
Dans une première partie, nous avons présenté une démarche pas à pas de Machine Learning appliqué à la cybersécurité afin d’illustrer sa valeur et d’en comprendre le fonctionnement. Dans cette seconde partie, nous allons répondre à un certain nombre de questions courantes que l’on peut se poser avant de se lancer dans de telles initiatives.
Je suis en mesure d’envoyer toutes mes données à un algorithme de Machine Learning, va-t-il m’en sortir de la valeur ?
Non, absolument pas. #GarbageInGarbageOut
C’est même la meilleure manière d’être déçu par le Machine Learning ! Ce n’est pas un outil magique : si n’importe quoi lui est donné en entrée, il n’en sortira pas magiquement des résultats pertinents.
Il est non seulement nécessaire de définir précisément son cas d’usage avant de se lancer, mais également de choisir intelligemment les données qui vont nourrir le modèle.
Justement, quel cas d’usage choisir ?
Le problème est pris à l’envers !
La question est plutôt de savoir si :
- Aujourd’hui, des cas d’usages vous posent problème (e.g. chronophages parce que les alertes levées nécessitent beaucoup de retraitement et finalement remontent beaucoup de faux positifs).
- Le Machine Learning pourrait permettre d’apporter des solutions à certains d’entre eux (e.g. levée d’alerte sur un comportement « normal » plutôt que sur des seuils de détection fixes complexes à configurer et maintenir à jour).
- Et les solutions classiques pour y répondre semblent arrivées à la limite de leurs capacités. #JeNeRéinventePasLaRoue
En cybersécurité, devant un problème complexe à décrire explicitement (e.g. qu’est-ce qu’une communication suspecte ?) qui en plus a de fortes chances d’évoluer dans le temps (e.g. les seuils de détections sont constamment à ajuster), il est très difficile de trouver le bon compromis entre détection des cas suspects et faux positifs avec des règles statiques. Dans ce genre de situation il est intéressant d’explorer la piste du Machine Learning.
Qui mène le projet : l’équipe cyber ou l’équipe data ?
Les deux et avec de nombreux échanges ! #OneTeam
Ces deux équipes ont des expertises différentes, technique pour les data scientists, métier pour l’équipe cybersécurité. L’une sans l’autre ne permet pas de conduire un projet de Machine Learning pour la cybersécurité correctement.
Sans data scientists, l’équipe cybersécurité risque par exemple de :
- Se lancer en ayant trop peu de données (e.g. le volume de données ne permet pas à l’algorithme de définir une norme de comportement, il interprète donc des situations normales comme anormales).
- Ne pas penser à combiner certaines données (e.g. chaque première connexion d’un utilisateur à une nouvelle application remonte en anomalie parce qu’on ne lui a pas ajouté de variable lui permettant de comparer ce comportement à celui de la masse des utilisateurs (qui utilisent déjà l’application)).
- Ne pas savoir interpréter les alertes remontées par l’algorithme, et a fortiori ne pouvoir l’optimiser (e.g. l’algorithme remonte des anomalies qui n’en sont pas, l’équipe cybersécurité ne comprend pas sur quoi il base son analyse et ne sait donc pas les réorienter).
Et sans l’équipe cybersécurité, les data scientists risquent de :
- Ne pas pouvoir évaluer si l’algorithme remonte des anomalies pertinentes (e.g. l’algorithme remonte un log en anomalie mais les data scientists ne peuvent pas évaluer s’il s’agit d’un vrai problème de cybersécurité ou non).
- Ne pas pouvoir sélectionner finement les données à communiquer à l’algorithme (e.g. la cybersécurité a donné les logs de ses proxys aux data scientists mais n’a pas trié les champs les plus pertinents pour le cas d’usage : les résultats de l’algorithme sont confus).
- Passer à côté d’éléments cruciaux à intégrer dans le calcul de l’algorithme pour répondre au besoin métier (e.g. voulant optimiser un algorithme, un champ nécessaire à la catégorisation d’une anomalie de cybersécurité est supprimé du jeu de données, les résultats de l’algorithme perdent toute leur valeur cybersécurité).
Combiner les expertises de ces deux équipes est clé pour garantir que les ressources du Machine Learning seront utilisées efficacement pour apporter une réponse à haute valeur ajoutée pour la cybersécurité.
Quels sont les prérequis ?
Les données !
Sans données, fin de l’histoire avant même qu’elle n’ait commencée.
Pour rappel, le Machine Learning est l’ensemble des techniques permettant aux machines d’apprendre, sans avoir été explicitement programmées pour. Et pour cela, nos algorithmes apprennent en se nourrissant de données que nous allons pouvoir leur fournir.
- Il les leur faudra en quantité pour qu’ils puissent tirer une « norme » la plus affutée possible, car définie et confrontée à des volumes importants de cas réels. A noter que « quantité » ne veut pas forcément dire « diversité » : il est important de sélectionner uniquement les données pertinentes pour le cas d’usage.
- Il les leur faudra également en qualité pour ne pas tromper l’apprentissage de l’algorithme, n’introduisant pas de biais par exemple.
Il sera donc nécessaire d’identifier les types de données intéressantes à analyser (e.g. logs de sécurité), les sources où elles seront collectées (e.g. proxy web) et les ressources qui permettront de les enrichir (e.g. CMDB pour faire le lien entre IP et nom de machine), si nécessaire.
J’ai peu de données disponibles pour mon cas d’usage, le Machine Learning n’est donc pas pour moi ?
Pas forcément !
Si les données disponibles sont particulièrement pertinentes pour le cas d’usage à adresser et bien réparties (e.g. représentatives d’une situation habituelle sur une période de temps pour qu’un algorithme non supervisé puisse apprendre la situation « normale ») il est possible d’avoir des résultats intéressants.
A titre indicatif, avec un cas d’usage est bien défini (e.g. cible d’une population d’utilisateurs spécifique) et des logs adéquats collectés, des comportements suspects peuvent être détectés dans des logs proxy avec seulement deux semaines de trafic (suivant la verbosité des logs, cela ne représente que quelques centaines de Go).
Quel algorithme j’utilise ?
En fait, « peu importe » !
L’élément déterminant qui permettra de répondre de manière plus ou moins adaptée à un cas d’usage est plutôt le type d’apprentissage : supervisé ou non.
Le choix d’un algorithme non supervisé plutôt qu’un autre a ensuite peu d’importance : il existe plusieurs algorithmes adaptés à un même cas d’usage, dont la performance dépendra plutôt du contexte (e.g. besoin d’interpréter les résultats, volume de données d’entrainement…).
Les data scientists orientent le choix sur la base de leur veille, pour proposer des algorithmes plus reconnus pour être performants sur un cas d’usage et dans un contexte défini.
Je fais moi-même ou je sous-traite ?
Ça dépend, et ça peut évoluer dans le temps !
Notre premier article détaille un exemple d’implémentation : le développement avec ses propres outils, en partant de zéro. Mais dans les faits, trois possibilités d’implémentations sont possibles. Le choix dépend des cas d’usages envisagés, des ressources disponibles et de ses ambitions.
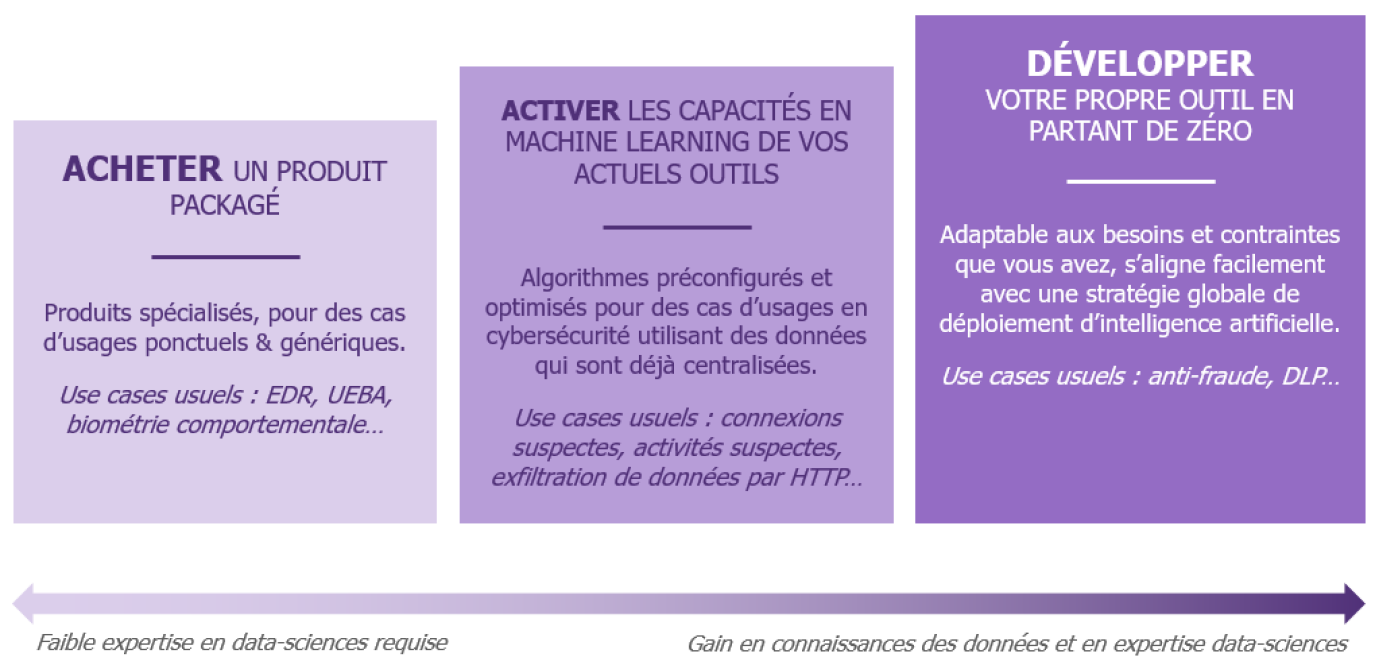
Chacun de ses scénarios présente ses avantages et ses contraintes, et il est possible de les utiliser de concert. Par ailleurs, il est essentiel de resonder régulièrement le marché afin d’étudier si de nouvelles solutions innovantes et plus performantes ne sont pas apparues depuis le déploiement de la solution initiale.
#TakeAStepBack
Est-ce facile à tester ?
Si le cadrage est bien fait, oui ! #Test&Learn
Une fois le cas d’usage sélectionné, la disponibilité des données vérifiée et le choix d’une implémentation en fonction de son contexte faite, il est plutôt simple de réaliser un test de l’apport du Machine Learning avant d’investir davantage.
Ce type de projet se prête très bien à des démarches itératives ou par sprints. Cela permet d’éprouver rapidement les solutions retenues et d’en démontrer la pertinence par la valeur apportée, ou au contraire mettre en évidence que pour ce cas d’usage les résultats ne sont pas suffisamment satisfaisants pour poursuivre.
Dans tous les cas, une démarche par PoC à la suite d’une étude d’opportunité permet de se faire rapidement une idée. Cette étape, avant de se lancer à grande échelle permet également de prendre de la hauteur pour évaluer les gains potentiels (e.g. gains de temps car moins de faux positifs à traiter, meilleure réactivité globale car les alertes levées sont plus pertinentes) par rapport aux investissements à réaliser (e.g. infrastructures de calcul spécifiques, compétences à recruter) avant de se lancer.
Une fois que j’ai fait mon PoC comment je passe à l’échelle ?
Encore une fois, pas à pas !
Une fois les premiers résultats concluants obtenus sur un cas d’usage, il est possible d’envisager son passage en production. Attention toutefois à ne pas aller trop vite : le passage en production amène de nouvelles questions auxquelles il est nécessaire de répondre avant de poursuivre, par exemple :
- Quels volumes de données seront à analyser ? Quelles opérations de pre-processing (préparation des données) seront à réaliser ? A quelle fréquence ? (Temps réel, différé…)
- A quelle fréquence l’algorithme devra-t-il refaire son apprentissage ? Sur quels volumes de données ?
- Quelles infrastructures seront donc nécessaires ?
- Quelles compétences et ressources permettront de maintenir la solution dans le temps ?
Il sera alors le moment de prendre un pas de recul et de faire des choix opérationnels, en ayant en tête une vision long terme.
Combien ça coûte ?
Tout dépend du stade de réflexion et de ses ambitions.
Pour un PoC, un cadrage permet de limiter l’investissement tant que l’apport du Machine Learning n’est pas démontré (e.g. activation d’une option sur un outil de sécurité le temps de tester, pas d’investissement en infrastructures).
Une fois la valeur ajoutée démontrée, se pose la question des coûts à engager pour la mise en production et le maintien dans le temps. Plusieurs éléments sont à considérer pour évaluer l’investissement total qui sera nécessaire :
- Investissements matériels (e.g. boîtiers pour les solutions du marché, infrastructures et ressources pour gagner en puissance de calcul pour les développements internes) et logiciels (licences, activation des fonctionnalités Machine Learning sur les SIEM, outils de Big Data pour la data science…). Il est clé de ne pas négliger la puissance de calcul nécessaire au fonctionnement de certains modèles. C’est une raison en plus de la qualité des résultats pour cibler au maximum les données les plus pertinentes pour répondre à un cas d’usage.
- Acquisition des compétences : tant les nouveaux profils à intégrer (e.g. data scientists, data engineers) que les profils métiers et experts pertinents, qui seront sollicités non seulement en phase projet mais également dans la durée (traitement des alertes, réapprentissage, tests de non-déviation de la solution, etc.)
En synthèse, quels sont les principaux pièges à éviter ?
#Reminder


