
If 10 years ago, building your SOC meant asking yourself which scenarios to monitor, which log sources to collect and which SIEM to choose, recent developments in the IS have brought new challenges: how to set up monitoring in a partially on-premise and/or multi-cloud environment? Indeed, in 2021, having an IS hosted by several IaaS providers is closer to being the rule than the exception; and while AWS remains the most popular player, Azure and GCP offerings are of increasing interest to IT teams.
How to build a detection strategy? Where to position the SIEM? How to centralize logs and alerts? In fact, do we need logs or alerts? And how to take advantage of the managed solutions offered by cloud providers?
In this article, we will discuss best practices: using a bottom-up detection strategy, optimizing via the choice of the most relevant cloud native services, simplifying the collection architecture; always based on feedback from building multi-cloud monitoring strategies.
(Re)thinking your detection strategy for the multicloud
The first question the SOC team should ask itself is the detection strategy. In other words, what scenarios will be monitored?
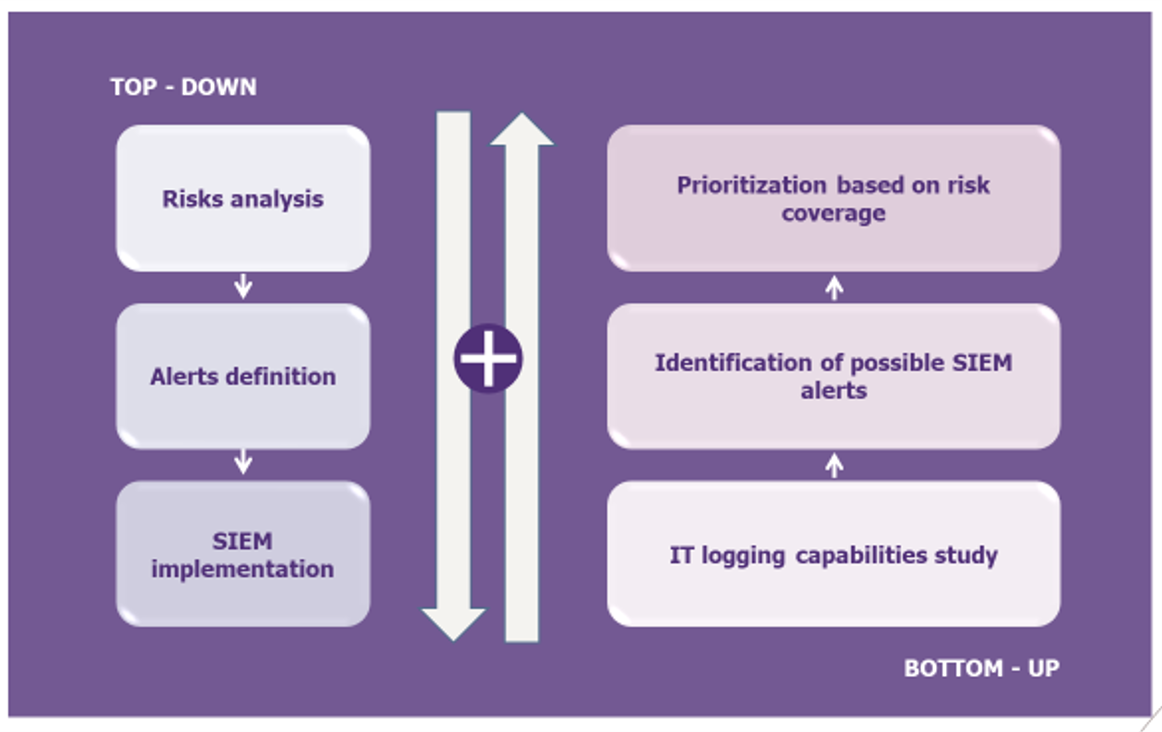
A good cyber reflex is to use a “top-down” approach: start with a risk analysis to identify the alerts to prioritize, formalize them and then translate them technically into the SIEM. In practice, three factors demonstrate that this approach is insufficient:
- Few teams have risk analyses that are sufficiently exhaustive, up to date and pragmatic to allow the breakdown of threat scenarios into monitorable scenarios, especially for complex scopes such as the public cloud;
- There is no guarantee that the scenarios obtained by this method can actually be put under supervision, whether the limitations are related to the solutions deployed or to the need for SOC teams to have business knowledge.
- This approach defines some attack paths according to the criticality of the assets but does not cover all the attack paths that an attacker could take.
Therefore, an efficient multi-cloud detection strategy will be obtained by completing the risk-based approach with a “bottom-up” approach: starting from the logging capabilities of the solutions available to identify the alerts that the SIEM will have to raise, and finally prioritize based on their interest in terms of risk coverage. Starting with the existing solutions guarantees the pragmatism and efficiency of the approach.
At Wavestone, we are increasingly solicited by clients who want to be supported in this new approach. The scope concerns the main solutions used in multicloud: Microsoft 365 (SaaS) and the managed solutions of the IaaS offers of the 3 main market players: Amazon Web Services, Microsoft Azure and Google Cloud Platform.
Set up the supervision of the Microsoft 365 infrastructure
On paper, the SOC team has all the keys in hand to monitor its cloud infrastructure:
– Raw logs for Office 365 services (Teams, SharePoint Online, Exchange Online, etc.)
– Raw logs, security reports, alerts and Identity Secure Score for Azure AD
– Raw logs, alerts, Microsoft Secure Score and Azure recommendations for security tools like ATP, AAD Identity Protection, Intune, AIP, etc.
In practice, navigating between the logs and all the tools available (and their consoles) can quickly become a headache. And if we regularly hear that there are too many logs or administration interfaces to master, in the field the difficulties are accentuated:
– By the poor customization capabilities of the native tools offered,
– By the lack of scenarios available with the purchased license,
– By the 90-day retention period for logs,
– By the general lack of Office 365 or AzureAD skills in the SOC teams.
To avoid getting lost, we recommend simplifying the playing field as much as possible. The best practices consist in thinking about alerts, not logs collection, and then centralizing their management in the SIEM using connectors like those of Security Graph API. As an example, it is possible to arrive at a model like the one given below:
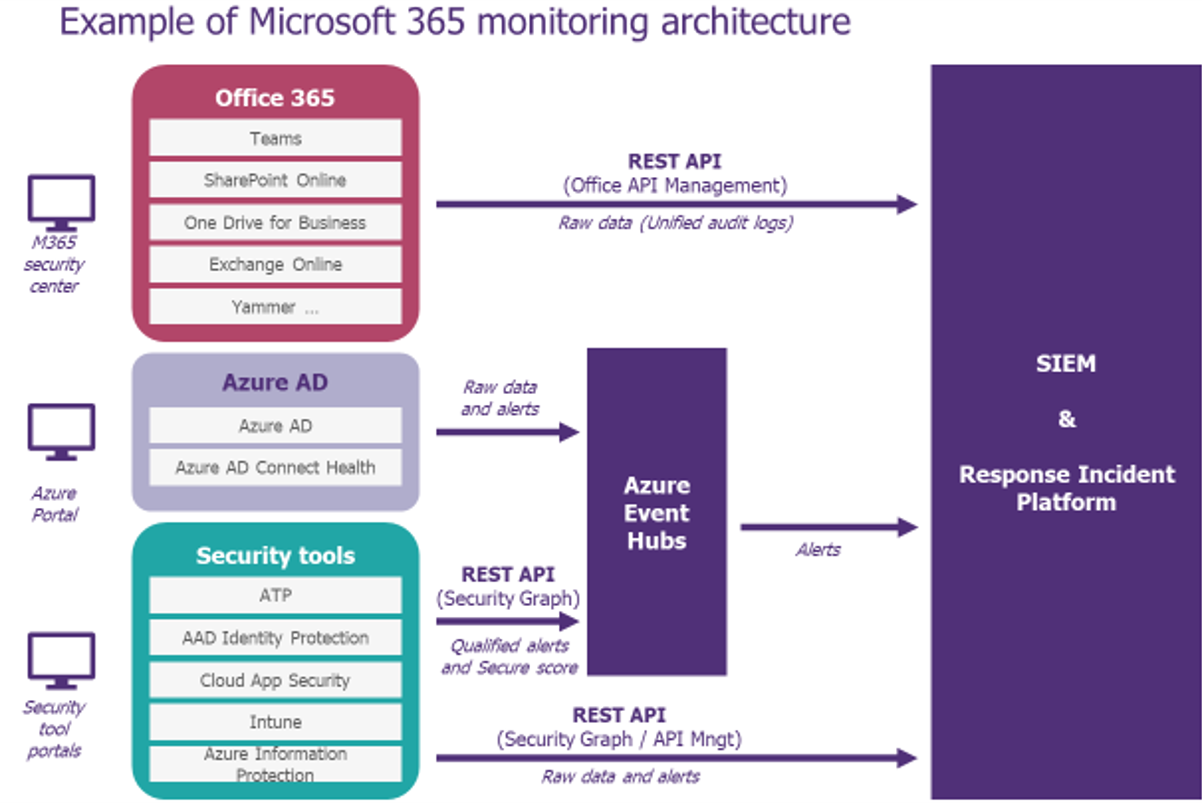
Once the architecture has been identified, configure a log retention period adapted to your needs (within Azure or outside) and start adapting the SOC processes to the specificities of M365 according to the choices made in the previous step.
Set up the supervision of other clouds in IaaS
To draw the architecture of collection on these clouds, it is necessary to distinguish the different types of logs made available by the CSPs.
System logs
The case of system logs generated by VMs and network flows can be dealt with first; it is possible to collect them in the same way as on-premise, with syslog agents, for example. CSP infrastructures provide building blocks such as Log Analytics in Azure to facilitate reporting.
Infrastructure administration logs
It is also possible to supervise the administration of “sensitive” infrastructure components (VPN, FW, vulnerability scanners, etc.) in the same way as on-premise solutions. Indeed, most of these solutions have their IaaS counterpart in the cloud providers: they can be obtained via the Marketplace and have a web administration console or interface directly with the CSP’s management console (this is the case for the Qualys scanner appliance, for example).
API call logs
Finally, API calls made by processes/accounts on the cloud infrastructure and by administration operations generate logs that are easily retrievable via the following managed services:
– CloudTrail at AWS
– Activity Log & Monitor at Azure
– Audit Logging at GCP
To avoid getting lost, let’s learn the lesson: “Use and abuse cloud-native services”. After all, who better than the provider to offer services that are adapted and integrated into the environment? In practice, we see that implementing log management and cloud alerts in an on-premise SIEM is expensive (even if we try to limit storage costs in the monitoring solution) and time-consuming.
The use of the cloud implies a shift to the cloud philosophy: let’s adopt its codes and tame its services and tools. This is an opportunity to strengthen the synergies between the cloud teams and the SOC!
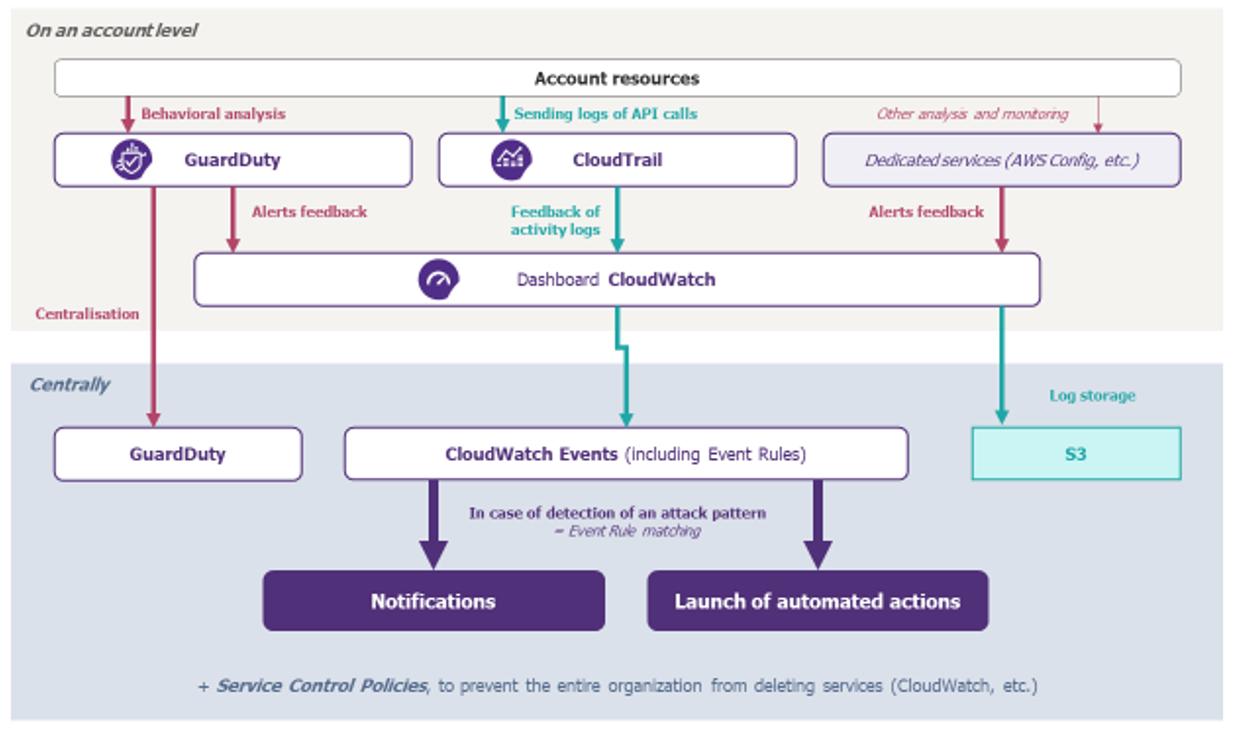
In summary, an example of monitoring architecture on AWS is proposed below. It shows several ways to perform monitoring, using native services for logs and alerts (NB: all flows to S3 and other services have not been shown for readability reasons).
Define the architecture for centralizing multi-cloud alerts
This is one of the questions we are asked the most: what SIEM architecture should be considered in the multi-cloud? While each context is different, because each IT infrastructure has its own legacy and history, the presence of so many resources and tools should lead an SOC team to consider adopting a central cloud SIEM (such as Azure Sentinel, Splunk SaaS, etc.; AWS and Google’s Chronicle do not offer an equivalent solution to date).
To help SOC teams choose the right scenario, our recommendations are as follows:
– Prefer the scenario with a single central SIEM
– Limit the number of cloud monitoring consoles as much as possible
– Maximize the number of alerts that have already been analyzed by the native services studied above
– Take advantage of possible synergies between products from the same supplier: Azure Sentinel for monitoring Microsoft 365 infrastructure, for example
– Take advantage of the numerous connectors made available by cloud SIEM providers
– Study the impact of each scenario on the organization of the SOC (team size, technological skills, etc.) and the associated costs (necessary developments, volume and ingestion costs, etc.)
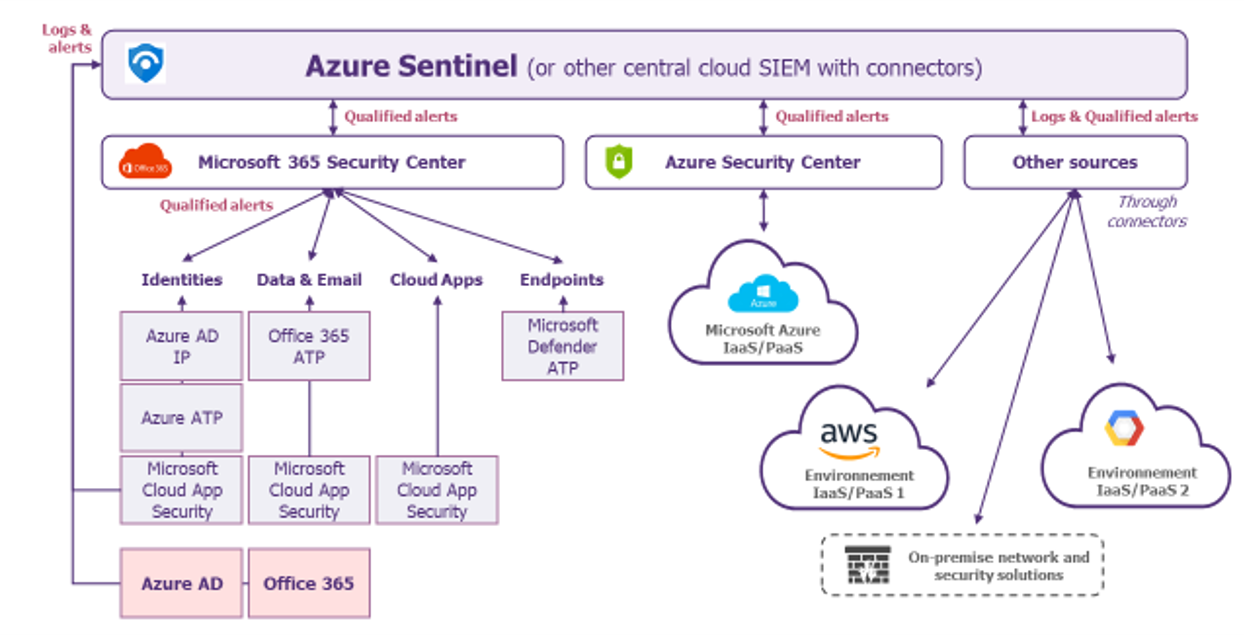
An example of an architecture that includes all the recommendations of this article is proposed below, it uses Azure Sentinel as a central cloud SIEM.
Summary: Key principles to keep your head above the clouds
In summary, the SOC team wanting to adapt its detection strategy to the multicloud should:
– Complement its classic top-down approach with the bottom-up approach, which is particularly well-suited to the complex context of the multicloud,
– Use native services provided by vendors whenever possible to take full advantage of the cloud,
– Simplify the collection architecture and centralize as much as possible the alerts pre-analyzed by the cloud native services,
Once the head is out of the cloud, the strategy formalized and the collection architecture deployed, the SOC is back in its place as the IS control tower: the proliferation of services in the cloud no longer scares it!
The next steps may be to look at automation possibilities, with the implementation of a SOAR, for example. We will be sure to discuss this topic in a future article.

