cloud et l’on-premise.
Troisièmement, la gestion des identités est très complexe avec différentes portées. Par exemple, Entra ID permet de gérer les accès à Azure et M365 aussi bien pour des utilisateurs, que des applications que des comptes de service.
Pour compléter, les notions de cybersécurité liées au Cloud sont encore relativement nouvelles et méconnues pour certaines équipes « legacy », comme le SOC/CERT, le réseau… Les ressources cloud les plus sensibles ne sont pas systématiquement identifiées, protégées et surveillées.
Enfin, même si des mécanismes de détection natifs sont présents, ils ne sont pas toujours interconnectés avec les SIEM/SOAR, ce qui ralentit les capacités d’intervention. Une récente opération Purple Team menée sur des infrastructures Azure et AWS a confirmé que les outils de détection natifs ont une capacité de détection limitée. Il s’agit d’un constat retrouvable dans les Red Team puisqu’avec une démarche « OpSec », les outils de détection cloud sont rarement capables d’identifier une attaque en cours.
REX de nos tests d’intrusion & Red Team
Issus des opérations de Red Team menées récemment, ces chemins d’attaques spécifiques aux environnements cloud sont témoin des impacts et des facilités qu’il est possible d’avoir pour s’élever en privilège jusqu’à obtenir des accès très permissifs :
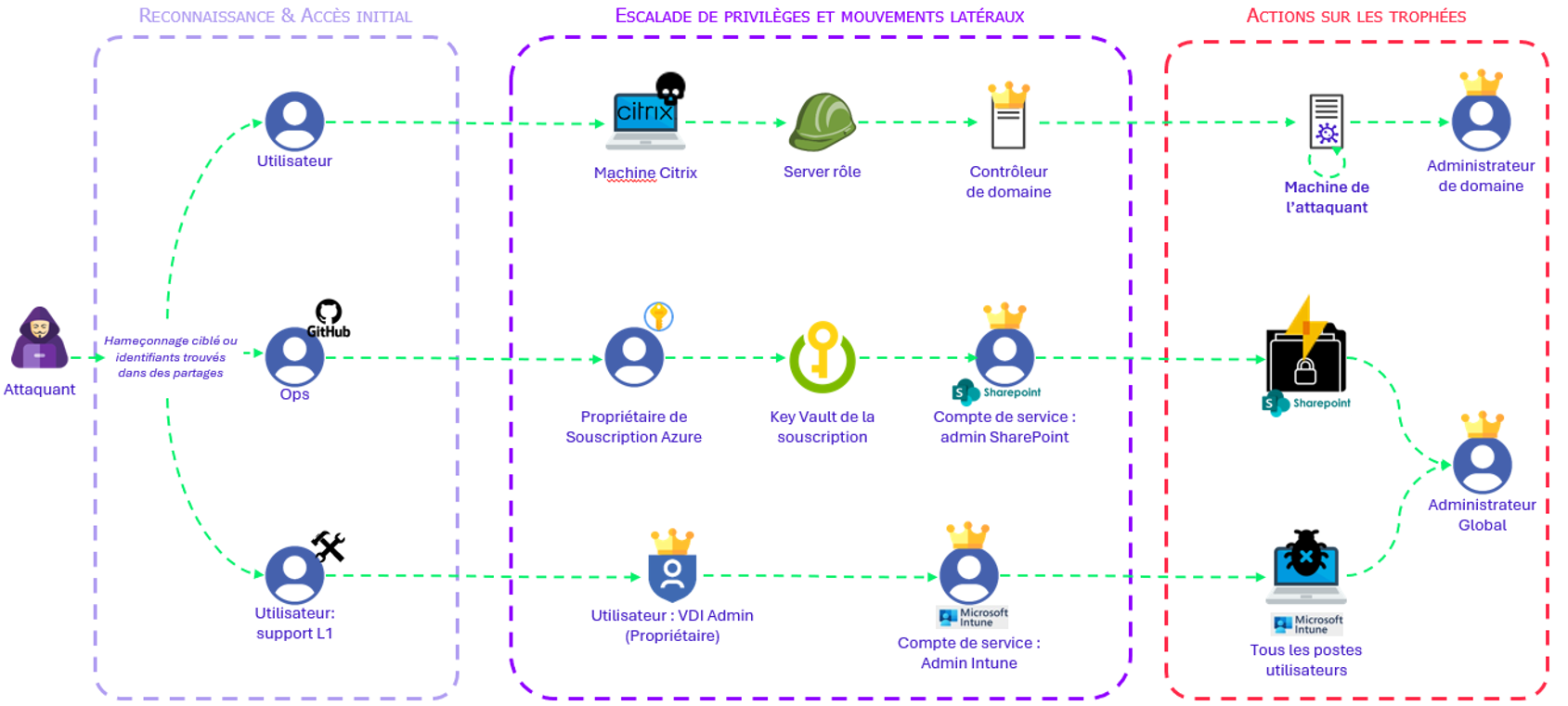
Le premier scénario, effectué sur AWS, est décrit ci-dessous, les deux autres ont été analysés dans une série d’articles Risk Insight disponible ici.
Reconnaissance et Accès initial
Des catégories d’employés sont généralement ciblées afin de compromettre une personne avec des droits intéressants dans le SI (Développeur, Support, OPS…). Un moyen souvent utilisé est d’utiliser du phishing. Les mécanismes de phishing actuel sont capables de contourner l’usage de mots de passe complexe et la plupart des méthodes de MFA (Multi-Factor Authentication).
Escalade de privilèges et mouvements latéraux
Dans le premier scénario, un développeur compromis possédait des accès à une ferme Citrix. Les environnements Citrix ne sont pas simples à durcir complètement et quelques vulnérabilités d’échappement ont permis à la Red Team d’avoir un accès au serveur sous-jacent.
Les informations récoltées sur la machine ont indiqué que le serveur pouvait être hébergé sur AWS. Cela s’est vérifié en essayant d’accéder aux métadonnées AWS du serveur : l’instance avait des droits sur le compte AWS du client. La machine virtuelle du Citrix possédait le rôle « AmazonEC2FullAccess » lui permettant des actions de gestion sur les EC2 du même compte AWS.
À l’aide de la CLI AWS, les autres EC2 ont été listées. Un contrôleur de domaine du client était présent dans ce compte AWS. C’est une pratique courante de vouloir regrouper dans un même compte, généralement appelé « Shared Services », les services qui ont pour vocation d’être utilisés par plusieurs projets. Il est néanmoins recommandé de vérifier que la criticité des services partagés soit homogène de sorte à pouvoir appliquer un durcissement adéquat sur le compte, ou les séparer en plusieurs environnements.
Actions sur les trophées
À partir du rôle AWS du serveur Citrix, une sauvegarde instantanée du contrôleur de domaine a été faite puis téléchargée. Les sauvegardes d’un contrôleur de domaine contiennent tous les fichiers de la machine, y compris les fichiers les plus sensibles, comme la base ntds.dit, qui contient les informations et secrets de tous les utilisateurs du domaine. L’exfiltration de cette base se traduit en la compromission totale du domaine AD concerné.
Ce scénario illustre l’un des chemins d’attaques qui ont été exploités lors des opérations de redteam, facilité par le manque de visibilité sur les impacts que peuvent avoir une ressource compromise hébergée sur le cloud.
Des impacts plus rapides et plus forts
Les attaques déjà possibles sur un SI on-premise peuvent être reproduites et même accélérées grâce aux fonctionnalités du cloud. Par exemple, le chiffrement de buckets S3 (service de stockage de fichiers) à partir d’une clé KMS (de chiffrement) d’un autre compte AWS imite le chiffrement massif de données, ou l’utilisation de la fonctionnalité « lifecycle » permet une suppression de tous les objets en moins de 24 heures, peu importe la quantité de données.
De nouvelles attaques sont également apparues comme le « Hijack de souscription » qui permet de rattacher un abonnement d’une organisation Azure à une autre et ainsi de voler toutes les données qu’il contient et empêcher les actions de remédiation. Cette attaque est réalisable en quelques clics depuis l’interface web Azure.
Identification et protection du cœur de confiance cloud
Identification du Cœur de confiance
Le cœur de confiance adopte une approche centrée sur la priorisation des actifs, qui diffère du modèle de tiering ou de l’Enterprise Access Model de Microsoft. Contrairement à ces modèles qui proposent un découpage prédéfini, il n’existe pas de grille universelle : chaque organisation doit identifier elle-même quelles ressources méritent le plus haut niveau de protection. L’idée est d’établir un cercle restreint de ressources critiques (qu’elles soient cloud ou on-premise) puis de déployer des niveaux de protection dégressifs à mesure que l’on s’éloigne de ce cœur.
L’identification du cœur de confiance repose sur deux grands critères :
- Criticité métier: ce sont les ressources qui concentrent la valeur et la continuité des activités de l’entreprise. Si elles venaient à être perdues ou compromises, les conséquences seraient immédiates pour le fonctionnement quotidien et financièrement. Un environnement SharePoint contenant la donnée intellectuelle / brevets en est un exemple courant ;
- Criticité SI: il s’agit des ressources qui assurent l’administration du système d’information et qui disposent d’un niveau d’accès élevé. Leur compromission aurait un impact majeur sur l’ensemble du SI et permettrait d’avoir l’impact métier précédemment énoncé. On retrouve ici les contrôleurs de domaine ou encore les services d’IAM Cloud comme Entra ID et AWS Identity Center.
Cette cartographie n’est jamais totalement tranchée. Pour certains éléments, la posture à adopter reste plus floue, deux exemples l’illustrent bien :
- L’EDR: élément de sécurité évident d’un SI, systématiquement déployé tant sur les postes de travail que sur les serveurs cloud et on-premise, sa console d’administration est de plus en plus souvent exposée sur internet, et permet d’exécuter des commandes arbitraires sur les équipements qui en sont équipés.
- Les chaînes CICD: un savant, mais complexe agglomérat d’applications s’appelant entre elles, dont l’accès (le gestionnaire de code : GitLab, GitHub…) est offert à l’ensemble des collaborateurs et les droits sur le SI (manipulé par les runners de déploiement) sont bien souvent administrateur de l’ensemble des infrastructures cloud. Sur l’ensemble des Red Team effectués en 2024 & 2025, 80% ont exploité des vulnérabilités associées à ses solutions pour progresser dans leur opération, voire obtenir des trophées de compromission par ce biais.
Afin d’identifier le « noyau dur » du cœur de confiance, qu’on appellera socle de sécurité, on peut reprendre les préceptes de l’ancien T0 : la compromission d’un de ses éléments entrainerait probablement celles des autres, et par cascade de la majeure partie du SI.
En supposant que vos applications appliquent un correct cloisonnement interutilisateur (l’intégralité de vos sites SharePoint n’est pas accessible par tous, n’est-ce pas ?), les références aux prochaines applications seront à comprendre comme des accès administrateurs / super-utilisateurs à ces dernières, et non simple utilisateur.
Voici l’une des représentations possibles pour un cœur de confiance hybride :
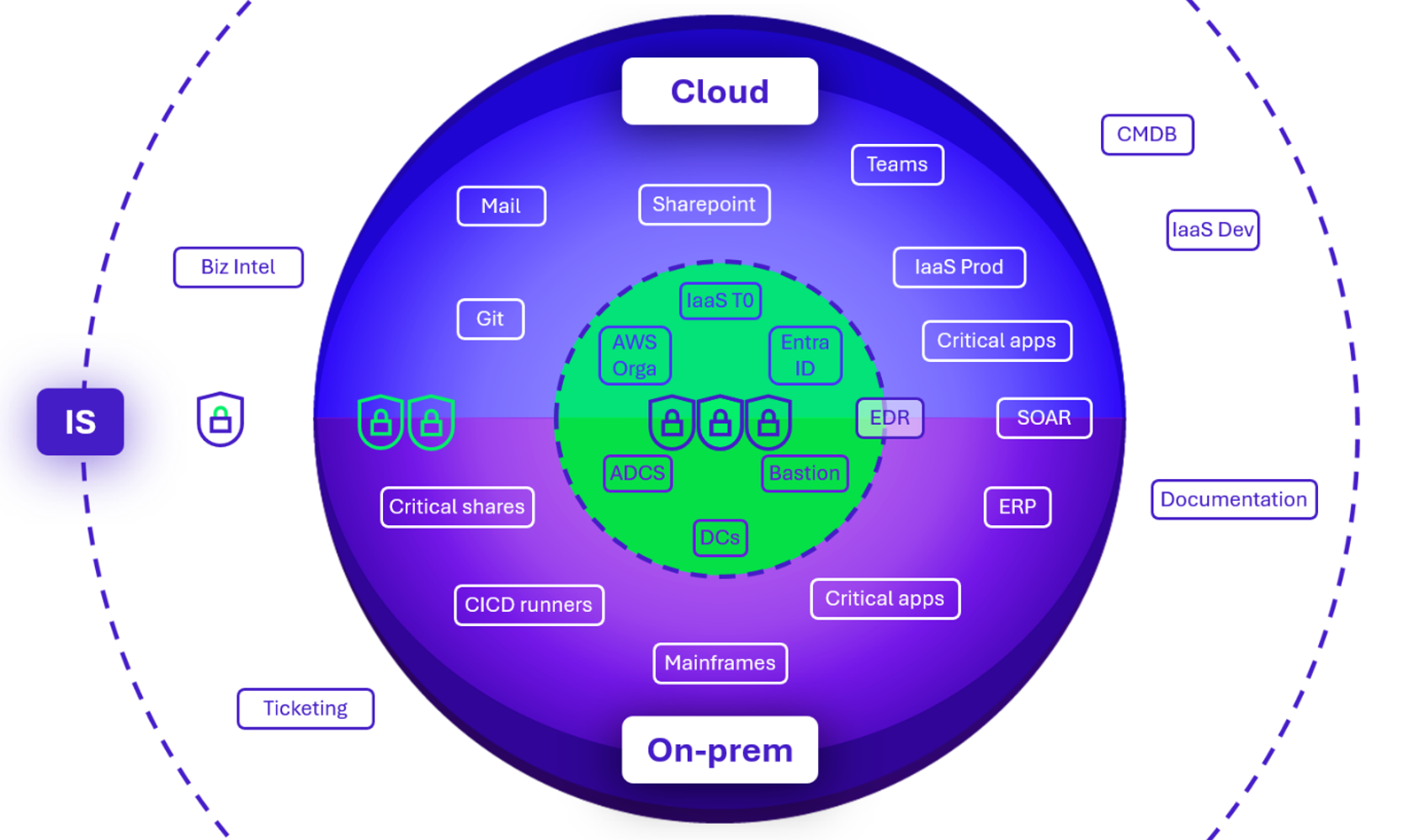
Dans cette représentation, il y a côté on-premise :
- Le T0 avec ses contrôleurs de domaine, l’ADCS, et potentiellement la PKI, le bastion, la console EDR…
- Le T1 en intégrant en plus les applications métiers à fort impact.
Et côté Cloud, on retrouve :
- Au cœur le Control Plane (AWS Orga & Identity Center, Entra ID) ainsi que les modules de la Landing Zone supportant le T0 (si une partie du T0 est hébergée dans le Cloud) ;
- En s’éloignant, les diverses consoles d’administration des suites de bureautique, et de management des infrastructures ou des applications.
En établissant ce diagramme, il est important de garder à l’esprit que :
- L’IT sert au métier et quand bien même la zone centrale du cœur de confiance est principalement occupée par des briques techniques, il convient d’inscrire ses solutions critiques ;
- Les chaînes de dépendance / compromission ont beaucoup d’impact sur les choix d’architecture: positionner un AD sur AWS, ou déployer un EDR sur un AD peut soudainement créer de nombreux chemins de compromission et de rebond entre les 2 mondes.
Enfin, la construction d’un cœur de confiance ne peut pas se limiter à une logique de classification statique. Elle doit reposer sur une approche qui évalue la criticité de chaque actif et le risque qu’il introduit (une entreprise de développement de logiciel ne positionnera surement son Git au même niveau qu’une entreprise de travaux public).
Protection du cœur de confiance cloud
La sécurité du cœur de confiance va reposer sur les deux traditionnels facteurs de risques :
- Réduire l’impact: comment empêcher un utilisateur compromis ou malveillant de se connecter aux portails cloud sur un navigateur et de faire des actions sensibles en quelques clics, comme faire une sauvegarde d’un contrôleur de domaine hébergé sur une VM ou supprimer les sauvegardes de données de production ?
- Réduire la probabilité : comment réduire les risques d’accès illégitimes à partir d’un cookie de session volé par phishing, de la compromission d’un poste de travail ou de la réutilisation de mots de passe des utilisateurs ?
Protection du socle de sécurité cloud
Concernant le « socle de sécurité » cloud il est possible de hiérarchiser les environnements par criticité selon cette échelle macroscopique :
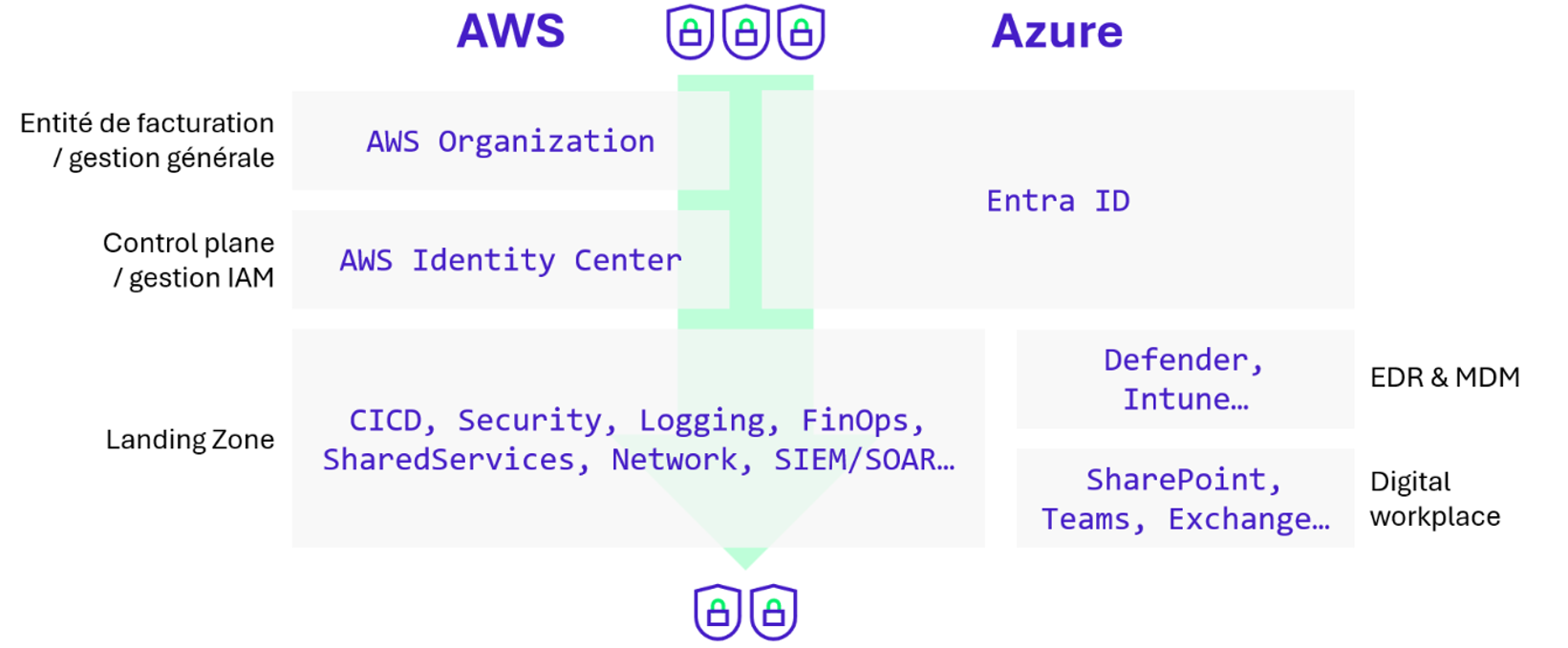
En fonction des équipes en charge et de la complexité de les inclure dans un niveau de protection particulièrement élevée, certaines organisations font le choix d’exclure des environnements dont la compromission ne permettrait pas une latéralisation dangereuse, telle que ceux de FinOps, de détection, le Digital Workplace…
La sécurisation du socle de sécurité cloud repose sur 2 principaux points :
- Une hygiène impeccable : configuration IAM épurée, respect du moindre privilège, procédure de déploiement, limitation des ressources au strict nécessaire…
- Une couche de sécurité passive / active : déploiement de politiques (SCP sur AWS, Policy sur Azure) interdisant explicitement certaines actions, ou la manipulation de certaines ressources, et règles de détection afin de lever une alerte en cas de modification d’une politique ou l’occurrence d’un de ses évènements protégés ;
Ces politiques peuvent efficacement être associées à une stratégie de tagging afin d’appliquer, en plus du modèle RBAC (Role Based Access Control) un modèle ABAC (Attribute Based Access Control).
Par exemple il est possible de tagger différentes ressources avec une clé « tiering » et une valeur entre « T0 », « T1 », « T2 » puis de déployer cet ensemble de stratégies :
- Interdire toute action visant une ressource taguée tiering par une identité dont la valeur de son propre tag tiering n’est pas équivalente ;
- Interdire la manipulation de tag tiering, sauf pour un rôle bien précis.
Et voilà comment, en quelques tags et 2 SCP, il est possible de répliquer le tiering model de Microsoft (quelques exceptions peuvent subvenir).
Protections des identités et des accès
Pour protéger les utilisateurs, 3 thématiques de durcissement peuvent être mises en place :
- Identité : avec quel compte l’utilisateur se connecte-t-il aux interfaces d’administration cloud ? Comment les droits sont-ils obtenus ?
- MFA : l’identité est-elle protégée avec une authentification multifactorielle résistante aux attaques de phishing ?
- Provenance: à partir de quelle plateforme l’utilisateur se connecte-t-il aux interfaces d’administration cloud ? La plateforme est-elle managée, et saine ?
Plusieurs niveaux de protection sont envisageables afin de protéger les administrateurs cloud :
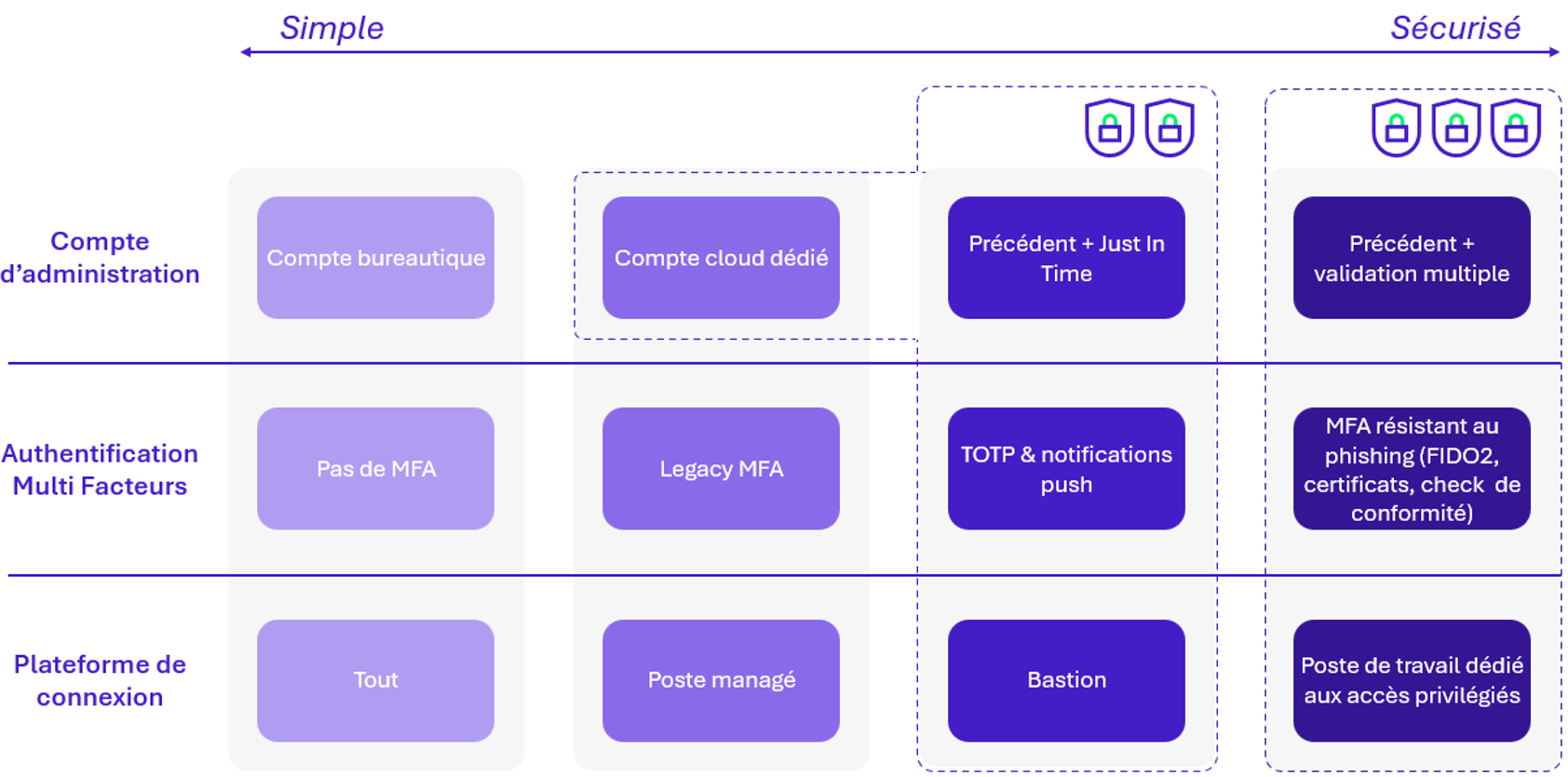
Afin de protéger le cœur de confiance restreint, représenté par les triples cadenas, il est recommandé de mettre en œuvre les facteurs d’authentification les plus robustes. Cela inclut l’utilisation d’un compte dédié à l’administration cloud, l’activation d’une authentification multifactorielle physique (exemple : clé de sécurité FIDO2) et le recours à un poste de travail spécifiquement réservé aux opérations sur ce cœur de confiance.
Pour les ressources plus éloignées du centre du cœur de confiance, symbolisées par les doubles cadenas, un niveau de sécurité durci, mais proportionné peut être appliqué, afin de renforcer la protection pour maitriser les coûts et réduire les contraintes excessives aux utilisateurs concernés.
Finalement, les méthodes les plus sécurisées sont également celles qui impliquent le plus de contraintes aux personnes concernées. Il faut maitriser les usages et prendre en compte des situations d’urgence, comme une intervention en astreinte nécessitant des privilèges très élevés.
Répéter les opérations
À l’issue des phases d’identification et de protection, les ressources seront réparties dans les différentes couches du cœur de confiance.
Pour vérifier la bonne implémentation du cœur de confiance, un audit peut être conduit pour vérifier la bonne protection des ressources critiques qui le compose.
Un système d’information est toujours en évolution, mais les deux premières phases auront été faites à un instant t. De nouvelles ressources critiques peuvent être ajoutées, d’autres modifiées, voire supprimées. Il est primordial de refaire une évaluation régulière de son SI et de mettre à jour la répartition des ressources dans le cœur de confiance.
En conclusion, la sécurité des systèmes d’information s’inscrit désormais dans un contexte de complexité croissante et de forte diversification des composants et services d’infrastructures.
Dans ce contexte, il apparaît de plus en plus complexe de définir un modèle de sécurité universel. Certains cadres conservent toute leur pertinence sur des périmètres bien identifiés : le tiering reste une référence pour la sécurisation de l’Active Directory, tout comme l’EAM pour des environnements Cloud fortement centrés sur l’écosystème Microsoft. Néanmoins, ces modèles atteignent rapidement leurs limites dès lors que l’on s’éloigne de ces cas d’usage spécifiques.
Pour la majorité des systèmes d’information, une approche fondée sur l’analyse des risques s’impose donc comme la plus pertinente. Identifier un cœur de confiance, définir clairement les actifs critiques — les crown jewels — et décliner les mesures de sécurité à partir de ces éléments permet de construire une posture de sécurité plus pragmatique, adaptée à la réalité du SI et capable d’évoluer avec lui.
Cette logique, moins normative mais plus contextualisée, constitue sans doute l’un des leviers majeurs pour concilier sécurité, agilité et pérennité des systèmes d’information.

