
En 2023, l’Intelligence Artificielle a eu un retentissement médiatique sans comparaison dans son histoire. La cause ? ChatGPT, une intelligence artificielle générative capable de répondre à des questions avec une précision stupéfiante. Les perspectives générées sont multiples et dépassent actuellement l’entendement. A tel point que des acteurs du monde scientifique et industriel se mobilisent pour défendre l’idée qu’il est nécessaire de prendre six mois de pause en matière de recherche sur l’IA pour réfléchir aux transformations à venir au sein de la société.
Dans sa volonté d’accompagner la transformation digitale de ses clients en limitant les risques induits, la pratice Cybersécurité de Wavestone vous propose d’étudier ensemble comment il est possible de réaliser des attaques cyber sur un système d’IA et comment il est possible de s’en prémunir.
Attaquer un système d’IA interne ? (Notre RSSI nous déteste)
Démarche et objectifs
Comme le démontrent les récents travaux sur les systèmes d’IA[1] de l’ENISA[2], ou encore du NIST[3], l’IA est vulnérable à un certain nombre de menaces cyber. Ces menaces peuvent être génériques ou spécifiques et adressent globalement l’ensemble des systèmes d’IA basés sur le Machine Learning (ML).

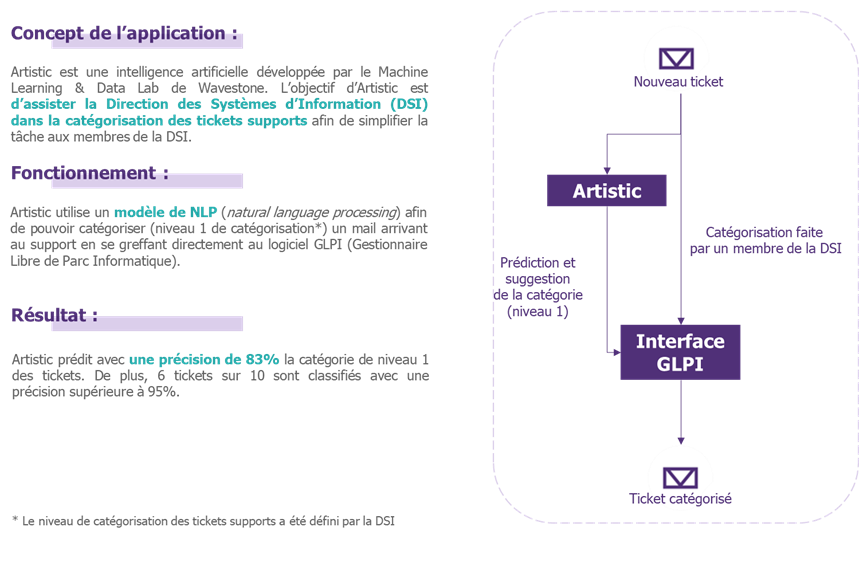
Pour vérifier la faisabilité de telles menaces, nous avons eu le souhait d’expérimenter les menaces spécifiques de l’Evasion et de l’Oracle sur une de nos applications internes à faible impact : Artistic, un outil de classification des tickets[4] des collaborateurs à destination du support Informatique.
Pour cela, nous nous sommes mis dans la peau d’un utilisateur malveillant qui, ayant connaissance que le traitement des tickets repose sur un algorithme d’Intelligence Artificielle, chercherait à mener des attaques de type Evasion ou Oracle.
Evidemment, les impacts de telles attaques sont très faibles mais notre IA est un super terrain de jeu pour faire des expérimentations.
Présentation de l’application
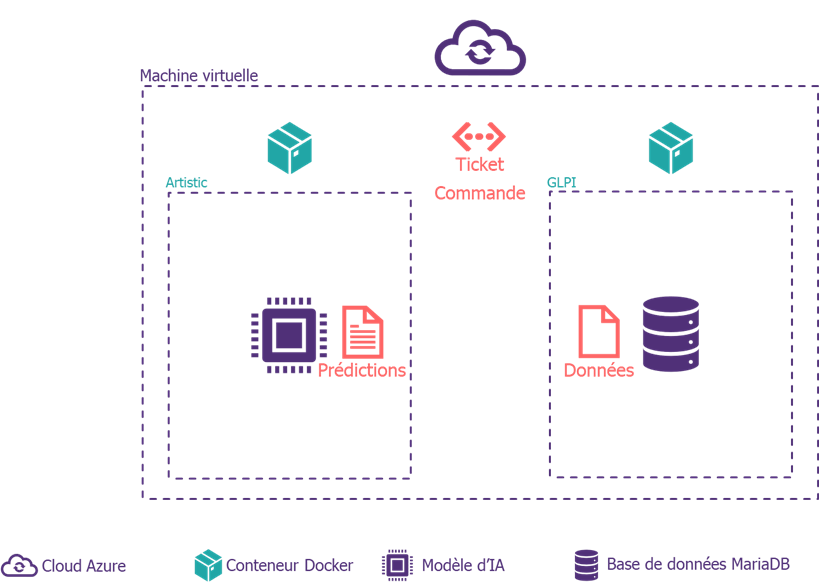
Architecture de l’application
Attaque par évasion
Présentation de la démarche
Une attaque de type évasion consiste à détourner le fonctionnement de l’intelligence artificielle en lui fournissant des exemples contradictoires (également connus sous le nom de « adversarial example ») afin d’induire des prédictions erronées. Un exemple contradictoire est une instance d’un objet comportant des perturbations intentionnelles sur ses caractéristiques qui amènent un modèle d’apprentissage automatique à faire une fausse prédiction. Ces perturbations peuvent passer facilement inaperçues pour un humain, telle qu’une faute de frappe sur un mot par exemple, et modifier radicalement les données de sortie du modèle.
Dans le cadre de notre exemple, nous allons chercher à construire différents exemples contradictoires en utilisant trois techniques :
- La suppression et le changement de caractères
- Remplacements de mots en utilisant une technique dédiée (Embedding)
- Le changement de la position des mots
Concrètement, ces exemples contradictoires dans notre cas d’usage sont des demandes écrites quelques peu modifiées (cf. l’exemple 1 ci-dessous) qui vont être formulées dans l’outil de ticketing Artistic.
Pour ce faire, nous allons utiliser un outil dédié : TextAttack. TextAttack est un Framework Python permettant de réaliser des attaques par évasion (intéressant pour notre cas), d’entrainer un modèle de NLP avec des exemples contradictoires et faire de l’augmentation de données dans le domaine du NLP.
Résultats
Considérons une phrase classée correctement par notre Intelligence Artificielle avec une forte probabilité. Appliquons à présent le Framework TextAttack et utilisons le pour générer des exemples contradictoires basés sur notre phrase correctement classée.

Nous observons ainsi que des phrases, qui restent (plus ou moins) compréhensibles à un opérateur, perturbent le fonctionnement de l’Intelligence Artificielle au point de mal les classifier. De plus, nous pouvons observer qu’avec une multitude d’exemples contradictoires créés, il est possible de remonter à toutes les catégories de classification et ce avec des taux de précision plus ou moins élevés.
Par extension, sur des Intelligences Artificielles plus critiques, on relève de ces mauvaises prédictions plusieurs problèmes :
- Des atteintes à la sécurité : le modèle en question est compromis et il devient possible aux attaquants d’obtenir des prédications erronées ;
- Une confiance moindre aux systèmes d’IA : une telle attaque diminue la confiance en l’IA et le choix d’adoption de tels modèles, remettant en cause le potentiel d’une telle technologie.
Toutefois, d’après l’ENISA, quelques mesures peuvent être implémentées pour nous prémunir de ce genre d’attaques :
- Définir un modèle plus robuste aux attaques par évasion. Le système d’IA d’Artistic est particulièrement peu robuste à ces attaques et a un fonctionnement très basique (comme nous le verrons par la suite). Un modèle autre modèle aurait certainement été plus résistant aux attaques par évasion.
- Faire de l’adversarial training lors de la phase d’apprentissage du modèle. Cela consiste à ajouter des exemples d’attaques dans les données d’entraînement afin que le modèle améliore sa capacité à classifier correctement des données « étranges ».
- Mettre en place des contrôles sur les données en entrée du modèle pour assurer de la « qualité » des mots saisis par exemple.
Attaque de type Oracle
Définition
Les attaques de type Oracle consistent à étudier des modèles d’IA et tenter d’obtenir des informations sur le modèle en interagissant avec ces derniers par le biais de requête. Contrairement aux attaques par évasion, qui visent à manipuler les données d’entrée d’un modèle d’IA, les attaques par Oracle tentent d’extraire des informations sensibles sur le modèle lui-même et sur les données qu’il a manipulées (ayant servi à l’apprentissage par exemple).
Dans notre cas d’usage, nous cherchons simplement à comprendre le fonctionnement du modèle. Pour ce faire, nous avons cherché à comprendre le comportement du modèle en analysant les couples entrées-sorties fournis grâce à nos exemples contradictoires.
Résultats

En passant par plusieurs essais, l’attaquant peut être capable de déceler la sensibilité du modèle aux changements sur les données d’entrée. Grace à l’exemple ci-dessus, nous observons que l’algorithme utilisé par l’application prédit la classe d’un message en attribuant un score à chaque mot puis détermine la catégorie. En analysant ces résultats divers, l’attaquant peut être en mesure de déduire les vulnérabilités du modèle aux attaques par évasion.
Par extension, sur des Intelligences Artificielles plus critiques, les attaques de type Oracle posent plusieurs problèmes :
- Atteinte à la propriété intellectuelle : comme mentionné, l’attaque de type Oracle peut permettre le vol de l’architecture du modèle, les hyperparamètres, etc. De telles informations peuvent servir pour créer une réplique du modèle.
- Atteintes à la confidentialité des données d’entraînement : cette attaque peut permettre de révéler des informations sensibles sur les données d’entrainement utilisées pour former le modèle, et qui peuvent être confidentielles.
Quelques mesures auraient pu être implémentées pour nous prémunir de ce genre d’attaques :
- Définir un modèle plus robuste aux attaques de type Oracle. Le système d’IA d’Artistic est très basique et est très facile à comprendre.
- [Pour les IA de manière plus large] S’assurer que le modèle respecte la confidentialité différentielle. La confidentialité différentielle est une définition extrêmement forte de la confidentialité qui garantit une limite à ce qu’un attaquant ayant accès aux résultats de l’algorithme peut apprendre sur chaque enregistrement individuel de l’ensemble de données.
S’emparer du sujet aujourd’hui dans votre organisation
Nous observons que même sans connaître précisément les paramètres d’un modèle d’Intelligence Artificielle, il est relativement aisé de mener des attaques de type Evasion ou Oracle.
Dans notre cas d’usage, les impacts sont limités. Toutefois, les conséquences d’une attaque par évasion sur un véhicule autonome ou encore d’une attaque de type Oracle sur un modèle utilisé avec des données de santé sont largement plus graves pour les individus : dégâts physiques dans un cas et atteinte à la vie privée dans l’autre.
Plusieurs de nos clients commencent d’ores et déjà à déployer des premières mesures pour faire face aux risques cyber induits par l’utilisation de système d’IA. Ils font notamment évoluer leur méthodologie d’analyse de risques afin de prendre en compte les menaces montrées ci-dessus et surtout ils mettent en place des contres mesures, lorsque celles-ci sont pertinentes au regard des risques, venant des guides de sécurisation tels que ceux proposés par l’ENISA ou le NIST.
[1] Un système d’intelligence artificielle, dans la proposition législative de l’AI Act, est défini de la façon suivante : « un logiciel développé à l’aide d’une ou plusieurs des techniques et approches énumérées à l’annexe I de la proposition et capable, pour un ensemble donné d’objectifs définis par l’homme, de générer des résultats tels que des contenus, des prédictions, des recommandations ou des décisions influençant les environnements avec lesquels ils interagissent. » Dans notre article, nous considérons que les systèmes d’IA ont été entraînés via le Machine Learning, comme cela est généralement le cas sur les cas d’usage modernes tels que ChatGPT.
[2] https://www.enisa.europa.eu/publications/securing-machine-learning-algorithms
[3] https://csrc.nist.gov/publications/detail/white-paper/2023/03/08/adversarial-machine-learning-taxonomy-and-terminology/draft
[4] Un ticket représente une suite de mots (autrement dit, une phrase) dans laquelle le collaborateur exprime son besoin.

