
In November 2022, the conversational agent ChatGPT developed by OpenAI was made accessible to the general public. Since then, it’s an understatement to say that this new tool has garnered interest. Just two months after its launch, the tool became the fastest-growing application in history, with nearly 100 million active users per month (a record later surpassed by Threads).
As users have adopted this product en masse, it now raises several fundamental cybersecurity questions.
Should companies allow their employees – specifically development teams – to continue using this tool without any restrictions? Should they suspend its usage until security teams address the issue? Or should it be outright banned?
Some companies like J.P. Morgan or Verizon have chosen to prohibit its usage. Apple initially decided to allow the tool for its employees before reversing its decision and prohibiting it. Amazon and Microsoft have simply asked their employees to be cautious about the information shared with OpenAI.
The most restrictive approach of blocking the platform avoids all cybersecurity questions but raises other concerns, including team performance, productivity, and the overall competitiveness of companies in rapidly changing markets.
Today, the question of blocking AI in IT remains relevant. We propose to provide some answers to this question for a population particularly concerned with the issue: development teams.
ChatGPT, Personal Information Collection, and GDPR
OpenAI’s product is freely accessible and usable under the condition of creating a user account. It’s a known trend: if an online tool is free, its source of revenue doesn’t come from access to the tool. For the specific case of ChatGPT, the information from the history of millions of users helps improve the platform and the quality of the language model. ChatGPT is a preview service: any data entered by the user may be reviewed by a human to improve the services.
Currently, ChatGPT doesn’t seem compliant with GDPR and data protection laws, but no legal decision has been made. The terms and conditions currently don’t mention the right to limitation of processing, the right to data portability, or the right to object. The US-based company OpenAI doesn’t mention GDPR but emphasizes that ChatGPT complies with “CALIFORNIA PRIVACY RIGHTS.” However, this regulation only applies to California residents and doesn’t extend beyond the United States of America. OpenAI also doesn’t provide a solution for individuals to verify if the editor stores their personal data or to request its deletion.
When we delve into ChatGPT’s privacy policy we can understand that:
- OpenAI collects user IP addresses, their web browser type, and data and interactions with the website. For example, this includes the type of content generated with AI, use cases, and functions used.
- OpenAI also collects information about users’ browsing activity on the web. It reserves the right to share this personal information with third parties, without specifying which ones.
All of this is done with the goal of improving existing services or developing new features.
Turning back to developer populations, today we observe that the majority of code is written collaboratively using Git tools. Thus, it’s not uncommon for a developer to have to understand a piece of code they didn’t write themselves. Instead of asking the original author, which can take several minutes (at best), a developer might turn to ChatGPT to get an instant answer. The response might even be more detailed than what the code’s author could provide.
|
As a result, it’s more than necessary to anonymize the elements shared with the Chatbot. Otherwise, some individuals might gain unauthorized access to confidential data. Thus, if a developer wants to understand the functionalities of a piece of code they’re not familiar with using ChatGPT’s help, they should:
|
Classic Attacks on AI Still Apply
Today, over half of companies are ready and willing to invest in and equip themselves with tools based on artificial intelligence. Consequently, it will become increasingly important for attackers to exploit this kind of technology. This is especially considering that cybersecurity as a notion is often overlooked when discussing artificial intelligence.
OpenAI’s AI isn’t immune to poisoning attacks. Even if the AI is trained on a substantial knowledge base, it’s unlikely that all of that knowledge has undergone manual review. If we return to the topic of code generation, it’s plausible that based on certain specific inputs, the AI might suggest code containing a backdoor. While this scenario hasn’t been observed, it’s not possible to prove that it won’t occur for a specific user input.
We can also assume that the tool has been trained only on relatively safe web sources. The Large Language Model (LLM) on which ChatGPT is based: GPT3, could be susceptible to “self-poisoning.” As GPT3 is used by millions of users, it’s highly likely that text generated by GPT3 ends up in trusted internet content. The training of GPT4 could theoretically contain text generated by GPT3. Thus, the AI might learn from knowledge generated by previous versions of the same LLM model. It will be interesting to see how OpenAI addresses the poisoning issue as the model evolves.
Poisoning is one technique for adding backdoors to AI-generated code, but this isn’t the only attack vector. It’s also possible that compromising OpenAI’s systems could allow modifying ChatGPT’s configuration to suggest code containing backdoors under specific conditions. A malicious attacker might even filter based on the user account identity of ChatGPT (e.g., an account ending with @internationalfirm.com) to decide whether to generate code containing backdoors and other vulnerabilities. Thus, it’s necessary to remain vigilant about OpenAI’s security level to prevent any rebound compromise.
ChatGPT and Code Generation
Code generation via ChatGPT is one of the features that can save developers the most time on a daily basis. For instance, a developer could ask to write a code skeleton for a function and then complete/correct the AI’s errors as needed. The main risk introduced by this practice is the insertion of malicious code into an application.
However, the risk existed well before ChatGPT. A malicious developer could very well obfuscate their code and deliberately insert a backdoor into an application. However, the introduction of AI brings a new dimension to the risk since a well-intentioned user might inadvertently introduce a backdoor. This needs to be considered in the context of the organization’s maturity regarding its CI/CD pipeline. Conducting SAST, DAST scans, and various audits before production helps reduce the risk.
We have observed that code generation via ChatGPT does not follow security best practices by default. The tool can generate code using insecure functions like scanf in C programming language. We provided the following query to the tool: “Can you write a function in C language that creates a list of integers using user inputs?” (initially prompted in French).
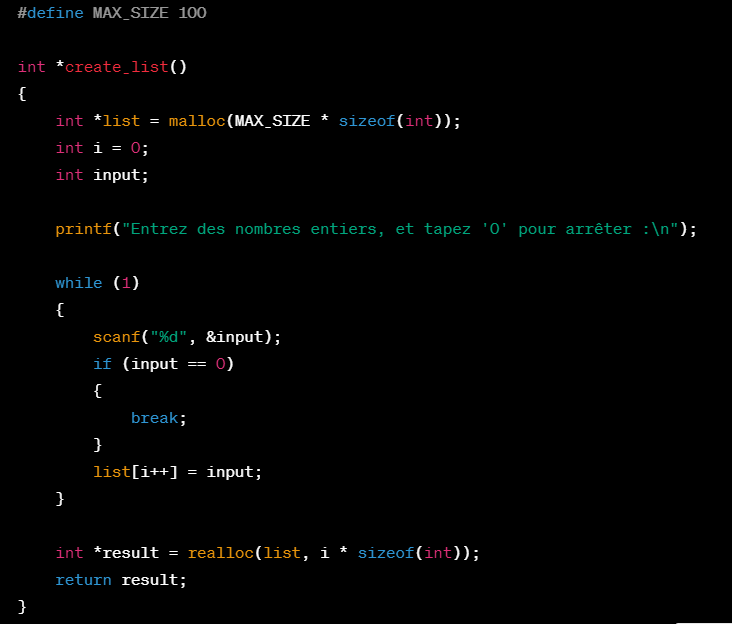
Code generated by ChatGPT following the described user input
Analyzing the code generated by ChatGPT, among other things, we notice three significant vulnerabilities:
- To begin, the use of the scanf function allows the user to enter any input length (int overflow…). There’s no validation of the user’s input, which remains a key vulnerability type highlighted by the OWASP TOP10.
- Additionally, the function is sensitive to buffer overflow: beyond the 100th input, the list “list” no longer has space to store additional data, which can either end execution with an error or allow a malicious user to write data in a memory area that’s not authorized, to take control of program execution.
- Finally, ChatGPT allocates memory to the list via the malloc function but forgets to free the memory once the list is no longer used, which could lead to memory leaks.
So, by default, Chat GPT does not generate code securely, unlike an experienced developer. The tool proposes code containing critical vulnerabilities. If the user is cybersecurity-aware, they can ask ChatGPT to identify vulnerabilities in their own code. ChatGPT is fully capable of detecting some vulnerabilities in the code generated by itself.

ChatGPT is able to detect vulnerabilities in code it has generated.
To summarize, code generation via ChatGPT doesn’t introduce new risks but increases the probability of a vulnerability appearing in production. Recommendations can vary based on the organization’s maturity and confidence in securing code delivered to production. A robust CI/CD pipeline and strong processes with automatic security scans (SAST, DAST, FOSS…) have a good chance of detecting the most critical vulnerabilities.
ChatGPT isn’t the only online resource accessible to users that can lead to data exfiltration (Google Drive, WeTransfer…). The risk of data leakage already looms over any organization that hasn’t implemented an allow-list on its users’ internet proxy. The differentiating factor in the case of ChatGPT is that the user doesn’t necessarily realize the public nature of the data posted on the platform. The benefits and time saved by the tool are often too tempting for the user, making them forget best practices. In this sense, ChatGPT doesn’t introduce new risks but increases the likelihood of data leakage.
An organization therefore has two options to prevent data leakage via ChatGPT: (1) train and educate its users and trust them, or (2) block the tool.
For developer populations, once again, code generation via ChatGPT doesn’t introduce new risks but increases the probability of a vulnerability appearing in production. It’s up to the organization to assess the capabilities of its CI/CD pipeline and production processes to evaluate residual risks, particularly concerning false negatives from integrated security tools (SAST, DAST…).
To make an informed decision, a risk analysis remains a valuable tool for deciding whether to potentially block access to ChatGPT. The following aspects should be considered: user awareness level, sensitivity of manipulated data, internet filtering paradigm, maturity of the CI/CD pipeline… These analyses should, of course, be balanced against potential productivity gains for teams.

