
In the previous article, we presented a step by step approach for Machine Learning applied to cybersecurity in order to use its value and understand how it works (lien vers partie 1 de l’article). In this second part, we will answer a few common questions that may arise before starting such an initiative.
Is the amount of data the only success factor?
Absolutely not. #GarbageInGarbageOut
Focusing only on the data is the best way to be disappointed by machine learning. Results do not appear out of thin air if the input data is not carefully chosen!
Not only should you define precisely the use case before starting, but you need to make sure that relevant data will be fed to the model.
What use case should I choose to do machine learning?
You’re looking at the problem upside down!
The right questions would rather be:
- Are some use cases currently causing problems? g. time-consuming process because all the alerts raised require analysis, and ultimately include many false positives.
- Does a machine learning based approach fit with some of those problems? g. alerts raised on a behaviour deemed as « abnormal », rather than a fixed detection threshold that would be hard to configure and to keep up to date.
- Have I checked that there are no standard solutions to tackle the problem? #IAmNotReinventingTheWheel
In cybersecurity, in front of a complex problem that has to be described explicitly (e.g what is a suspect communication in my information system?) and that additionally is very likely to evolve along time (e.g the detection thresholds need frequent adjustment), finding the right compromise between detection of suspect use cases and false positives with static rules can be difficult. In these kinds of situation, it is interesting to explore the machine learning option.
Who leads the project: the cybersecurity team or the data team?
Both, with a lot of communication! #OneTeam
Each of these teams have their own expertise, technical for data scientists, business for the cybersecurity team. One without the other does not allow to properly conduct a machine learning for cybersecurity project.
Without data scientists, the cybersecurity team might for instance:
- Start without enough data. g. the volume of data does not allow the algorithm to define a standard behaviour and it cannot separate normal situations from abnormal.
- Forget to cross some data. g. each user’s first connection to a new application is detected as an abnormal event, because it is not combined with a variable to allow the comparison of this specific behaviour with the behaviour of the mass of users (that already use the application).
- Not being able to interpret the alerts given by the algorithm, and not being able to optimize it. g. the algorithm shows anomalies that turn out not to be, the cybersecurity team does not understand on what is based the algorithm’s analysis and does not know how to improve it.
And without the cybersecurity team, the data scientists might:
- Not know how to assess the relevance of the anomalies detected. g. the algorithm rises a log as an anomaly, but the data scientists cannot evaluate if it is a real cybersecurity issue or not.
- Not being able to select the data the algorithm should be fed with. g. cybersecurity gave its proxy logs to the data scientists, but they did not sort the most adequate fields for the use case: the results of the algorithm are confused.
- Miss out on crucial elements that should be integrated in the model to answer the need of the business. g. by trying to optimise an algorithm, a field that is necessary to the categorisation of an anomaly in cybersecurity is deleted from the data set; the results of the algorithm are no longer valuable for cybersecurity purposes.
Combining the expertise of both teams is key to guarantee that the resources of the Machine Learning will be used efficiently to bring a high value-added answer for cybersecurity.
What are the prerequisites?
The data!
Although it is not the only aspect to focus on, no model can be create without data.
As a reminder, machine learning encompasses all the techniques that allow machines to learn without having been explicitly programmed for their purpose. For them to learn, the algorithms are fed with the data that we can provide them.
- They will need a high quantity of data so that they can define a « norm » as sharp as possible, since it will be defined and confronted to important volumes of real-life cases. Note that «high quantity » does not necessarily mean « diversity »: it is important to only select the data relevant for the use case.
- The data will need to be qualitative not to deceive the learning of the algorithm, e. without the introduction of biases for instance.
It will be useful to identify the relevant type of data for the analysis (e.g. security logs), the sources where they will be collected (e .g. web proxies) and the resources that will enrich them (e.g. CMDB to link IPs with machine names) if needed.
I don’t have much data available for my use case, does this mean that machine learning is not for me?
Not necessarily!
If the available data is relevant to the use case and well distributed (e.g. representative of a usual situation on a defined time period so that a non-supervised algorithm could learn the « normal » situation), it is possible to have interesting results.
For instance, with a well-defined use case (e.g. targeted on a specific user population) and the adequate collected logs, suspect behaviors can be detected in proxy logs with only two weeks of traffic (depending on the wordiness of the logs, this only represents a few GB).
Which algorithm should I use?
Pick one and see!
The most important element that will allow to answer this question in a more adapted way is the type of learning process: supervised or non-supervised.
The choice of one non-supervised algorithm rather than another will affect performance, but not as much as the input data. Many algorithms can work for a given use case, and their performance will depend on the context (e.g. need to interpret the results, volume of the training data…).
The data scientists choose the algorithm based on their watch in order to suggest the most recognized and performing algorithm for a determined use case and context.
Should I do it myself or outsource?
It depends, and it can evolve in time!
Our first article detailed an implementation example: development with your own tools, starting from scratch. In reality, there are three implementation options; the choice depends on the use case, the available resources and the ambitions.
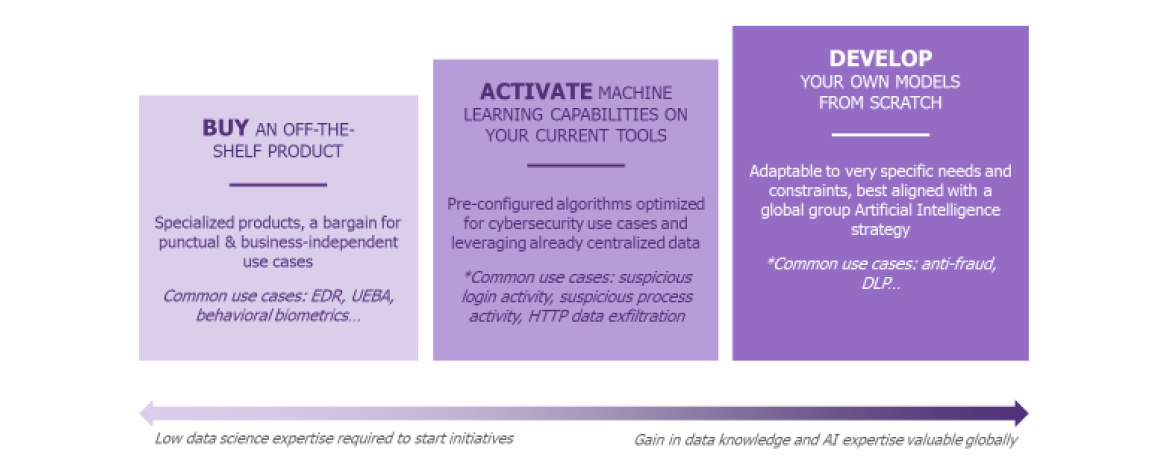
Each of these scenarios present their strengths and weaknesses and it is possible to use them conjunctly. Also, it is essential to keep an eye on the market in order to observe if new, innovating and more-performing solutions have since appeared.
#TakeAStepBack
Is it easy to test?
If the framing is well done, yes! #Test&Learn
Once that the use case is selected, the data availability checked and the implementation method chosen, it is rather easy to test the benefit of machine learning before further investments.
This type of project is well adapted to iterative or sprint methods. Try out rapidly the selected solutions, demonstrate their relevance thanks to the added value, or on the contrary bring to light the fact that for this use case, the results are not encouraging enough to continue.
Whatever the case may be, a POC approach following an opportunity study can help you get a quick idea. This step, before starting on a larger scale, also enables you to take a step back to evaluate the potential benefits (e.g gains in time due to less false positives, better overall reactivity because the alerts are more relevant) compared to the investment to be made (e.g dedicated computing infrastructures, skills to recruit) before starting.
Once that my POC is done, how do I scale up?
Once again, step by step!
Once that the first conclusive results are obtained on a use case, it is possible to envisage a production launch. Be careful not to go too fast: the production launch raises new questions that must be answered before continuing, for instance:
- What are the volumes of data to analyse? What pre-processing (data preparation phase) needs to be done beforehand? How frequently? (Real time, delayed time…)
- How often will the algorithm need to go through the learning process? On how much data?
- What are the necessary infrastructures?
- Which skills and resources will enable to maintain to solution in time?
It will then be time to take a step back and make operational choices while keeping in mind a long-term vision.
How much does it cost?
It all depends on the ambitions.
For a POC, a framing allows to limit the investment until the added value of machine learning is demonstrated (e.g. activation of an option on a security tool on a determined time frame to test it, no infrastructure investment)
Once the added value is tangible, the question of the costs involved for production launch and maintenance in time surges. A few elements must be considered to evaluate the total investment that will be needed:
- Material investments (e.g. hardware for market solutions, infrastructure and resources to acquire computing power, in-house development) and software investments (license, machine learning feature activation on SIEM, big data tools for data science…). It is essential not to put aside the computing power that is necessary to the functioning of some models. It is one reason why – besides the quality of the results- the most relevant data are needed to answer a use case.
- Talent acquisition : the new profiles to include (e.g. data scientists, data engineers) as well as the business profiles and accurate experts, that will be solicited during the project phase but also in the long term (alerts handling, re learning process, non-diversion tests for the solution, etc.)
To sum up, what are the main pitfalls to avoid?
#Reminder


