
Le Purple Teaming est devenu une pratique incontournable pour les organisations souhaitant évaluer et améliorer leurs capacités de détection et de réponse. En favorisant la collaboration entre équipes offensives et défensives, les exercices Purple Team permettent de valider les contrôles de sécurité, d’identifier les lacunes de détection et de renforcer les processus de réponse aux incidents.
Cependant, les exercices Purple Team traditionnels ne reflètent l’état de sécurité d’une organisation qu’à un instant donné. Dans des environnements en constante évolution, où les infrastructures, les applications et les contrôles de sécurité changent régulièrement et où les menaces évoluent en permanence, les résultats d’une évaluation peuvent rapidement devenir obsolètes. Les organisations se retrouvent alors face à une question essentielle : les détections qui fonctionnaient hier sont-elles toujours efficaces aujourd’hui ? Pour y répondre, le Purple Teaming doit évoluer d’un exercice périodique vers un processus de validation continue.
Cet article présente un workflow modulaire que nous avons développé afin de transformer la CTI (Cyber Threat Intelligence) en simulations d’adversaires automatisées. Ce workflow combine Caldera pour l’orchestration des attaques, Mythic pour la simulation réaliste des mécanismes de commande et de contrôle (C2) et VECTR pour le suivi et la mesure de la progression des capacités du SOC : un workflow automatisé que l’on configure une seule fois et que l’on peut exécuter à tout moment.

Vision et expertise Purple Team de Wavestone
Chez Wavestone, nous réalisons des exercices Purple Team depuis plusieurs années afin d’aider nos clients à s’assurer que leurs capacités de détection ne sont pas seulement pertinentes sur le papier, mais réellement efficaces en conditions opérationnelles.
L’objectif principal de notre approche Purple Team est d’identifier les scénarios d’attaque qui échappent aux contrôles de sécurité en place et de définir des mécanismes de détection adaptés pour combler ces lacunes. Au-delà de la simple simulation d’attaques, nous évaluons systématiquement la détection selon trois critères essentiels : l’activité est-elle journalisée, une alerte est-elle générée à partir de ces journaux, et cette alerte est-elle correctement prise en charge par le SOC ?
En collaboration étroite avec les équipes Blue Team au travers d’échanges réguliers, cette démarche structurée nous permet d’identifier à la fois des quick wins (améliorations rapides à fort impact) et des projets plus structurants nécessitant des évolutions d’architecture ou des investissements de long terme, toujours adaptés au contexte de nos clients.
Pour atteindre cet objectif, nos opérations Purple Team s’appuient sur plusieurs approches complémentaires, chacune présentant ses propres atouts et limites.
Tests Unitaires
Les tests unitaires constituent l’approche la plus élémentaire du Purple Teaming. Ils consistent à tester des TTPs spécifiques et isolés afin de valider l’efficacité de règles de détection individuelles. En rejouant ces attaques sans contexte ni adaptation à l’environnement, les équipes de sécurité peuvent vérifier que les sources de journaux, les mécanismes de corrélation et les alertes associés sont correctement configurés et fonctionnent comme attendu. Bien qu’ils soient particulièrement efficaces pour valider des contrôles individuels, les tests unitaires n’offrent qu’une vision partielle du niveau de sécurité global d’une organisation : la détection d’une technique isolée ne garantit pas la capacité à détecter et à répondre à une chaîne d’attaque complexe composée de plusieurs étapes.
Par ailleurs, les tests unitaires introduisent plusieurs biais susceptibles d’altérer le réalisme des évaluations de détection. Ils nécessitent notamment la collaboration d’un « complice »de la Blue Team, chargé de fournir l’assistance nécessaire et d’éviter une escalade excessive. Cette approche limite l’identification de certaines lacunes dans les processus de réponse à incident et réduit fortement la discrétion de l’exercice.
Enfin, une fois que le SOC sait qu’un exercice Purple Team est en cours, sa réaction devient inévitablement biaisée. En l’absence de l’effet de surprise et de la pression propres à un incident réel, ces tests ne permettent pas d’évaluer fidèlement la manière dont le SOC réagirait face au stress et à l’ambiguïté d’une intrusion réelle en cours.
Exercices orientés trophées
Notre seconde approche, les exercices orientés trophées, permet d’évaluer les capacités de détection au travers de scénarios plus réalistes. Ces opérations s’adressent à des organisations matures et visent à évaluer et renforcer les processus de détection avancés ainsi que les capacités de Threat Hunting, plutôt que de simplement valider des règles de détection automatisées.
À l’image d’une opération Red Team, l’équipe offensive mène une attaque à grande échelle contre le système d’information sans suivre une liste de tests prédéfinie, mais en poursuivant des objectifs (trophées) définis à l’avance. Cette approche permet notamment d’identifier des scénarios d’attaque de bout en bout.
Dans la pratique, nos exercices orientés trophées s’appuient souvent sur une approche Red to Purple : tant que l’équipe Red Team n’a pas été détectée, la Blue Team n’est pas informée de l’exercice, ce qui favorise des réactions authentiques et non scénarisées. Cette approche offre une opportunité unique d’évaluer les réactions réelles des équipes de sécurité et de réduire l’écart entre les procédures théoriques et la gestion effective d’un incident.
Toutefois, contrairement aux tests unitaires, ces exercices ne cherchent pas à être exhaustifs. Leur objectif n’est pas de couvrir chaque règle de détection déployée dans l’environnement, mais plutôt d’évaluer la résilience globale de l’organisation face à un adversaire donné, en combinant l’évaluation des mécanismes de détection, des processus d’escalade, des capacités de Threat Hunting et de corrélation.
Ainsi, les exercices orientés trophées représentent l’aboutissement de la démarche Purple Team, en faisant évoluer la question de « Quelles sont nos lacunes de détection ? » vers « Un véritable attaquant serait-il réellement détecté ? ».
Évaluations SOC
Les évaluations de SOC visent à mesurer le niveau de préparation opérationnelle et la performance du SOC. Contrairement aux approches précédentes, qui se concentrent sur la validation des mécanismes de détection, elles évaluent la capacité des analystes et des processus à détecter, qualifier, investiguer et traiter les menaces. Elles permettent de vérifier que les procédures opérationnelles et les playbooks sont correctement appliqués, tout en identifiant les lacunes de visibilité dans les journaux et la télémétrie tout au long de la chaîne d’attaque.
Toutefois, les évaluations de SOC reposent souvent sur des scénarios structurés qui introduisent une certaine forme d’artificialité. L’évaluation reste fondamentalement un exercice de déclenchement et de réponse, enrichi par une validation des procédures et du facteur humain.
Parce que ces exercices reposent sur des déclencheurs connus et planifiés à l’avance, ils ne poussent pas les analystes à réaliser des corrélations approfondies ni à identifier des comportements anormaux à travers une multitude d’événements apparemment bénins. En ce sens, ils sont conçus pour évaluer « ce qui fonctionne aujourd’hui » plutôt que « ce qui devra fonctionner demain ».
Enfin, cette nature scénarisée laisse peu de place à un véritable Threat Hunting. En effet, le SOC n’est jamais amené à découvrir de manière proactive les objectifs ou le mode opératoire d’un adversaire sur la durée. En privilégiant l’exécution réactive de playbooks plutôt que l’ambiguïté propre à une campagne en constante évolution, ces évaluations passent à côté d’un aspect essentiel du facteur humain : la capacité à détecter une menace sophistiquée ne générant pas d’alerte prédéfinie ou particulièrement « bruyante ».
L’illusion de « L’instant T »
Malgré leurs différences, ces trois approches partagent une même limite fondamentale : elles évaluent le niveau de sécurité d’une organisation à un instant donné.
Les systèmes d’information modernes évoluent en permanence. Les migrations d’infrastructure, les transformations cloud, les déploiements applicatifs ou encore les modifications des outils de sécurité peuvent tous avoir un impact sur l’efficacité des capacités de détection et de réponse. Une règle de détection validée lors d’un exercice Purple Team peut ainsi ne plus fonctionner comme prévu à la suite d’un simple changement d’infrastructure.
Dans le même temps, les acteurs de la menace adaptent continuellement leurs tactiques, techniques et procédures. Avec l’émergence des attaques augmentées par l’intelligence artificielle, le paysage de la menace évolue en permanence : ce qui était considéré comme sécurisé hier peut devenir obsolète aujourd’hui.
Les organisations doivent donc réévaluer régulièrement leurs capacités défensives afin de s’assurer qu’elles restent alignées avec l’évolution des menaces.
Pourtant, le coût, la complexité et les efforts manuels associés aux exercices Purple Team traditionnels empêchent souvent les organisations de réaliser ces évaluations à la fréquence nécessaire. Il en résulte un décalage entre la validation de la sécurité et la réalité opérationnelle, laissant les défenseurs avec une vision uniquement ponctuelle de leur niveau réel de préparation face aux menaces.
Donner plus d’autonomie aux équipes de défense grâce à l’automatisation pilotée par la CTI
Les limites du Purple Teaming traditionnel soulèvent une question essentielle : comment permettre aux organisations de valider plus fréquemment leurs capacités de détection et de réponse sans augmenter significativement les coûts et la charge opérationnelle ?
La réponse consiste à passer d’évaluations orchestrées par une équipe dédiée à un processus de validation piloté par les défenseurs eux-mêmes. Plutôt que d’attendre des exercices Purple Team ponctuels, les équipes de sécurité doivent pouvoir évaluer en continu leurs capacités de détection et de réponse, dès que le besoin s’en fait sentir.
La CTI comme moteur du workflow
La Cyber Threat Intelligence (CTI) constitue une source précieuse d’informations sur les modes opératoires des acteurs de la menace. En documentant leurs tactiques, techniques et procédures (TTPs), la CTI permet aux organisations d’aller au-delà de simulations d’attaque génériques pour se concentrer sur des scénarios de menace réalistes et pertinents pour leur environnement.
Plutôt que d’être considérée comme un simple rapport consulté puis archivé, la CTI peut servir de fondation à des évaluations défensives répétables. Chaque nouvelle technique, campagne ou profil d’adversaire identifié devient alors une opportunité de valider les contrôles de sécurité existants et d’identifier d’éventuelles lacunes de détection.
Transformer les TTPs en scénarios automatisés
Si la CTI permet d’identifier les modes opératoires des adversaires, les organisations doivent encore disposer d’un moyen de reproduire ces comportements de manière contrôlée et répétable.
En transformant les TTPs documentés en scénarios d’attaque automatisés, les équipes de sécurité peuvent tester en continu leur capacité à détecter et à investiguer les activités associées à des acteurs de la menace spécifiques. Bien que ce travail de transformation ne doive être réalisé qu’une seule fois, les scénarios ainsi créés peuvent ensuite être exécutés de manière répétée avec un effort minimal, permettant aux organisations de valider leurs défenses à tout moment.
Cette approche réduit considérablement les efforts manuels traditionnellement requis pour préparer et conduire des exercices Purple Team, tout en garantissant la cohérence des évaluations dans le temps.
Permettre des évaluations défensives en toute autonomie
L’automatisation permet aux équipes de défense de gagner en autonomie. Au lieu de dépendre d’exercices externes ou de ressources Red Team dédiées, les défenseurs peuvent déclencher eux-mêmes des évaluations dès qu’un changement opérationnel le nécessite.
Par exemple, ces évaluations peuvent être lancées à la suite d’une migration d’infrastructure majeure, du déploiement de nouveaux contrôles de sécurité ou de la publication d’un renseignement CTI concernant un adversaire pertinent pour l’organisation.
Cette approche en libre-service permet aux organisations de valider leur posture de sécurité à la fréquence requise, en s’assurant que leurs capacités de détection restent alignées à la fois avec les évolutions de l’infrastructure et celles du paysage de la menace.
Dépasser les limites des solutions d’automatisation du marché : l’intégration Caldera & Mythic
Bien que des frameworks d’orchestration d’attaques existent déjà, ils présentent souvent certaines limites opérationnelles. Par exemple, Caldera repose sur des agents génériques qui n’implémentent pas des capacités avancées de commande et de contrôle (C2) telles que l’exécution de scripts PowerShell en mémoire, l’exécution d’Inline Assembly ou encore les Beacon Object Files (BOFs). Ainsi, bien que Caldera excelle dans l’automatisation de scénarios d’émulation d’adversaires, il ne permet pas toujours de reproduire fidèlement les techniques utilisées par des acteurs de la menace sophistiqués. De plus, dans les environnements où le réalisme constitue un objectif majeur, la présence et le comportement de l’agent Caldera peuvent permettre aux défenseurs d’identifier rapidement l’exercice, réduisant ainsi la fidélité de l’évaluation.
À l’inverse, les frameworks modernes de commande et de contrôle tels que Mythic offrent des capacités réalistes de simulation d’adversaires ainsi que des méthodes d’exécution avancées, mais ne disposent pas des fonctionnalités d’orchestration et d’automatisation nécessaires à la réalisation d’évaluations Purple Team répétables à grande échelle.
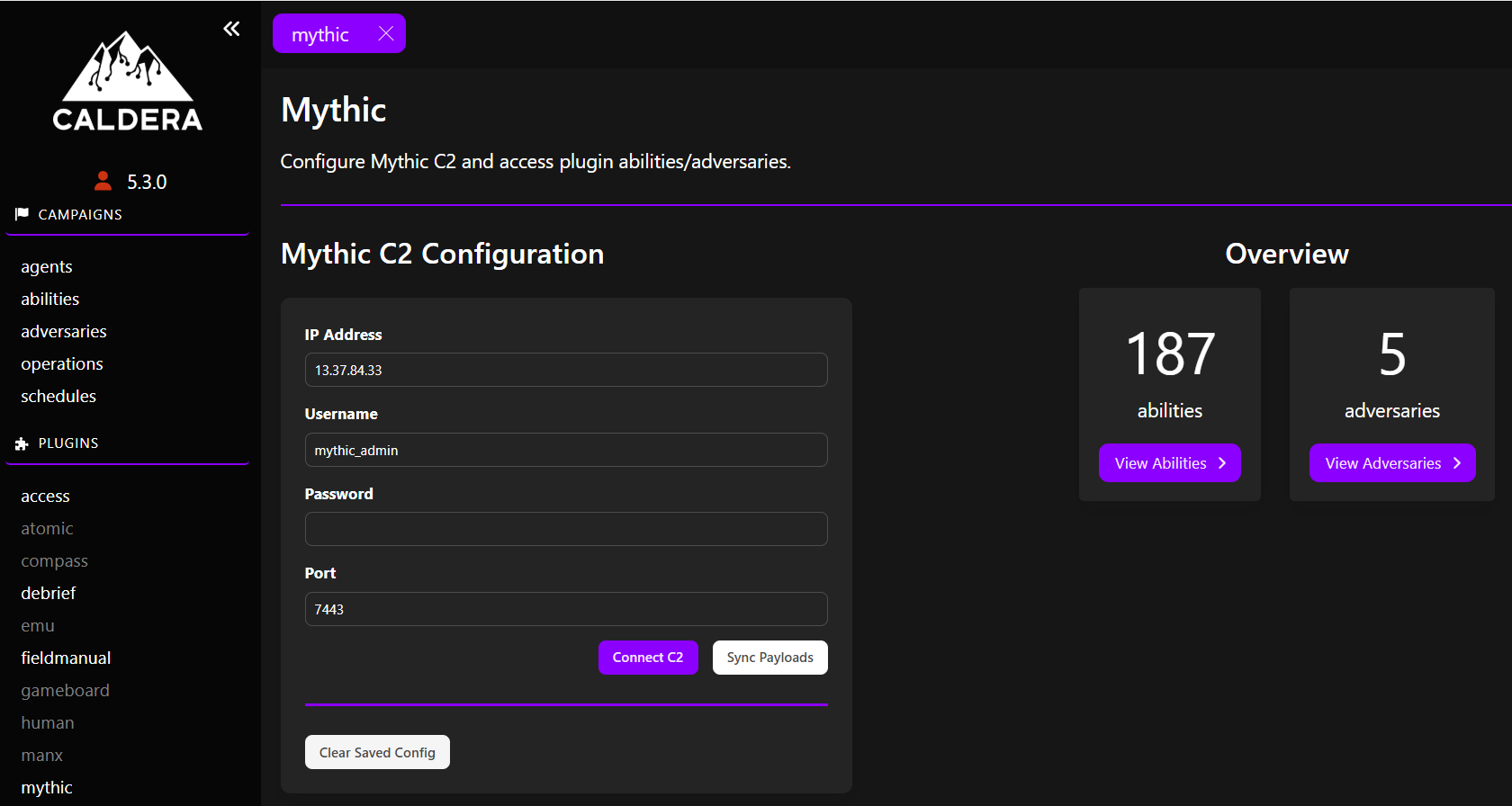
Afin de combler cet écart, nous avons développé le plugin Mythic pour Caldera, qui s’intègre directement au framework C2 Mythic. L’objectif était de combiner les capacités d’automatisation et d’orchestration de Caldera avec les capacités réalistes de commande et de contrôle offertes par Mythic. Dans cette architecture, Caldera conserve la responsabilité de l’orchestration des scénarios d’attaque pilotés par la CTI, tandis que Mythic fournit la couche d’exécution utilisée pour reproduire les techniques avancées des adversaires.
Cette intégration permet aux organisations d’automatiser des chaînes d’attaque complexes tout en conservant un niveau de réalisme plus proche de celui des intrusions observées dans le monde réel.
Plugin Mythic pour Caldera : bibliothèque d’émulation d’adversaires
Le plugin étend Caldera en intégrant le framework C2 Mythic et en fournissant des profils d’adversaires, des fact sources, des payloads et des parsers personnalisés. Ensemble, ces composants permettent aux opérateurs de transformer rapidement la CTI en scénarios automatisés d’émulation d’adversaires tout en réduisant significativement les efforts de configuration manuelle.
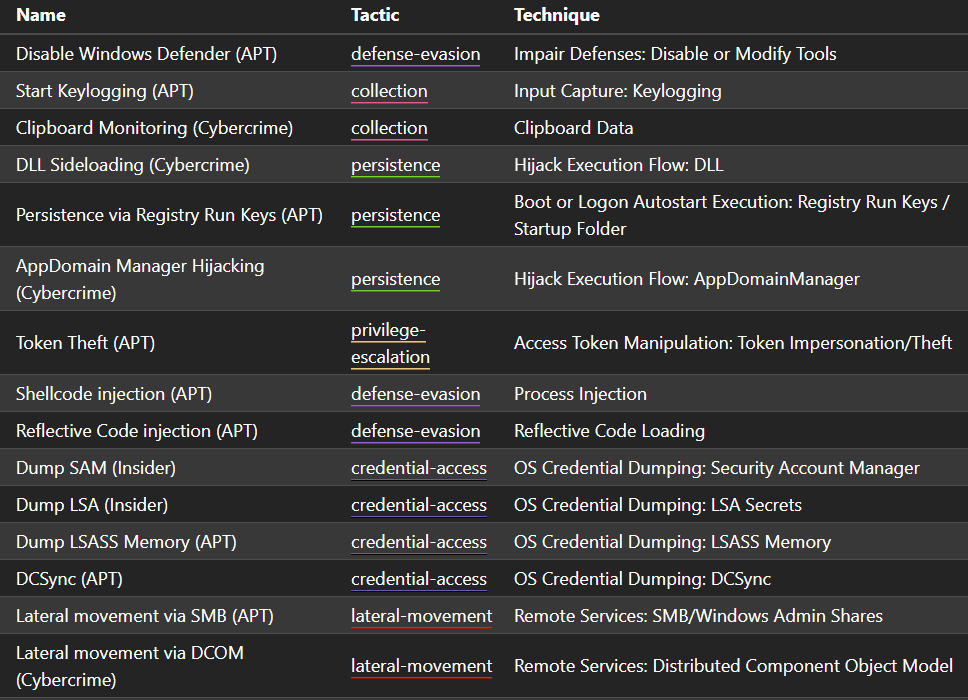
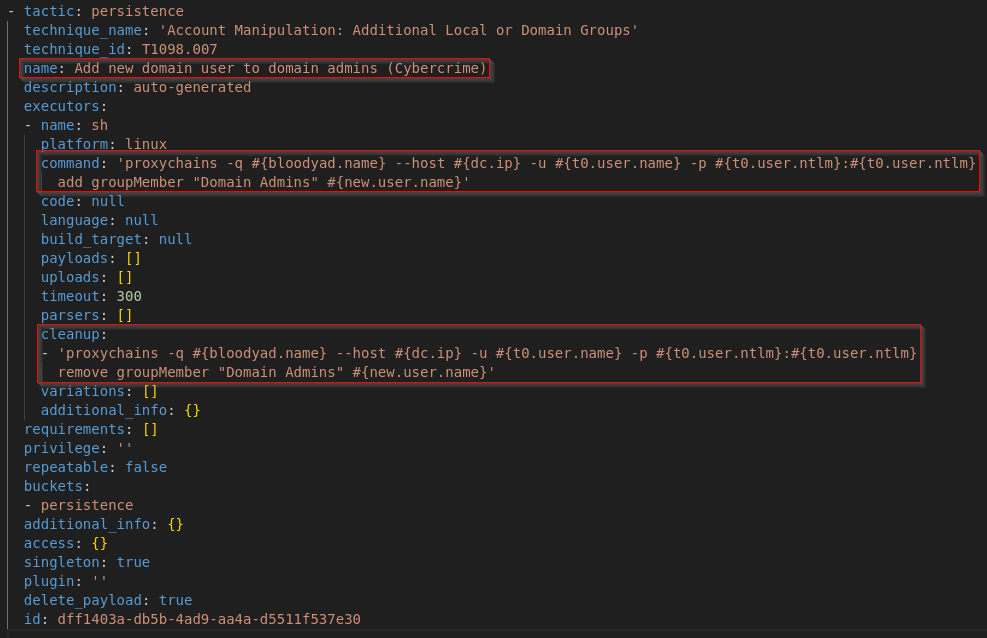
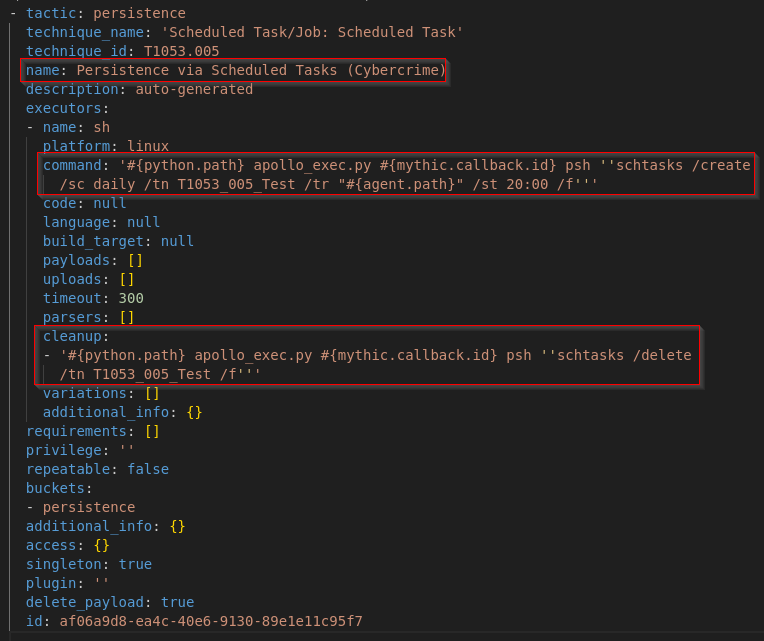
Le plugin intègre 5 profils d’adversaires personnalisés, chacun conçu pour émuler un modèle de menace distinct ainsi que les modes opératoires qui lui sont associés :
- Insider : simule un attaquant interne, tel qu’un administrateur Windows, avec des TTPs implémentés exclusivement à l’aide de living-off-the-land binaries (LOLBins) Windows.
- Cybercrime : simule un attaquant opportuniste s’appuyant sur des outils offensifs accessibles publiquement et des techniques d’attaque à distance opérées via l’infrastructure proxy SOCKS5 de Mythic.
- APT : simule un acteur de la menace sophistiqué utilisant des techniques avancées, notamment des appels bas niveau aux API Windows, les commandes natives d’Apollo ainsi que des mécanismes d’exécution de payloads en mémoire.
- Linux – Insider : simule un attaquant interne, tel qu’un administrateur Linux, avec des TTPs implémentés exclusivement à l’aide de commandes et d’utilitaires natifs Linux.
- Linux – Cybercrime : simule un attaquant opportuniste ciblant les environnements Linux, avec des TTPs implémentés à l’aide d’outils offensifs open source couramment utilisés.
Afin de faciliter la réutilisation des scénarios, le plugin s’appuie sur les fact sources de Caldera pour paramétrer dynamiquement les abilities. Au lieu de coder en dur des valeurs propres à un environnement donné, des informations telles que les noms de domaine, adresses IP, identifiants, payloads ou paramètres opérationnels sont injectées au moment de l’exécution. Cette approche permet de réutiliser un même profil d’adversaire dans plusieurs environnements avec très peu de modifications.
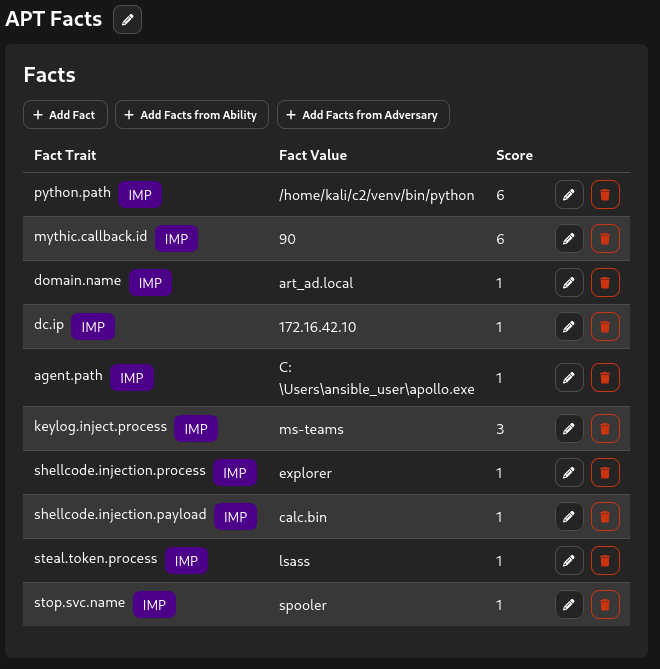
La bibliothèque inclut également un ensemble de payloads et de parsers utilisés pour prendre en charge des simulations d’attaque avancées. Les payloads sont automatiquement synchronisés avec Mythic et peuvent être utilisés par les abilities lors de l’exécution des opérations. Les parsers, quant à eux, permettent d’extraire dynamiquement des informations à partir des sorties de commandes et de les transformer en facts pouvant être exploités par les abilities suivantes.
Enfin, le plugin fournit une bibliothèque qui continue de s’enrichir, comprenant aujourd’hui plus de 180 abilities réutilisables couvrant une grande variété de techniques ATT&CK. Ces abilities peuvent être regroupées au sein de profils d’adversaires ou exécutées individuellement afin de valider des mécanismes de détection ou des procédures de réponse spécifiques.
Plugin Mythic pour Caldera : intégration Caldera-Mythic
Au cœur de l’intégration se trouvent deux interfaces en ligne de commande (CLI) : apollo_exec.py et athena_exec.py. Ces CLI interagissent avec l’API de Mythic et sont utilisées par l’agent Caldera Sandcat afin de piloter les agents Apollo (Windows) et Athena (Linux).
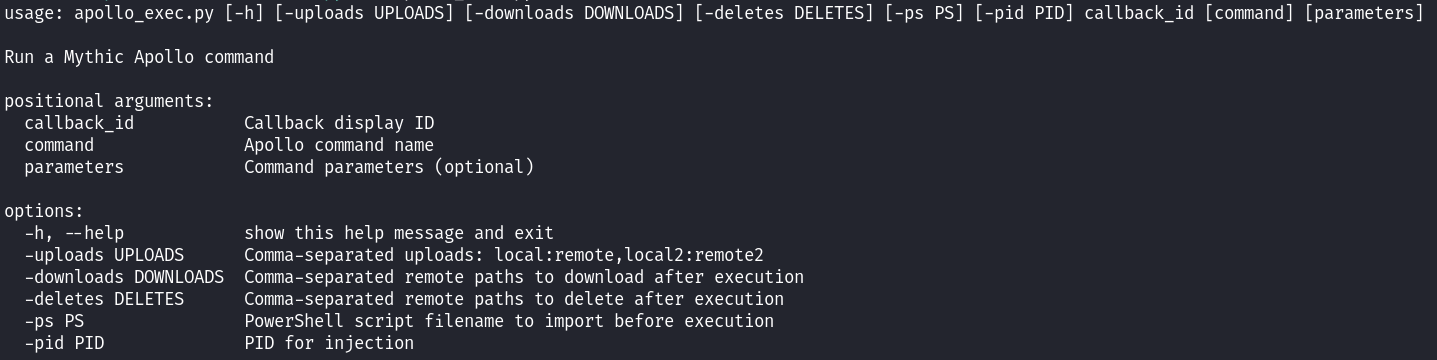
Par exemple, la CLI Apollo prend en entrée un identifiant de callback Mythic, une commande ainsi que des arguments optionnels, et prend en charge plusieurs options supplémentaires permettant d’étendre les capacités d’exécution :
-
-uploads: téléverse des fichiers avant l’exécution
-
-downloads: récupère des fichiers après l’exécution
-
-deletes: supprime des fichiers après l’exécution
-
-ps: charge un script PowerShell en mémoire avant l’exécution
-
-pid: spécifie l’identifiant du processus cible pour une injection de processus
Afin de faciliter l’interaction entre Caldera et Mythic, le plugin implémente deux fonctionnalités principales :
- Connect C2 : génère les CLI py et athena_exec.py à partir des paramètres de configuration du C2 Mythic afin de permettre la communication avec l’API de Mythic.
- Sync Payloads : enregistre automatiquement dans Mythic les payloads requis par les opérations Caldera, notamment les assemblages .NET, les DLL, les exécutables et les Beacon Object Files (BOFs).
Plugin Mythic pour Caldera : workflow d’exécution
Au sein de notre workflow, MITRE Caldera est utilisé comme plateforme d’orchestration plutôt que comme serveur traditionnel de commande et de contrôle (C2). L’agent Caldera (Sandcat) est déployé sur le même hôte que le serveur Caldera et est chargé de coordonner l’exécution des scénarios d’attaque. Au lieu d’exécuter directement les abilities, il délègue leur exécution à l’infrastructure C2 Mythic.
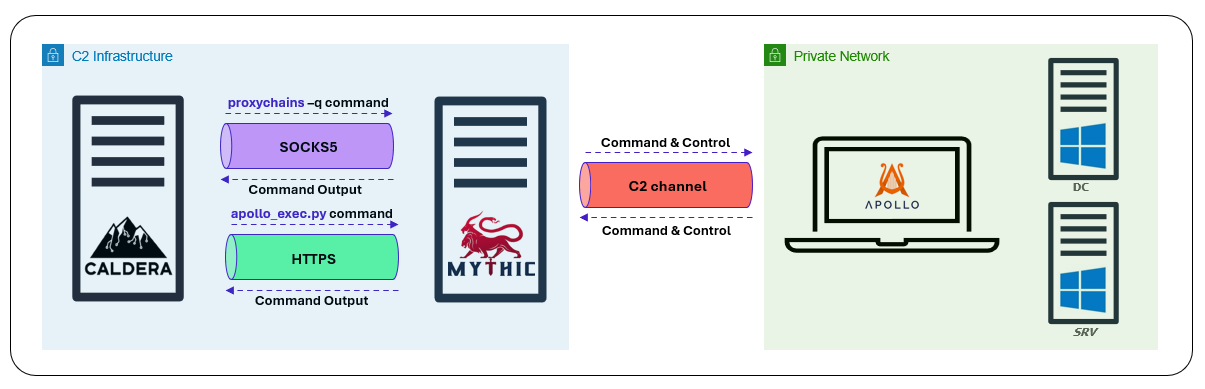
Selon la nature de la technique exécutée, les TTPs sont pris en charge selon l’un des deux modes d’exécution suivants:
- Attaques réseau : les TTPs orientés réseau, tels que les mouvements latéraux ou les interactions avec des services distants, sont exécutés par l’agent Caldera via un proxy SOCKS5 exposé par Mythic. Le trafic est routé à travers l’agent Apollo à l’aide d’outils tels que proxychains.
- Attaques exécutées sur l’hôte : les TTPs ciblant directement les systèmes compromis sont exécutés par les agents Mythic. Dans ce scénario, l’agent Caldera s’appuie sur la CLI apollo_exec.py pour interagir avec l’API Mythic et transmettre les tâches à l’agent Apollo, qui se charge d’exécuter l’action demandée.
Mesurer objectivement la progression du SOC avec VECTR
L’une des principales limites d’outils tels que Caldera réside dans leur conception centrée sur les équipes Red Team. Bien qu’ils excellent dans l’orchestration et l’exécution d’attaques, ils ne fournissent pas d’interface adaptée aux analystes Blue Team pour consulter, enrichir et suivre les résultats des évaluations. Par conséquent, l’accès aux résultats des exercices Purple Team et leur interprétation peuvent rapidement devenir fastidieux, en particulier lorsque plusieurs opérations sont menées dans le temps.
Pour répondre à ce besoin, nous avons intégré VECTR à notre workflow. VECTR est une plateforme Purple Team conçue pour centraliser les données d’attaque et de détection, offrant une vision commune aux équipes Red Team et Blue Team. En corrélant les actions des adversaires avec les observations défensives, elle permet aux organisations de mesurer objectivement leurs capacités de détection et d’en suivre l’évolution dans le temps.
Afin de faciliter ce processus, nous avons développé le plugin VECTR pour Caldera. Une fois déclenché par l’opérateur, le plugin exporte automatiquement les opérations terminées vers VECTR sous forme de campagnes, permettant la génération automatique de graphes d’attaque et de matrices MITRE ATT&CK tout en éliminant plusieurs heures de travail de reporting manuel.
Plugin VECTR pour Caldera : création de campagnes
Le plugin étend Caldera en exportant les opérations terminées sous forme de campagnes VECTR. Lors du processus d’export, le plugin transfère les étapes de l’opération, leur statut d’exécution, les commandes exécutées, les correspondances avec les techniques MITRE ATT&CK, les timestamps ainsi que les sorties de commandes (stdout/stderr).
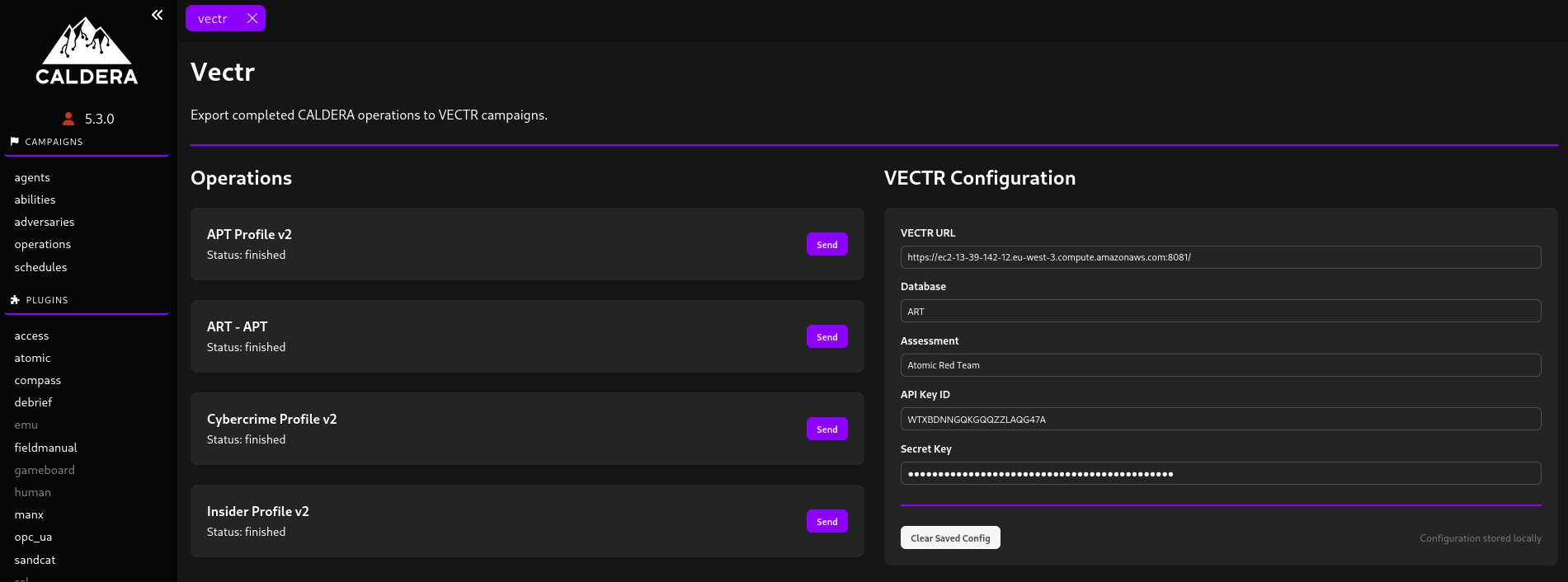
Le plugin affiche les opérations Caldera disponibles ainsi que leur statut d’exécution. Une fois une opération terminée, l’opérateur peut déclencher son export vers VECTR en un seul clic après avoir renseigné les paramètres de connexion. Le processus d’export est exécuté de manière asynchrone afin de ne pas bloquer le thread d’exécution de Caldera.
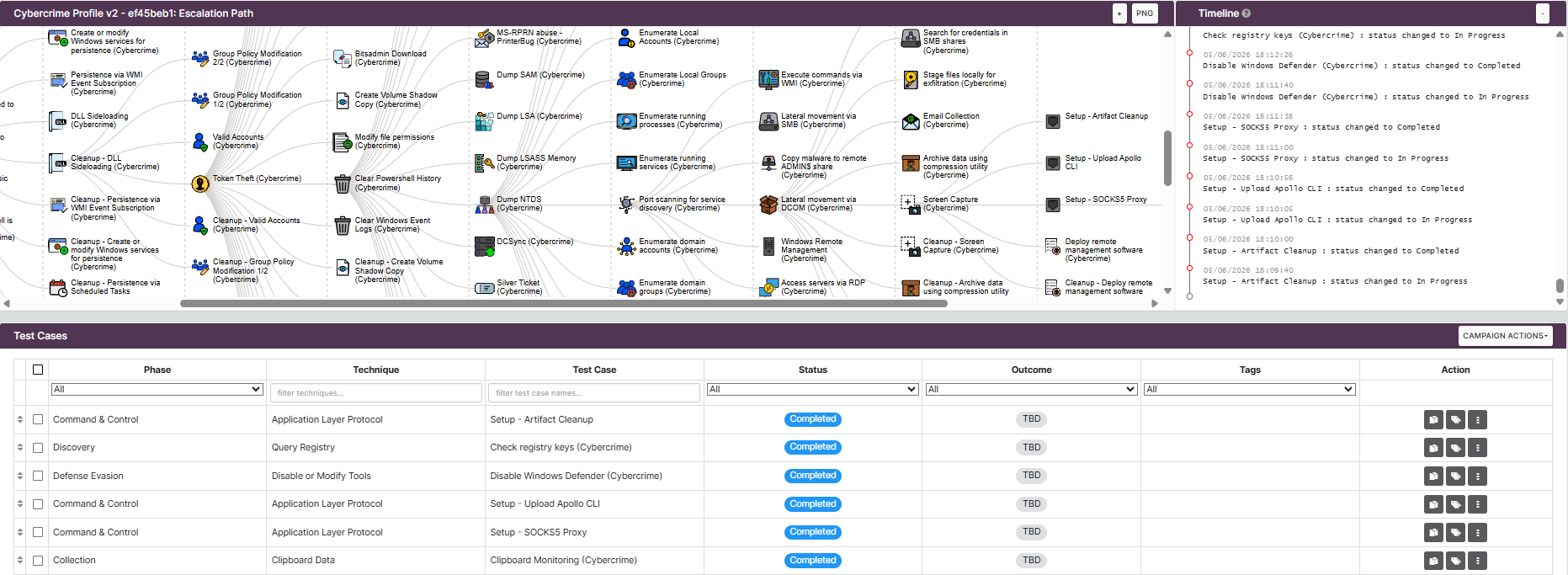
Une fois exportée, l’opération apparaît sous la forme d’une campagne dans VECTR. Afin de garantir l’unicité des campagnes et d’assurer la traçabilité entre les deux plateformes, le nom de la campagne est composé du nom de l’opération Caldera suivi des huit premiers caractères de son identifiant.
Plugin VECTR pour Caldera : enrichissement des campagnes
Chaque ability incluse dans une opération Caldera est associée à un test case correspondant au sein de la campagne VECTR. Ainsi, chaque test case est automatiquement enrichi avec les informations Red Team pertinentes, notamment la technique ATT&CK associée, le statut d’exécution, les timestamps, les commandes exécutées ainsi que les métadonnées opérationnelles :
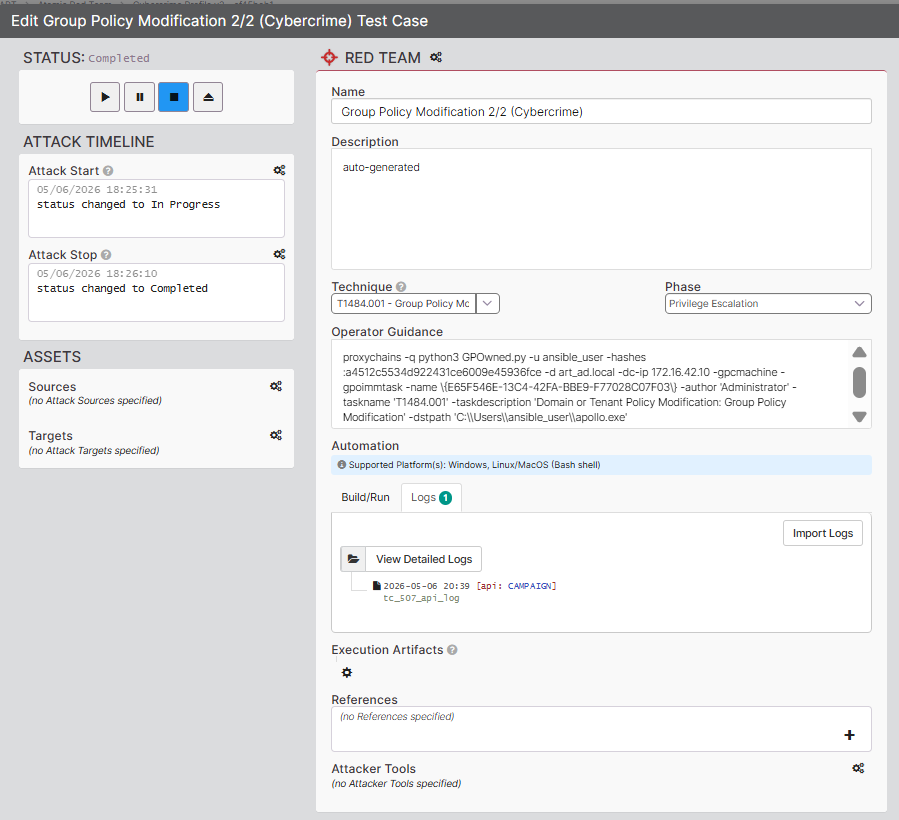
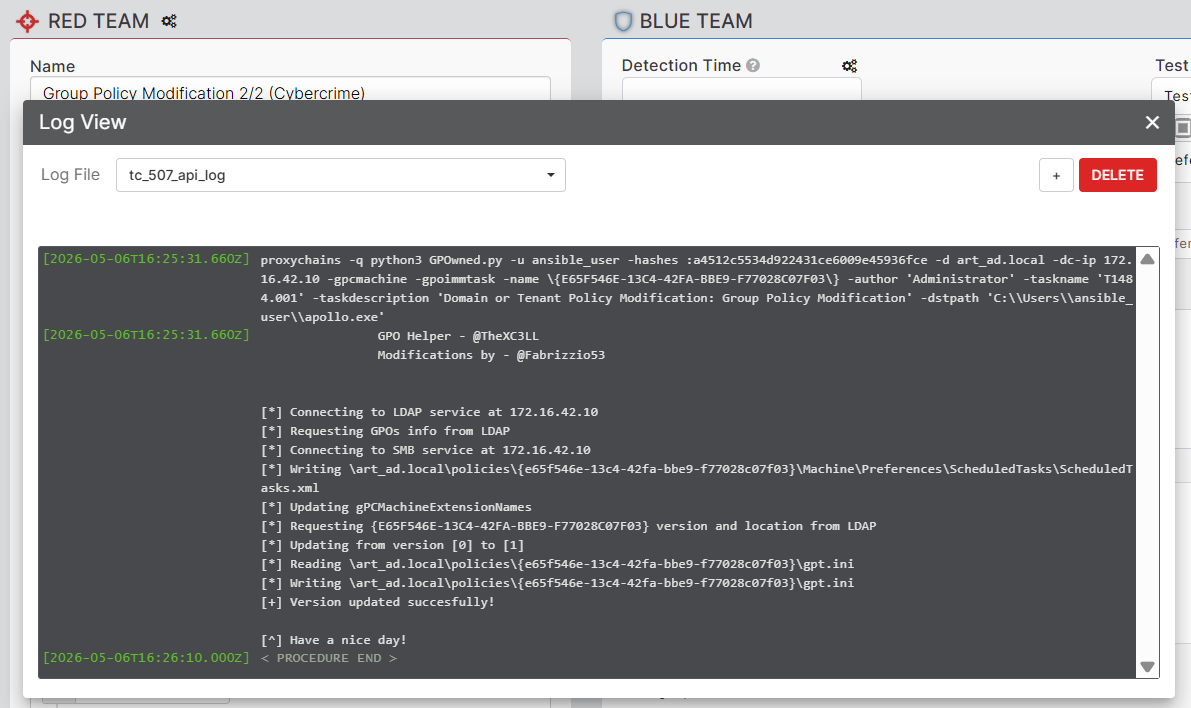
Pour les abilities qui ont été exécutées, les sorties de commandes (stdout/stderr) sont exportées vers VECTR et associées sous forme de journaux Red Team. Ces journaux offrent aux analystes une visibilité détaillée sur les actions réalisées au cours de l’évaluation et peuvent être consultés afin de mieux comprendre le déroulement de l’exécution ainsi que d’identifier d’éventuelles opportunités d’amélioration des capacités de détection.
Mise en pratique : démonstration de bout en bout
La vidéo suivante rassemble l’ensemble des composants présentés dans cet article et illustre un workflow automatisé de Purple Team de bout en bout, depuis l’émulation automatisée d’adversaires avec Caldera et Mythic jusqu’à la visualisation des activités adverses et des résultats opérationnels dans VECTR.
Vers une automatisation complète du Purple Teaming
Bien que ce workflow réduise considérablement les efforts nécessaires à la réalisation d’évaluations Purple Team, une étape manuelle subsiste : la transformation de la CTI en abilities Caldera exécutables et en profils d’adversaires.
Aujourd’hui, ce processus nécessite qu’un analyste examine les rapports de CTI, identifie les TTPs pertinents et implémente manuellement les abilities correspondantes au sein de la bibliothèque d’émulation d’adversaires. Bien que ce travail ne doive être réalisé qu’une seule fois pour chaque technique, il reste dépendant de l’expertise humaine et peut devenir chronophage lorsqu’il s’agit d’opérationnaliser de grands volumes de CTI.
Les travaux futurs porteront sur l’utilisation de l’intelligence artificielle afin d’automatiser cette étape. En combinant les grands modèles de langage (LLMs), la connaissance d’ATT&CK et des modèles d’abilities existants, les rapports de CTI pourraient être automatiquement transformés en abilities Caldera exécutables, accélérant considérablement l’opérationnalisation de la CTI tout en réduisant davantage les efforts nécessaires au maintien d’une bibliothèque d’émulation d’adversaires à jour.
Cette évolution permettrait de compléter la chaîne d’automatisation, en permettant aux organisations de passer de l’acquisition de la CTI à l’émulation automatisée d’adversaires et à l’évaluation du SOC de manière quasi autonome.

