
Suite à l’adoption du RGPD en 2016, la plupart des entreprises se sont dotées d’une démarche structurée en vue de l’échéance de mai 2018. Mais nous observons certaines interprétations du texte qui peuvent s’avérer inexactes. Nous avons donc lancé une série de 3 articles visant à déconstruire ces idées reçues. Après un premier article sur l’obligation de consentement, voici un second article sur l’anonymisation.
Idée reçue #2 – le RGPD impose d’anonymiser les données
On confond souvent l’anonymisation, la pseudonymisation, le chiffrement… Outre le fait que ces techniques sont bien distinctes et interviennent dans des cas de figure très différents, aucune d’elles n’est obligatoire d’après le RGPD. Certaines sont toutefois fortement recommandées.
L’anonymisation permet de soustraire les données au périmètre du RGPD
Des données à caractère personnel sont des données concernant une personne physique identifiable.
Des données sont considérées comme anonymes lorsque la personne concernée n’est plus identifiable, de manière irréversible et par quelque moyen que ce soit, c’est-à-dire qu’aucune donnée ou ensemble de données ne permet de remonter à son identité. Ce ne sont alors plus des données à caractère personnel.
Une pseudonymisation ou un chiffrement ne sont pas une anonymisation : voir ci-dessous.
L’anonymisation n’est pas imposée par le RGPD
Dans tout le RGPD, l’anonymisation n’est citée que dans un considérant. Il y est écrit que toute donnée anonyme, c’est-à-dire dont la personne n’est plus identifiable, n’est pas soumise au règlement.[i]
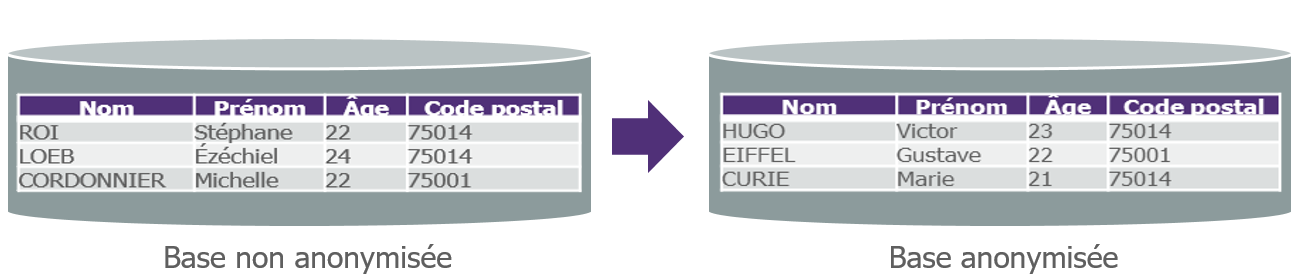
Figure 1 / Exemple d’anonymisation sur 4 colonnes, où sont appliquées les techniques : dictionnaire sur nom et prénom, floutage (variation aléatoire conservant la moyenne) sur l’âge, permutation sur les codes postaux. Ainsi les données sont utilisables pour des tests applicatifs (signifiance métier conservée) et pour certaines analyses statistiques (distribution conservée).
Anonymiser des données, au sens du RGPD, a la même efficacité que les effacer.
Toutefois, si l’effacement peut concerner un seul attribut (par exemple si la personne exerce son droit à l’oubli sur son adresse e-mail), l’anonymisation quant à elle doit concerner tout l’enregistrement, c’est-à-dire la totalité des données permettant d’identifier une personne. En effet, cela n’a pas de sens d’anonymiser certains attributs (par exemple nom et prénom) d’un enregistrement et laisser les autres en clair (adresse e-mail, adresse postale…).
Attention : l’anonymisation n’est jamais garantie ou absolue ! Il faut notamment tenir compte du risque de réidentification résiduel, car avec une analyse plus ou moins poussée, un attaquant pourra peut-être retrouver avec une certaine probabilité l’identité d’une personne. Ce risque existera toujours et il faut le mesurer.[ii]
L’anonymisation est pertinente pour des cas d’usage précis
L’anonymisation étant par définition irréversible, elle ne peut en général pas s’appliquer à des données en production utilisées par des processus métier, car celles-ci seraient alors inutilisables. Ainsi, ce qui peut justifier une anonymisation plutôt qu’un effacement est l’utilisation de ces données pour :
- des analyses statistiques (par exemple à des fins marketing) ;
- des tests dans le cycle de développement logiciel (environnements hors production : tests unitaires, intégration, qualification, recette).
Il existe un autre cas d’utilisation, qui correspond au cas où un système ne prévoit pas la suppression physique des données. Alors, pour les effacer, il conviendra de procéder à une suppression logique et à une destruction des données, c’est-à-dire l’application d’une technique d’anonymisation basique qui consiste à remplacer les données par des valeurs sans signification (par exemple les valeurs alphanumériques par des « X » et les nombres par des 0 ou des 9). Cette technique rend bien sûr impossibles les analyses statistiques ou les tests fonctionnels.
Les techniques d’anonymisation sont très variées et dépendent du type de données et de l’utilisation à laquelle elles sont destinées. De nombreux outils existent sur un marché en cours de maturation.
La pseudonymisation : un moyen de protection efficace
En bref, la pseudonymisation consiste à scinder de manière réversible les données identifiantes des autres, en utilisant comme pivot des pseudonymes non explicites (par exemple des chaînes de caractères aléatoires) pour faire la correspondance. Cela permet de limiter l’exposition à des données non identifiantes ou quasi-identifiantes.
Mais pseudonymiser n’est pas anonymiser ! En effet :
- c’est réversible : avec la table de correspondances on peut retrouver la personne ;
- des données restées en clair peuvent être quasi-identifiantes, c’est-à-dire permettre l’identification par une analyse plus ou moins complexe.
Une technique mature pour certains secteurs spécifiques, encouragée par le RGPD
La pseudonymisation n’est pas obligatoire, mais est considérée comme une technique valable permettant de sécuriser les données, et ça, c’est obligatoire ![iii],[iv]
La pseudonymisation, ainsi que ses variantes comme la tokenisation et le hachage, sont généralement implémentées en production afin de masquer les données à caractère personnel (DCP) en fonction des rôles de l’utilisateur, dans le but simplement de limiter l’exposition des DCP et ainsi les risques de fuite et d’attaque. Contrairement à l’anonymisation, c’est un marché plus mature (des solutions se sont notamment développées dans le cadre de PCI-DSS), mais ce ne sont pas forcément les mêmes solutions qui excellent dans les deux domaines de l’anonymisation et de la pseudonymisation.
Le chiffrement : un moyen de protection indispensable, mais avec ses limites
Le chiffrement est une transformation réversible des données, les rendant illisibles par application d’une fonction de chiffrement. Cette fonction peut être inversée uniquement grâce à la clé de chiffrement, détenue par l’entreprise ou par la personne concernée. Cela permet de réduire fortement l’impact d’une fuite de données.
Là encore, chiffrer n’est pas anonymiser ! C’est réversible : les détenteurs de la clé peuvent accéder aux données.
Le chiffrement encouragé par le RGPD
Le chiffrement peut permettre de ne pas avoir à communiquer une fuite de données lorsque les données ayant fuité sont chiffrées.[v]
Le chiffrement n’est pas obligatoire, mais est considéré comme une technique valable permettant de sécuriser les données, et ça, c’est obligatoire ![vi]
Une pratique mature et répandue mais qui ne s’applique pas à tous les environnements
Le chiffrement est largement répandu depuis des années et est proposé en standard dans la plupart des technologies de stockage et de transfert de données. Idéalement, l’on souhaiterait étendre cette pratique à tous les environnements, production, hors production, espaces de stockage individuels ou partagés… Toutefois, ses impacts ne sont pas anodins : en production, le chiffrement a un impact sur les flux temps réel, car les opérations de chiffrement-déchiffrement prennent du temps et réduisent la performance ; hors production, les accès aux bases de données sont par nature accordés à de nombreux acteurs (développeurs, testeurs, MOA…) qui les explorent directement et manuellement, ce qui rend la généralisation du chiffrement difficile.
Aucune de ces techniques, anonymisation, pseudonymisation et chiffrement, n’est imposée par le RGPD. Toutefois, elles sont toutes suggérées ou recommandées, mais dans des cas précis et pour répondre à des besoins bien distincts. L’anonymisation, irréversible, permet de soustraire des données au périmètre du RGPD, généralement pour des usages de test applicatif ou d’analyse statistique : elle doit pour cela conserver le sens métier et la distribution des données. La pseudonymisation sert, en production, à limiter à la volée l’exposition des données au strict nécessaire en fonction de l’utilisateur qui y accède, en remplaçant de manière réversible certaines valeurs par d’autres sans signification. Enfin, le chiffrement, plus répandu, chiffre de manière réversible les valeurs en base, rendant toute fuite de données moins impactante, les données étant déchiffrées uniquement en lecture par les détenteurs de la clé.
Protéger les données en notre possession est une chose indispensable, mais cela nous autorise-t-il à les conserver indéfiniment ? L’on entend souvent que le RGPD spécifie un temps de conservation maximum des données. Cette idée reçue sera abordée dans le 3ème et dernier article de cette série.
[i] Considérant 26
[ii] Exemple d’une attaque à des fins journalistiques : Oberhaus, D. (11/08/2017). « Votre historique de navigation privée n’est pas vraiment privé ». Disponible à l’adresse : https://motherboard.vice.com/fr/article/wjj8e5/votre-historique-de-navigation-privee-nest-pas-vraiment-prive, consultée le 08/01/2018.
[iii] Considérant 28
[iv] Article 32, paragraphe 1
[v] Article 34, paragraphe 3
[vi] Article 32, paragraphe 1

