
Si nous avons vu dans un article précédent la prédominance de FAIR dans le monde de la quantification[1], un autre article publié ici début juin[2] (détaillant la méthode FAIR dans sa seconde partie) insiste sur le soin à apporter dans le déroulement de la méthode, dont les résultats des calculs (éventuellement automatisables) permettent d’obtenir des valeurs précises.
Cependant, comment modéliser ces différentes données d’entrée de FAIR ? Comment se font les calculs sur les données ? Existe-t-il des outils pour faciliter leur obtention ou évaluer leur qualité, et quels efforts demandent-ils pour être mis en œuvre ?
Ayants vu précédemment dans quelle mesure la méthode de quantification du risque était digne de confiance dans son déroulement, voyons à présent comment la part inévitable de subjectivité peut être confinée, et quels facilitateurs peuvent aider à obtenir des résultats sûrs.
Le carburant de FAIR : les données
L’analyse du risque proposée par FAIR (selon le document de normalisation édité par l’OpenGroup[3]) est réalisée en quatre temps :
- Dans un premier temps, de façon assez classique, il s’agit de préciser le périmètre du risque en question (Scope the analysis) : l’asset (le bien sujet au risque), le contexte de la menace (agent et scénario), et l’évènement de perte (ou évènement redouté considéré sous l’angle des pertes) ;
- La deuxième étape (Evaluate Loss Event Frequency) consiste à collecter l’ensemble des données fréquentielles liées à l’évènement de perte (et donc intimement lié à l’agent de menace). Ceci consiste à collecter les valeurs de la branche de gauche dans l’arborescence ci-dessous.
- La troisième (Evaluate Loss Magnitude), en évaluant les couts, focalise sur l’asset. Il s’agit alors de chiffrer les différentes pertes primaires (c’est-à-dire les pertes inévitables en cas d’occurrence du risque) et secondaires (ou pertes éventuelles, ne se produisant pas systématiquement en cas d’avènement du risque). Ceci consiste à collecter les valeurs de la branche de droite dans l’arborescence ci-dessous.
- Enfin, la dernière étape (Derive and Articulate Risk) est le fusionnement des données obtenues conformément à l’arborescence FAIR par différents calculs, pour obtenir le résultat sous forme d’outputs exploitables.
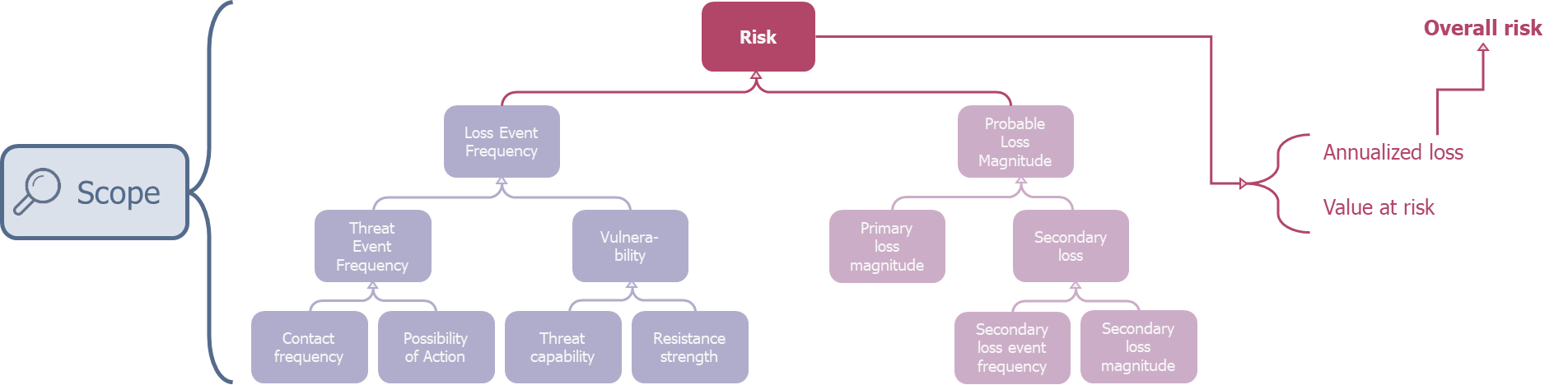
Lien entre l’analyse et la taxonomie de FAIR
Sans aller plus dans le détail de la taxonomie, déjà abordé dans l’article présenté précédemment2, nous constatons que l’analyse standard d’un seul risque demande déjà sept données (correspondant aux éléments de la base de l’arborescence) :
- Contact frequency;
- Possibility of action;
- Threat capability;
- Resistance strength;
- Primary loss magnitude;
- Secondary loss magnitude;
- Secondary loss event frequency.
Il faut ajouter à cela que FAIR invite à décliner les pertes (primaires et secondaires) en six catégories (facilitant ainsi l’estimation précise de ces données de pertes) :
- En pertes de production : liées à l’interruption du service produit par l’asset ;
- En cout de réponse : liées à la réponse à incident ;
- En frais de remplacement : liées au remplacement des constituants endommagés de l’asset ;
- En frais de justice : liées aux amendes et poursuites juridiques ;
- En perte d’avantage compétitif : liées à l’impact sur l’organisation dans son secteur d’activité ;
- En pertes de réputation : liées aux retombées sur l’image publique de l’organisation.
Comment modéliser correctement l’incertitude du risque ?
De plus, il est bon de se poser la question de ce qu’est concrètement une donnée FAIR.
En effet, il est trop réducteur de définir une donnée par une unique valeur chiffrée. Par exemple, si nous considérons l’attaque par rançongiciel : il serait incorrect d’affirmer qu’une occurrence de ce risque couterait exactement 475 k€[4] (illustrée par la courbe bleue sur le graphe 1).
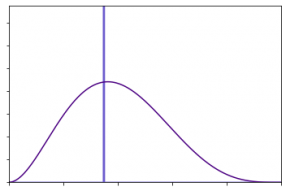
Graphe 1 : Une distribution, un modèle plus réaliste qu’une valeur isolée
En revanche, ajouter de l’incertitude à cette donnée en l’accompagnant d’une borne minimale (qui pourrait être de 1 € dans notre exemple) et d’une borne maximale (de 300 M€ dans l’exemple), tout en gardant la valeur la plus probable énoncée précédemment, permettrait de modéliser beaucoup plus fidèlement la réalité (courbe violette du graphe 1).
Une donnée est alors définie par un minimum, un maximum et une valeur la plus probable (correspondant au pic de la distribution). Nous pouvons de plus noter qu’une telle distribution de probabilité est indépendante du type de valeurs considérées : il peut aussi bien s’agir d’une perte dans une devise quelconque (cf. l’exemple précédent), que d’une occurrence (par exemple, entre 1 fois par an et 1 fois tous les 10 ans, et une valeur plus probable autour d’une fois tous les deux ans), ou bien même d’un ratio (entre 30% et 70 %, plus probablement autour de 45%). Nous pouvons ainsi utiliser ces distributions pour modéliser toutes les données de la taxonomie FAIR.
Un autre avantage de la modélisation de l’incertitude par une distribution est de pouvoir régler finement le degré de confiance dans la valeur la plus probable, via le coefficient d’aplatissement de la courbe. Plus ce dernier sera élevé, plus la confiance dans la donnée sera grande (correspondant à un pic très marqué, cf. la courbe verte sur le graphe 2). En revanche, une donnée peu fiable sera modélisée par une distribution beaucoup plus homogène (cf. la courbe rouge sur le graphe 2).
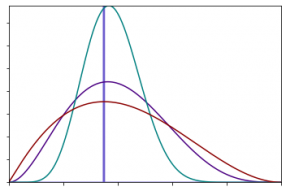
Graphe 2 : Refléter le niveau de confiance à travers les distributions
Cependant, le fait d’utiliser des distributions plutôt que des valeurs fixes pose problème lorsqu’il s’agit de les combiner entre elles, ce qui sera nécessairement le cas lorsque nous effectuerons les calculs de l’arborescence FAIR. Comme nous pouvons en effet le constater sur le graphe 3 (l’addition de la distribution verte et de la rouge donnant la violette), l’addition de deux lois de distribution ne permet pas d’obtenir une distribution aussi ‘simple’ que les précédentes (elle ne suit plus une loi de probabilité dite log-normale). Cela est également le cas dans le cadre d’une multiplication (dont le résultat est également complexe).
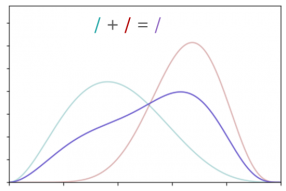
Graphe 3 : addition de deux distributions.
Pour obtenir un résultat mathématiquement cohérent, la théorie des jeux nous donne un moyen simple : les simulations de Monte Carlo. Il s’agit en effet de discrétiser les distributions (la verte et la rouge du graphe 3), en un nombre prédéfini de valeurs aléatoires (appelé nombre de simulations), réparties de façon à correspondre à la distribution concernée. Nous pouvons ensuite combiner les distributions ainsi discrétisées en effectuant les calculs sur des paires de valeurs de chaque distribution. La nouvelle répartition pourra ensuite être approximée, et sera d’autant plus précise que le nombre de simulations sera grand.
Les caisses à outils artisanales pour automatiser FAIR…
Pour effectuer ces calculs permettant d’obtenir une valeur chiffrée du risque, des solutions ont émergé (principalement à partir de la méthode FAIR). Nous aborderons donc ici les avantages et inconvénients de ces outils, qui sont également cités dans l’article précédent1.
L’OpenFAIR Analysis Tool
La première que nous pouvons citer est l’OpenFAIR Analysis Tool[5]. Si cet outil a simplement un but pédagogique, il permet néanmoins de comprendre le fonctionnement de FAIR. Il est ainsi possible d’avoir une première application concrète de la méthode, et d’obtenir des résultats simplement (uniquement dans le cadre d’une analyse d’un risque isolé). Mis sur pied par l’université de San José (Californie) en collaboration avec l’OpenGroup, cet outil utilise une feuille Excel pour obtenir une évaluation du risque à partir d’un nombre prédéterminé de simulations, en respectant scrupuleusement la taxonomie FAIR.
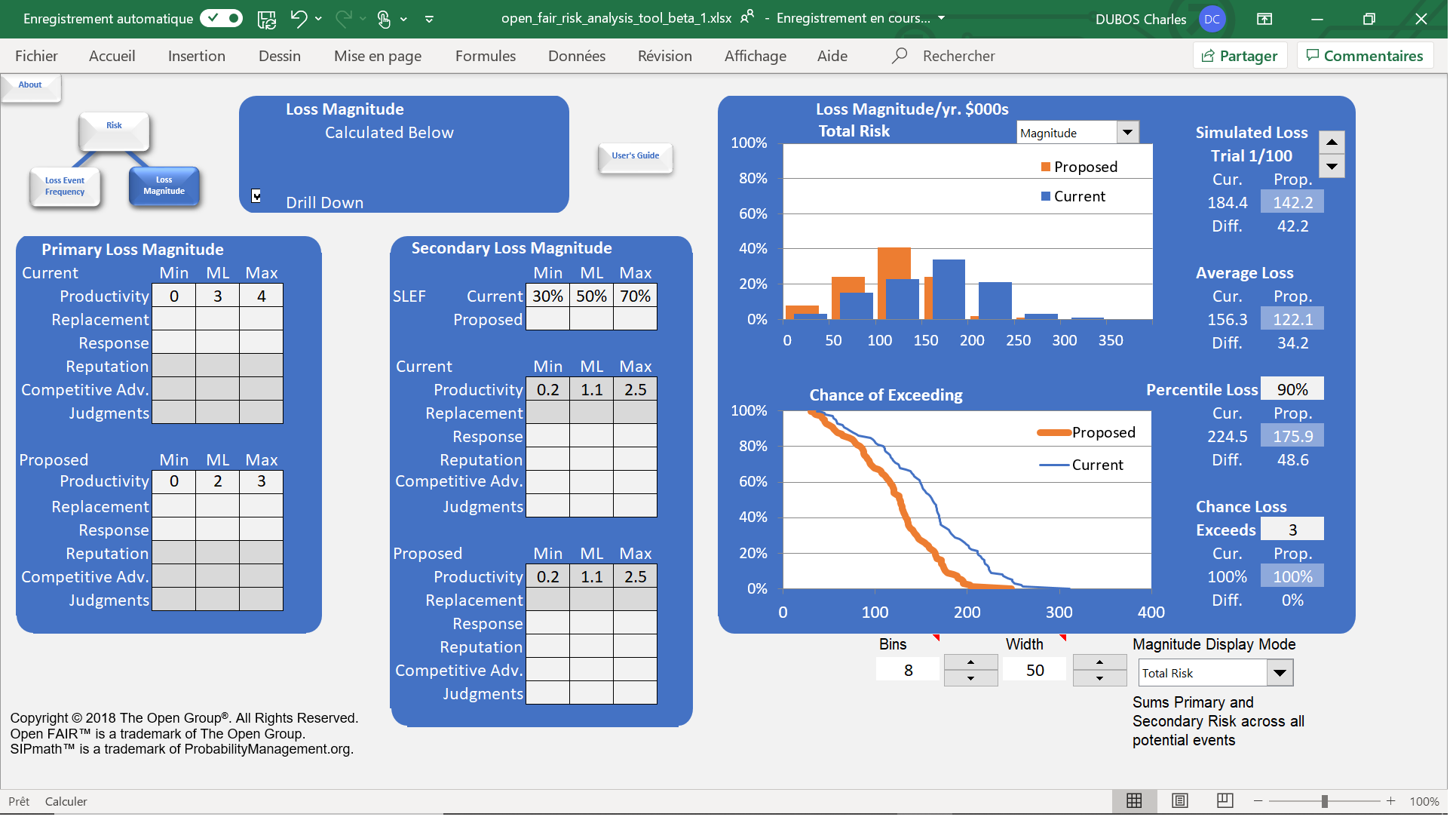
OpenFAIR Risk Analysis Tool : un outil avant tout pédagogique
Très utile pour avoir un premier contact avec la quantification, l’outil reste cependant très limité en termes d’utilisation. Enfin, il faut noter qu’il n’est accessible que sous Excel et avec une licence d’évaluation limitée à 90 jours.
Riskquant
Pour une utilisation à plus grande échelle, le département R&D de Netflix a mis sur pied la solution Riskquant[6]. Il s’agit d’une bibliothèque de programmation Python, s’appuyant notamment sur tensorflow (un module python spécialisé pour le calcul statistique massif). La particularité de Riskquant est de proposer une quantification du risque inspirée de la taxonomie FAIR, mais ayant gardé une grande liberté dans son implémentation. Développée pour faciliter l’utilisation sur des conteneurs, elle permet par conception des évaluations très rapides à partir de fichiers csv.
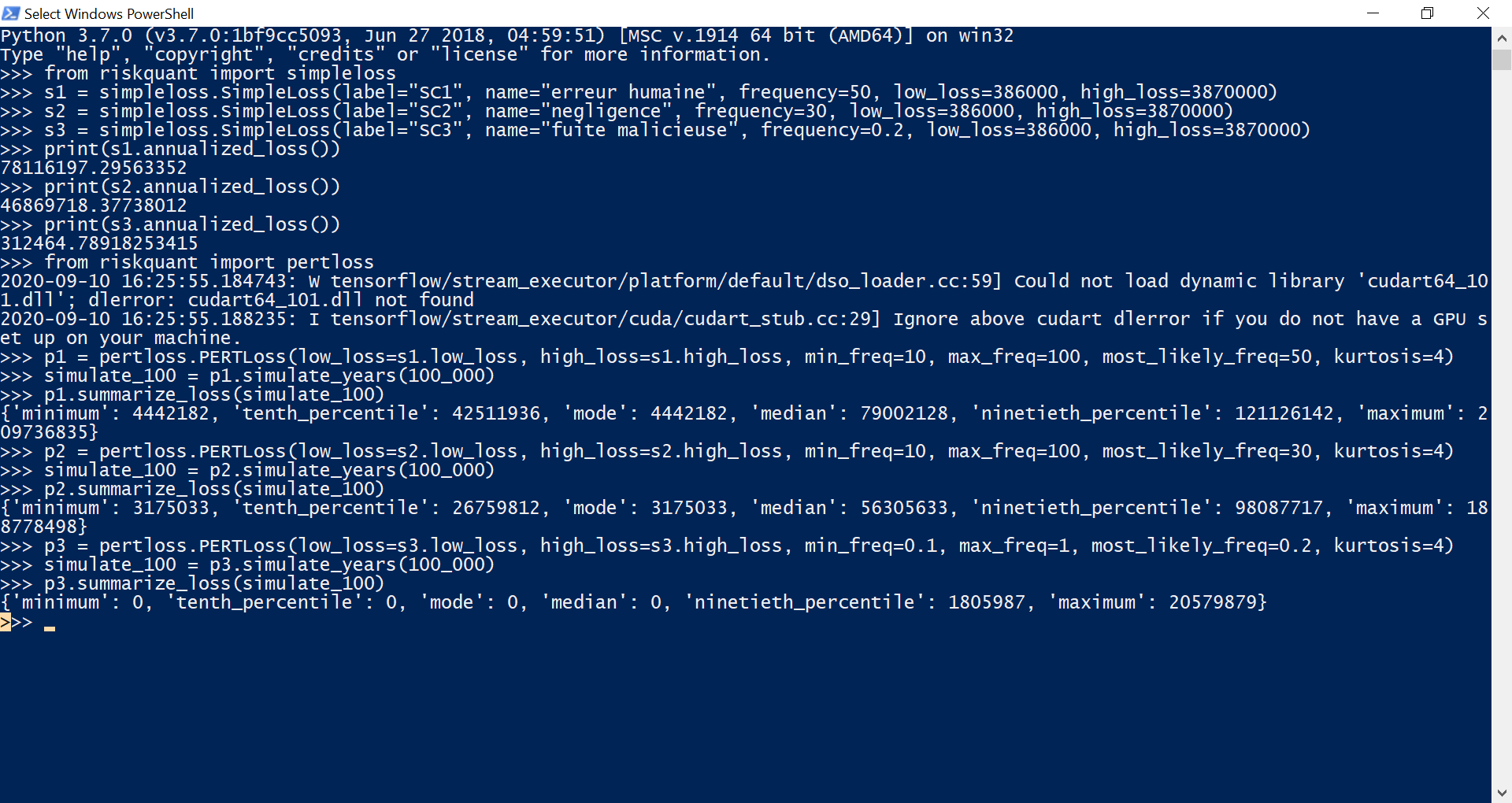
Riskquant : une approche originale mais manquant de maturité
Cependant, le fait de n’avoir gardé de FAIR qu’une valeur unique de perte et une fréquence unique la rend peu exploitable, notamment dans le cadre d’une organisation qui chercherait à cadrer précisément ses risques. De plus, elle ne fournit à ce jour que peu de résultats exploitables et manque clairement de maturité. Enfin, elle semble à ce jour mise en sommeil depuis le 1er mai 2020 (date du dernier dépôt sur la page GitHub de la solution).
PyFAIR
Pour finir ce paragraphe sur les solutions pouvant servir de base à une implémentation de FAIR, la bibliothèque PyFAIR est disponible sur le dépôt python officiel (téléchargeable via l’outil pip). Désormais mature, l’outil permet une décomposition du risque suivant la taxonomie FAIR. Il permet également d’alimenter l’arborescence à partir de valeurs intermédiaires, ou de regrouper des données pouvant servir à plusieurs risques (permettant par exemple des regroupements par asset ou menaces). Il est capable de calculer des risques globaux, et fournit des distributions facilement exploitables sous python, mais également des graphiques et des rapports HTML préformattés.
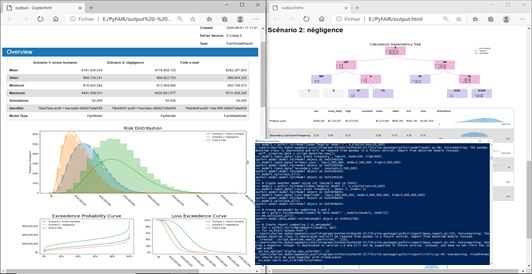
PyFAIR, une bibliothèque complète et efficace en Python
Bien qu’elle reste une boite à outil de programmation, demandant de fait une appétence et du temps pour développer et entretenir une solution en Python, PyFAIR est bien conçue. Elle facilite l’implémentation de FAIR en restant très proche de la taxonomie, et fournit des fonctions facilitant la mise en œuvre comme l’exploitation des résultats. Apte à être exploitée à plusieurs niveaux (i.e. en l’utilisant uniquement pour calculer des résultats à partir d’un paramétrage fin de FAIR et de Monte Carlo, ou bien en exploitant des fonctions de génération de rapports de haut niveau), elle permet d’envisager une utilisation de la quantification techniquement facilitée et à grande échelle.
Des plateformes ‘clé en main’ pour faciliter l’acquisition des données :
Néanmoins, la difficulté principale de FAIR reste, comme nous l’avons vu précédemment, l’obtention de données et leur fiabilité. Pour y faire face efficacement, la solution la plus efficace est de s’appuyer sur une plateforme intégrant une base de données de CTI.
Ces plateformes fournissent les valeurs de risque liées aux menaces (donc très peu dépendantes de l’entreprise). Elles accompagnent de plus le déploiement et la mise en œuvre de la méthode de quantification, notamment en la guidant pour l’obtention de données de pertes adaptées.
RiskLens
La première de ces solutions est la plateforme RiskLens[7]. Cette solution, directement issue de la méthodologie FAIR, a été co-fondée par Jack Jones. Elle sert de support technique au développement de la méthode, en lien avec le FAIR Institute. Ayant une approche technique de la méthode, elle porte son effort sur le respect des standards de l’analyse en général et de la définition du périmètre (première étape de FAIR) en particulier.
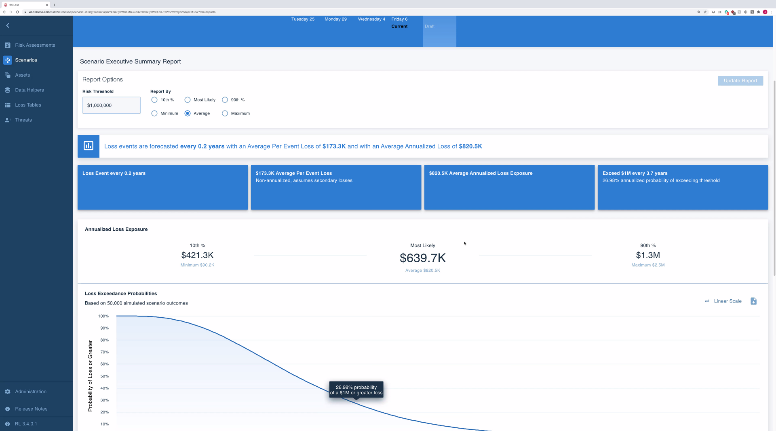
RiskLens, l’application de FAIR à la lettre
Néanmoins, il faut noter que d’une part, cette solution demande d’avoir des notions avancées dans la méthode FAIR pour être facilement utilisable. En effet, la plateforme n’apporte pas une véritable aide pour l’obtention des données (qui comme nous l’avons vu, reste la clé de voute de la quantification), partant du principe que la définition du périmètre suffit à définir précisément la donnée, et de ce fait de l’obtenir aisément. D’autre part, il s’agit d’une plateforme américaine, ce qui implique que l’interface (assez peu intuitive) est uniquement disponible dans cette langue, et que les données collectées sont alors assujetties à la réglementation américaine.
CITALID
La seconde plateforme dont nous ferons mention ici est la startup française CITALID, qui a adopté une approche fondamentalement différente. En effet, cette dernière, fondée par deux analystes de l’ANSSI, recherche par conception à lier la CTI à la gestion de risque. Ainsi, utilisant FAIR comme l’outil leur permettant de réaliser ce lien, elle fait effort sur la conception et le maintien d’une base de données disposant de chiffres solides et maintenus à jour pour suivre au plus près la situation cyber géopolitique locale et internationale.
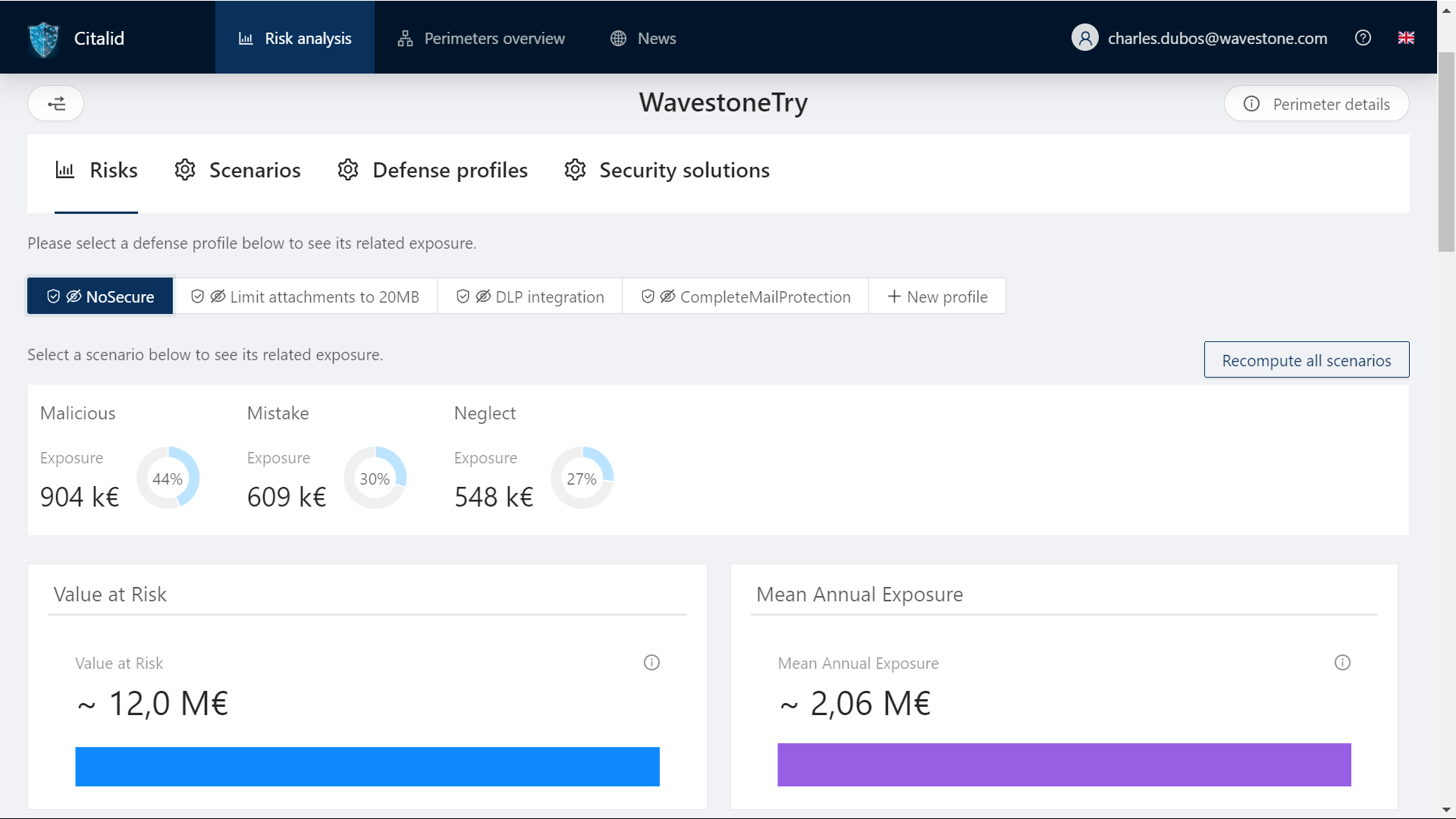
CITALID, une base de données à haute valeur ajoutée
Cette dernière plateforme apporte un vrai accompagnement dans la définition et la collecte des données, permettant ainsi d’identifier précisément où subsiste la part de subjectivité indéniablement liée au risque. Disponible en français et en anglais, elle facilite la gestion du risque cyber en prenant en compte tous les paramètres de l’organisation (localisation, taille, secteur d’activité, niveau de maturité, conformité aux référentiels, etc.) pour fournir des données de contextes adaptées. En outre, et en plus d’une explicitation de chacun des champs de la plateforme, la startup accompagne ses clients dans l’obtention des données qui sont de leur ressort.
FAIR le premier pas…
Quoi qu’il en soit, la difficulté demeurera toujours de réussir la transition de l’estimation qualitative à l’estimation quantitative. Bien que des solutions puissent faciliter cette bascule, l’abandon d’une méthode maitrisée pour une nouvelle méthode reste un défi, malgré tous les bienfaits que cette dernière promet.
S’il fallait insister sur 3 points pour envisager ce changement, ceux-ci pourraient être :
- D’une part, de s’assurer d’avoir la maturité requise. La quantification demande d’avoir une bonne maitrise du niveau de sécurité du SI concerné, et de s’adosser à une méthode de gestion du risque préexistante et rodée. Si la quantification apporte des solutions pour chiffrer un risque, le provisionner ou estimer le ROI d’une mesure, il est cependant inutile (voire contre-productif) de s’engager sur cette voie trop tôt (sous peine au mieux de perdre du temps, au pire de dégrader la gestion de risque existante).
- Ensuite, d’avoir une approche progressive dans le déploiement de la quantification. Dans un SI mature disposant d’une gestion de risque stable, il est préférable d’adopter progressivement la méthode quantitative. Cela permet notamment de prendre confiance dans les estimations produites (éventuellement en le faisant coexister avec la méthode d’estimation qualitative) et d’assimiler la méthodologie, tout en assurant son intégration dans le processus existant de gestion du risque.
- Pour terminer, de s’appuyer sur l’expérience existante dans la collecte des données de risque cyber. La difficulté résidant dans l’obtention de données sûres, il est crucial (pour avoir confiance dans la méthode) de disposer de chiffres sûrs. Il semble alors judicieux de s’appuyer sur une plateforme qui peut fournir des données de qualité, et un appui dans la collecte des données internes. Celle-ci disposera de plus de l’expérience acquise par le déploiement de la méthode sur d’autres clients. La qualité des résultats fournis sera alors l’élément clé dans la confiance que l’organisation aura dans la méthode quantitative.
[1] https://www.riskinsight-wavestone.com/2020/11/estimation-quantifiee-du-risque-1-2-lodyssee-de-la-quantification/
[2] https://www.riskinsight-wavestone.com/2020/06/la-quantification-du-risque-cybersecurite/
[3] https://publications.opengroup.org/c13g
[4] https://www.sophos.com/fr-fr/medialibrary/Gated-Assets/white-papers/sophos-the-state-of-ransomware-2020-wp.pdf
[5] https://blog.opengroup.org/2018/03/29/introducing-the-open-group-open-fair-risk-analysis-tool/
[6] https://netflixtechblog.com/open-sourcing-riskquant-a-library-for-quantifying-risk-6720cc1e4968

