
Cet article a pour but de présenter nos convictions sur l’utilisation du Machine Learning par les startups françaises en cybersécurité du Radar Wavestone 2019.
L’intelligence artificielle est un sujet à la mode et la cybersécurité fait partie des cas d’usages phare de développement. Est-ce aussi le cas pour les startups françaises en cybersécurité ? Qu’en est-il de son utilisation ? Quelles sont les tendances du marché concernant cette technologie ?
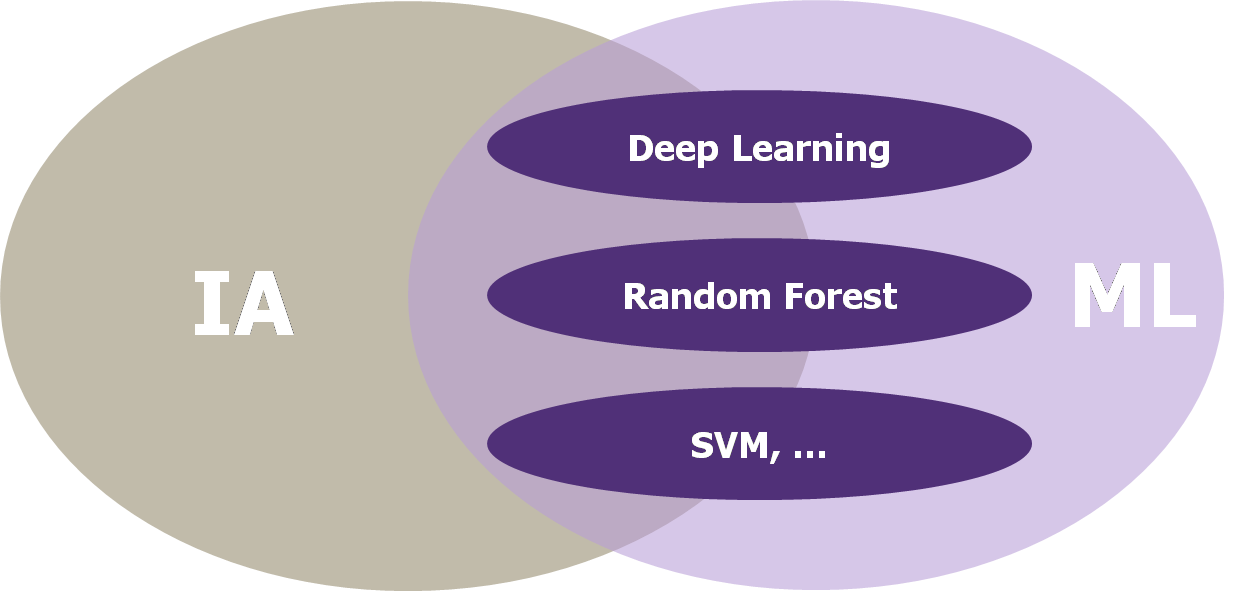
« Intelligence Artificielle », « Machine Learning », « Deep Learning » : trois termes trop souvent confondus
Avant de rentrer dans le vif du sujet, commençons par clarifier le vocabulaire qui sera employé dans la suite de l’article :
- Intelligence Artificielle: ensemble des techniques mises en œuvre pour que des machines simulent l’intelligence ;
- Machine Learning: technique reposant sur des modèles statistiques qui permettent à l’ordinateur « d’apprendre » à partir d’un grand nombre de données ;
- Deep Learning: méthode de Machine Learning basée sur un réseau de neurones profonds. D’autres méthodes existent : Support Vector Machines, Random Forests, K-Nearest Neighbors, …
La confusion entre ces trois termes est fréquente. Bien souvent l’utilisation du terme « Intelligence Artificielle » en cybersécurité désigne l’utilisation du Machine Learning, sous toutes ses formes.
La cybersécurité, un terreau fertile pour les technologies de Machine Learning
Sur les 134 startups recensées dans notre radar 2019 des startups françaises en cybersécurité, 19% proposent des solutions basées sur du Machine Learning. Interrogées, 70% de ces startups déclarent que développer ce type de technologie dans leurs solutions fait partie de leur stratégie.
De plus, l’utilisation du Machine Learning dans certains domaines de la cybersécurité devient quasi incontournable et la majorité des startups de ces domaines envisagent de baser les futures évolutions de leur solution sur cette technologie.
Le Machine Learning en cybersécurité est en pleine progression et son utilisation, déjà implanté dans l’écosystème des startups françaises, démontre une forte volonté d’innovation du marché. On pressent que ce rythme d’adoption va continuer à s’accélérer dans les années à venir, la même « photo » de l’état des lieux dans un an devrait le prouver.
Le Machine Learning utilisé dans un but d’amélioration de performances
Les startups qui ont choisi d’utiliser le Machine Learning le font principalement afin de :
- Obtenir des temps de réponses courts: réduire le temps de réponse de la prise de décision en utilisation nominale. En effet, dans certains cas où le nombre de données est particulièrement important, il faudrait des mois à un algorithme n’utilisant pas de Machine Learning pour fournir un résultat ;
- Améliorer la fiabilité des détections: réduire le nombre d’erreurs, c’est-à-dire diminuer le taux de faux positif et faux négatifs. Les solutions anti-phishing sont une bonne illustration car celles reposant sur du Machine Learning filtrent avec moins d’erreur qu’une solution dite « classique ».
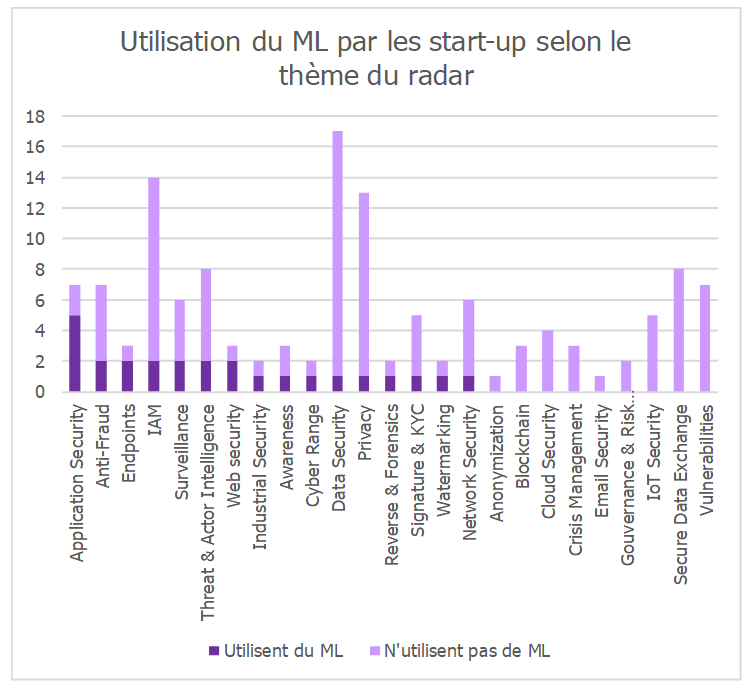
Une adoption hétérogène selon le thème du radar…
L’adoption du Machine Learning varie de manière importante d’une thématique du radar à l’autre. Les thématiques où l’utilisation du Machine Learning est la plus répandue sont : « Application Security », « Endpoint », « Industrial Security » et « Web Security ». On note également quelques cas d’usages particuliers dans d’autres thèmes du radar tel DPO Consulting utilisant du Machine Learning pour aider à la prise de décisions dans le cas d’une évaluation des risques.
…expliqué par la nature même du Machine Learning.
Le Machine Learning nécessite un certain nombre de prérequis et de conditions pour fonctionner efficacement. Toute la performance des modèles de Machine Learning repose sur la phase d’entrainement où le modèle « apprend » grâce aux données qu’on lui fournit. Ces données, que nous allons illustrer par le cas d’une solution anti-phishing pour boite mail, doivent être :
- Pertinentes: c’est-à-dire porteuses d’informations utiles. Dans notre exemple de solution anti-phishing, une information utile est par exemple la présence de certains mots souvent utilisés dans des mails de phishing ; une image ou la taille du fichier mail sont moins utiles ;
- En nombre suffisant: ce nombre varie selon le cas d’usage et le niveau de précision souhaité. Dans notre exemple de solution anti-phishing, il faudrait probablement entrainer l’algorithme avec quelques dizaines de milliers de mails ;
- Variées: si possible de sources différentes pour plus de résilience de l’algorithme. Dans notre exemple de solution anti-phishing, il serait bon que la base de données d’entrainement contienne des mails issus de différentes campagnes de phishing, reçus par différents entreprises/particuliers, des mails ciblés ou non…, et qu’elle puisse traiter à la fois le contenu du mail mais également les headers, etc. ;
- Représentatives : c’est-à-dire ne pas introduire de biais et être à jour. Dans notre exemple de solution anti-phishing, il convient par exemple de ré-entrainer régulièrement le modèle afin de prendre en compte les dernières tendances en matière de phishing.
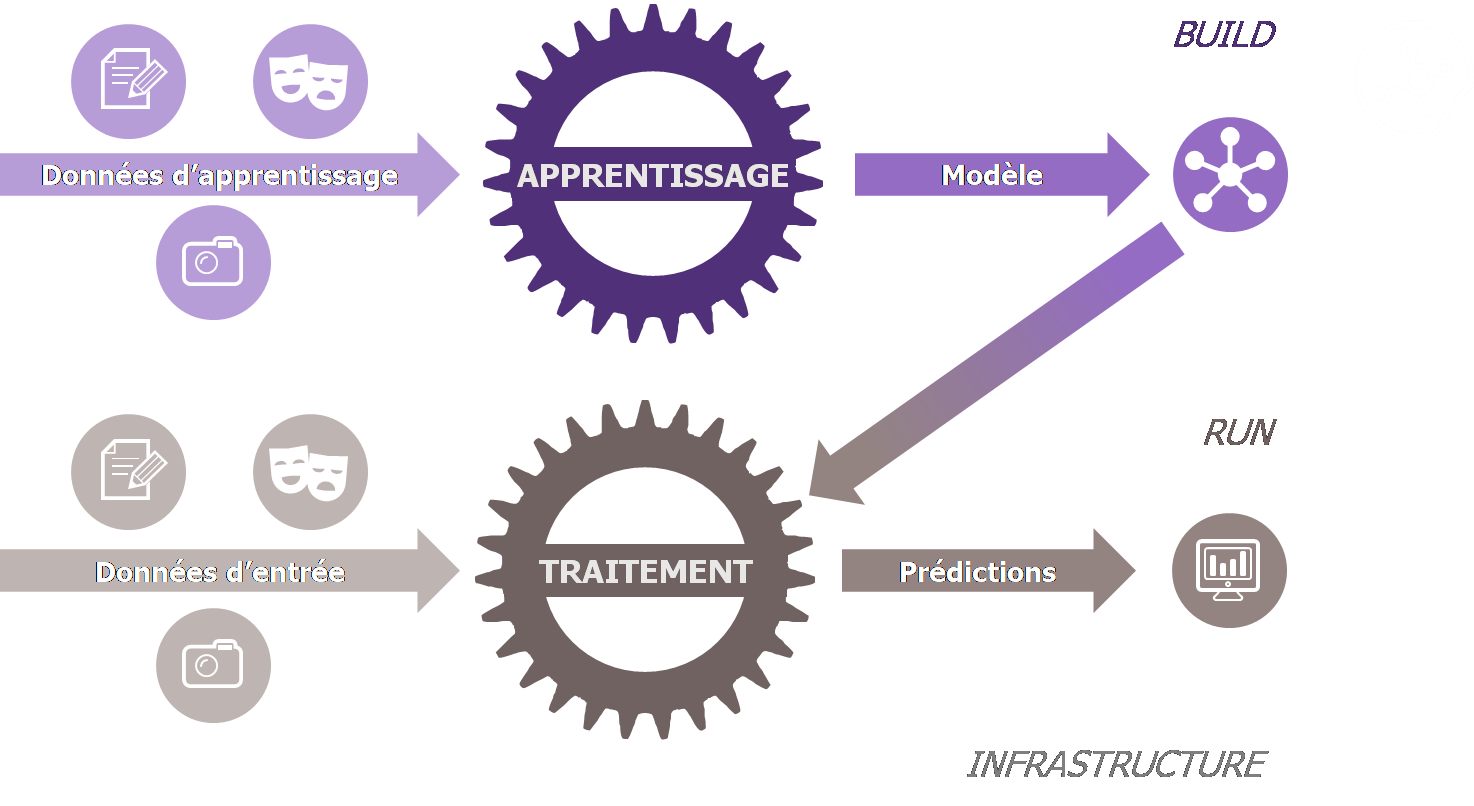
Schéma de fonctionnement d’une solution basée sur du Machine Learning
Dans les domaines où le Machine Learning est le plus utilisé, il s’avère que ces conditions sont plus facilement réunies. En effet, les données nécessaires à l’entrainement sont souvent déjà disponibles dans les équipements en place (log applicatifs, log système, log réseau, alerte anti-virus, …), voire déjà consolidées dans des équipements de sécurité centraux (SIEM, Data Lake…).
« Intelligence Artificielle » : Gare à l’effet de mode !
Si le Machine Learning offre de nouvelles possibilités permettant de grandement améliorer les capacités cybersécurité des entreprises, cette technologie n’est pas en soi une solution miracle. Il est important de bien comprendre ces algorithmes et de garder certains points d’attention en tête avant de se lancer dans l’acquisition d’une telle solution.
Tout d’abord, comme la phase d’entrainement est clé pour la performance du Machine Learning, il faut s’interroger sur sa capacité à fournir à la solution les données nécessaires et suffisantes pour l’apprentissage. Le principal frein remonté par les startups proposant des solutions entrainées avec des données clients est d’ailleurs la difficulté d’obtenir des données en qualité et quantité suffisante pour faire tourner leur solution.
Il est également important de réussir à lire au-delà du discours commercial pour comprendre l’apport réel du Machine Learning à la solution, au risque de payer plus cher un outil qui ne serait pas forcément justifié. Et surtout, il faut être conscient que le Machine Learning ne signifie pas ne plus avoir de risques. Ces solutions, comme toute solution de sécurité, répondent à un cas d’usage précis et viennent compléter un ensemble de mesures de sécurité.
Cette mise en garde nous semble nécessaire même si nous avons constaté une utilisation pertinente et justifiée de ces technologies par les startups françaises en cybersécurité dans le cadre de notre analyse.

