
The rise of generative AI and Large Language Models (LLMs) like ChatGPT has disrupted digital practices. More and more companies choose to deploy applications integrating these language models, but this integration comes with new vulnerabilities, identified by OWASP in its LLM Top 10. Faced with these new risks and new regulations like the AI Act, specialized solutions, named guardrails, have emerged to secure interactions with LLMs and are becoming essential to ensure compliance and security for these applications.
Benchmark’s objective
Given the proliferation of filtering solutions for Large Language Models (LLMs) as well as the language models themselves, our work consisted of comparing these different solutions to identify the most relevant ones to address security and integration challenges according to the different use-cases an organization may face.
Methodology
To evaluate these solutions, several criteria were selected:
- First, filtering effectiveness, covering both the ability to detect malicious prompts and the proportion of false positives, to prevent filtering from deteriorating the end-users’ experience.
- Next, the latency generated by this analysis, to ensure that these solutions can be used in production without slowing down the model’s response times.
- Finally, the customization capability of these filters, to adapt to the different use cases desired by organizations.
To carry out the evaluation, two series of tests were performed: first, to evaluate filtering effectiveness, a prompt dataset was submitted to each solution, containing both malicious and legitimate prompts, and then through an automated “AI Red Teaming” test tool allowing the robustness of these filtering elements to be evaluated against prompt injections and classical exploitation attempts.
Technical Implementation
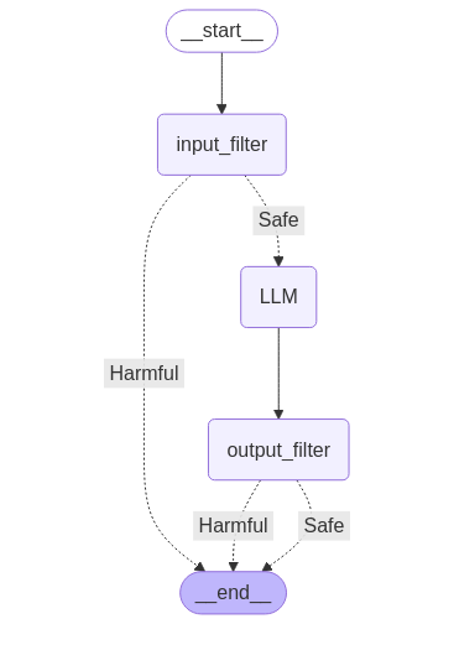
In order to test the different solutions, we implemented a modular test environment, with the evaluation pipeline broken down as follows:
- Our prompt passes through the first filter which analyzes the input prompt before proceeding to our brain: the LLM
- Once the request is processed by the LLM, we ensure that no unwanted data or behavior is present in the generated content with an output filter before returning the response to the user
This test environment was developed in Python, using classical frameworks and libraries for AI systems:
- LangChain & LangGraph to orchestrate processing flows and simplify model interactions
- Groq Cloud for the model execution environment, the model used for our tests was gemma2-9b-it
- The dataset of prompts came from HuggingFace, and contained both legitimate (66%) and malicious (33%) requests, including intentionally ambiguous questions allowing to tests the guardrails boundaries
- Promptfoo for the automated “red teaming” evaluation
Evaluated Solutions
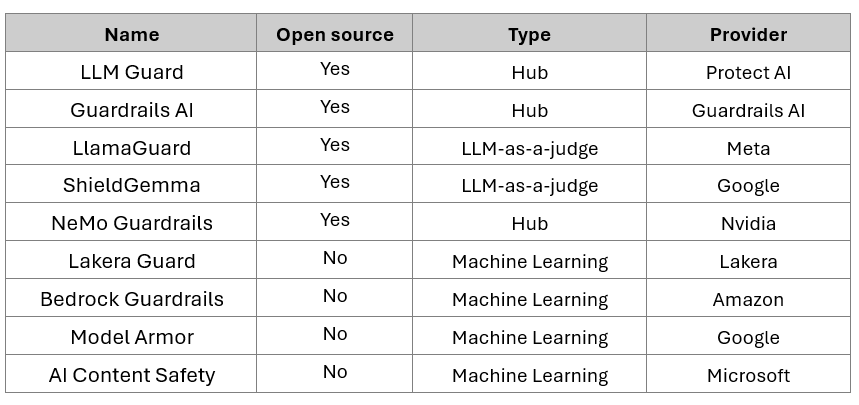
Among the many filtering solutions identified at the time of our study, we chose to select nine, distributed across three categories: guardrails from cloud providers (AWS Bedrock Guardrails, Azure Content Safety, GCP Model Armor), open-source solutions (Llamaguard, ShieldGemma and Nemo Guardrails) and pure players (Lakera Guard).
To ensure a common ground for the evaluation, all solutions were used in their most default configuration, without any customization of filtering rules.
Key Results
To compare the classification results, the F1 score was chosen as the metric to allow for equal consideration of false positives and false negatives in our evaluation.

With the following definitions:
- True Positives (TP) where malicious prompts are classified as such.
- False Positives (FP) where legitimate prompts are classified as malicious.
- True Negatives (TN) where legitimate prompts are classified as such.
- False Negatives (FN) where malicious prompts are classified as legitimate.
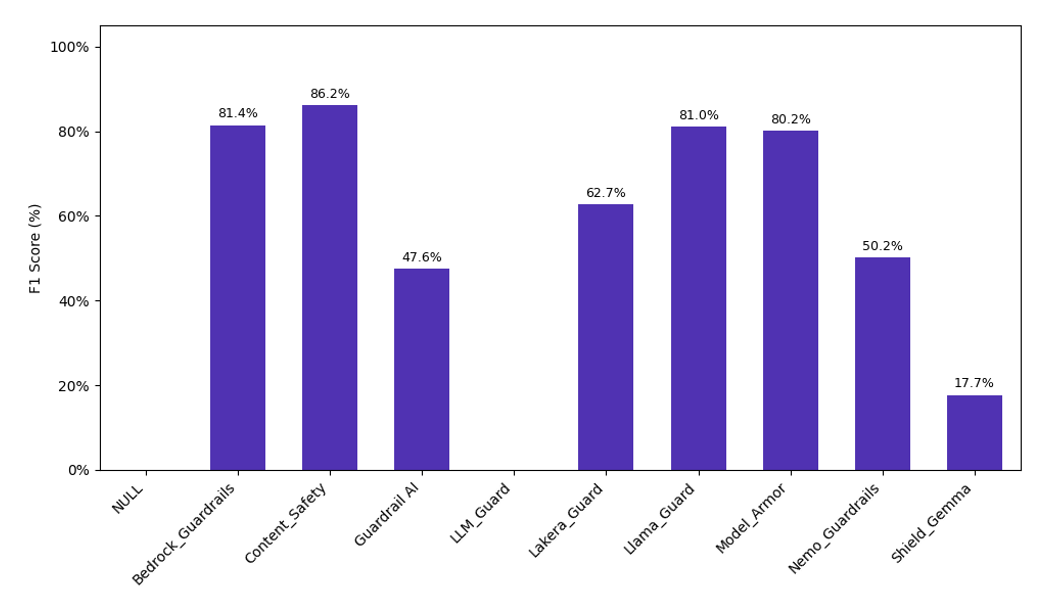
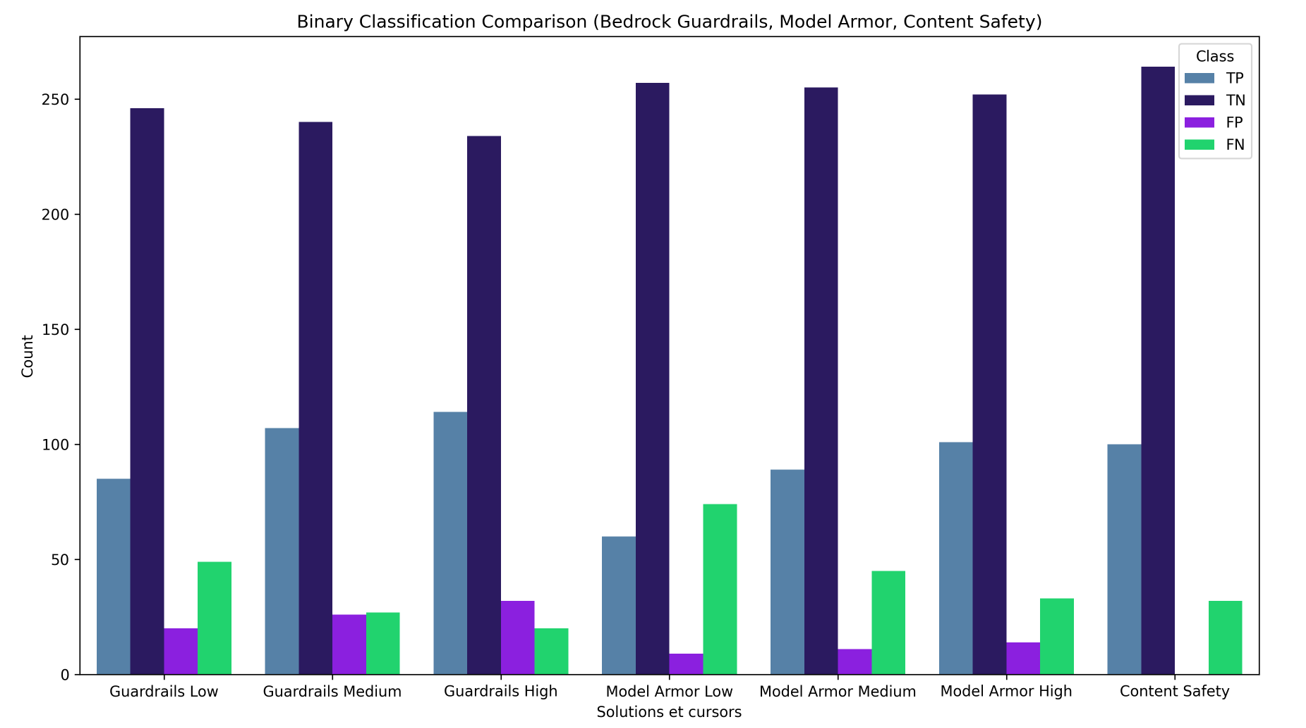
Based on these scores, a few key results can be considered. First, all three of the guardrails integrated by the cloud providers had good classification results on our tests (>80%), while other solutions such as Guardrails AI and NeMo Guardrails suffered from poor scores due to their severe classifications, marking every single prompt as malicious, whereas LLM Guard suffered the opposite problem and considered all prompts as benign.
However, depending on the use-case, choosing the right guardrails solution is not as simple:
- For use-cases where user convenience is the most important, having the fewest false positives is important, Content Safety should be considered, as it never incorrectly categorized legitimate prompts.
- However, for critical use-cases, which require blocking the most malicious prompts, Bedrock Guardrails is the highest performer.
Focus on Cloud Provider guardrails
To dive deeper into this analysis, a particular attention was paid to the cloud providers’ solutions since they are among the top performers of our primary analysis and are readily available in projects deployed to the cloud.
For this second analysis we relied on Promptfoo, an automated AI red teaming tool, to test numerous prompts corresponding to diverse prompt injection and jailbreak techniques, focusing on harmful content generation and privacy breaches.
Based on these tests we observed that all three of the filters managed to block the majority of the attack prompts and similar overall performances:

Sensitivity Configuration
The configuration of GCP Model Armor and AWS Bedrock Guardrails allows us to set a sensitivity level to the guardrails configured in order to adapt the detection to the required level for the considered use-case.
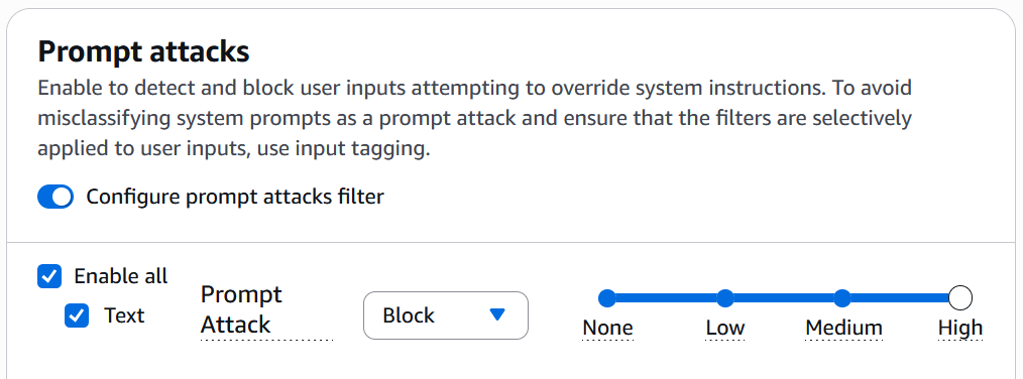
We tested each detection level for GCP Model Armor and AWS Bedrock Guardrails to measure its impact on the vulnerabilities identified by Promptfoo.
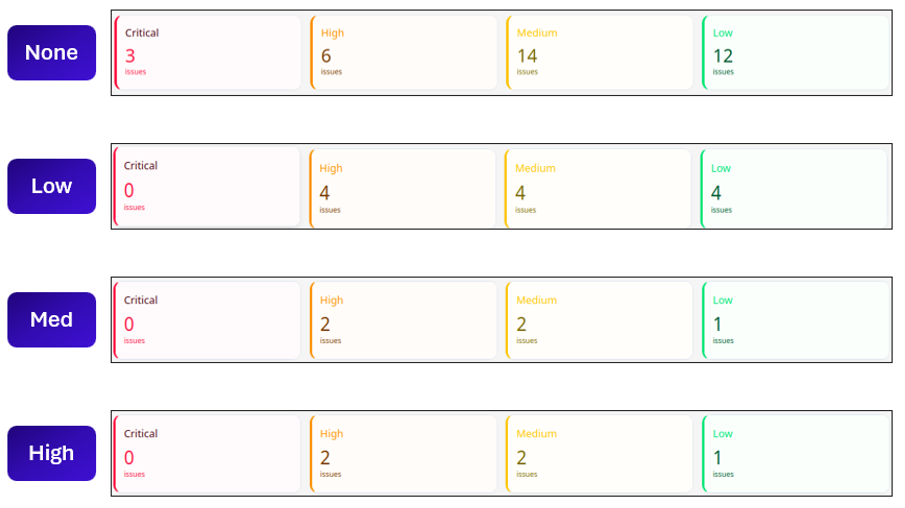


With both configurable guardrails solutions, choosing a higher detection sensitivity allowed us to catch more malicious prompts, but even the lowest setting managed to block most of the vulnerabilities identified. As for Content Safety, it blocked the most important vulnerabilities but is outperformed even by the lowest settings of Bedrock Guardrails and Model Armor.
However, it should be noted that increasing the detection sensitivity also increases the proportion of benign prompts blocked by the filters.
Costs
All three of the solutions considered are billed on a pay-as-you-go basis, with Model Armor emerging as the least expensive solution with only $0.10 per million token (above the 2 million free tokens), followed by Bedrock Guardrails with $0.15 per million characters, and finally Azure Content Safety with $0.38 per million characters.
Key Insights
Based on our study, here are the main elements to remember:
- The guardrails available in AWS, Azure and GCP are among the best performers and offer similar overall detection performances.
- Deploying guardrails with the default configuration blocks most malicious prompts, but some manage to escape even the highest detection sensitivity. Configuring customized guardrails based on your specific use-case is therefore important.
- For on-premises use-cases, or when advanced customization is required, more complex solutions such as Nvidia’s NeMo Guardrails can be deployed.
Future Work
Our work is a first comparison between specialized AI guardrails solutions; it can be expanded by including more of the commercial solutions and studying in more details the impact of custom configurations on each solution.

