
Depuis son apparition initiale en 2014, et suite à son officialisation en 2021 sous l’égide de l’administration du président Biden, le concept de SBOM (Software Bill of Materials) ne cesse de captiver l’attention au sein de la communauté cyber.
RSSI, DSI et équipes DevSecOps s’interrogent tous sur la manière de le mettre en pratique et de l’exploiter.
Qu’est-ce que le SBOM et dans quel contexte intervient-il ?
Le SBOM (Software Bill of Materials) est un inventaire formel, généralement au format Xlsx, JSON, XML ou texte brut, qui est conçu pour être lu par des machines. Il contient des informations détaillées sur les composants logiciels d’un système, y compris leurs dépendances, leurs attributs et leurs relations hiérarchiques. L’objectif principal d’un SBOM est de fournir une vue complète et à jour de tous les éléments logiciels qui composent une application ou un système. (source : NTIA-Software-Bill-Of-Materials)
À l’instar d’un produit physique, un logiciel est un ensemble complexe composé de divers éléments. Il comprend du code développé en interne, des composants tiers (qu’il s’agisse de bibliothèques open source ou de modules soumis à différentes licences) ainsi que l’ensemble des outils nécessaires à l’assemblage du produit final.
Or, à chaque nouvelle vulnérabilité découverte par des chercheurs ou exploitée par des hackers, les fournisseurs et acheteurs, se retrouvent confrontés à une question cruciale : où se situent les éventuelles vulnérabilités critiques au sein de leur produit ?
Aujourd’hui, l’analyse de Wavestone atteste de manière formelle que le SBOM est indéniablement un élément essentiel pour résoudre cette problématique.
Méthodes de génération du SBOM
Une analyse technique approfondie des outils disponibles sur le marché a révélé les méthodes de génération des SBOMs (Software Bill of Materials).
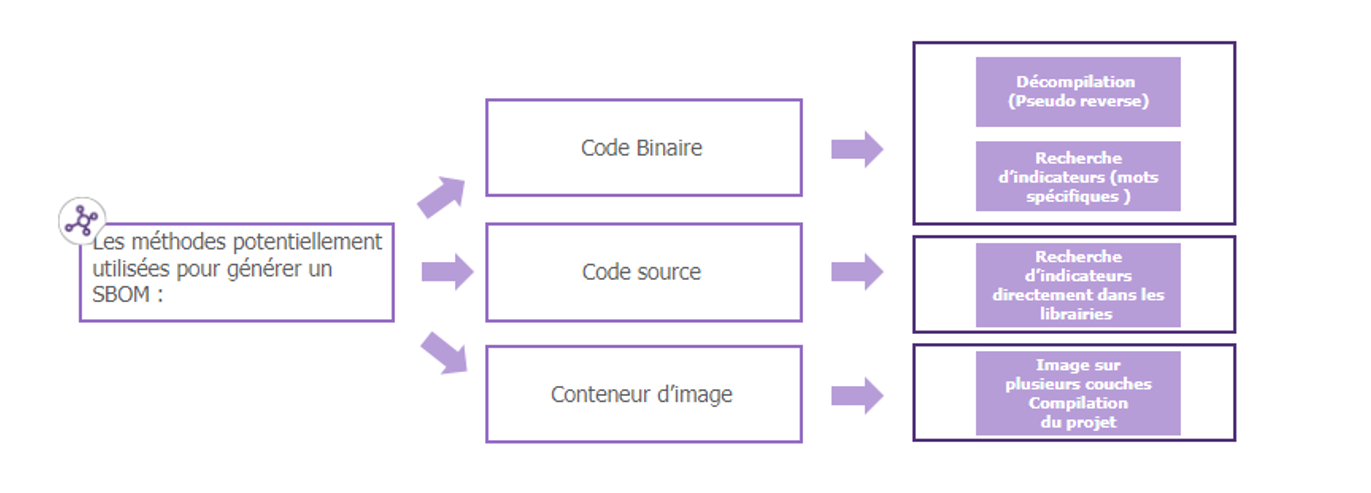
Trois sources principales émergent pour créer un SBOM à partir d’un logiciel :
- Code Binaire (compilé)
- Code source du projet
- Conteneur d’image, généré par des plates-formes telles que Docker.
Ces trois sources ont la capacité de produire un fichier conforme aux standards établis, notamment SPDX et CycloneDX. Cependant, il est essentiel de noter que tous les outils ne prennent pas en charge ces trois entrées de manière uniforme.
Le défi technique réside, par exemple, dans la décompilation du code binaire, qui peut parfois entraver son intégration. Dans de tels cas, la recherche d’indicateurs spécifiques préalablement définis au sein du code s’avère être une méthode efficace pour identifier la majeure partie des interdépendances hiérarchiques dans un format approprié.
Types d’entrées pour la génération d’un SBOM
Malgré ces techniques d’extraction et d’analyse de code, l’exhaustivité des données n’est pas pour autant garantie et une vérification additionnelle doit être considérée.
Une génération facilitée mais une exploitation qui reste à déterminer et pose encore de nombreuses questions
La création d’un SBOM, s’est considérablement simplifiée grâce à la présence d’acteurs majeurs spécialisés sur le marché, tels que Dependency Track, Adolus ou encore Fossa, pour n’en nommer que quelques-uns. De plus, les outils d’Analyse de Composition Logicielle SCA, bien établis au sein des équipes de développement de nos clients offrent désormais la possibilité de générer et de lire un SBOM.
Sa génération n’est aujourd’hui plus un défi majeur, en raison de la mise en œuvre des standards énumérés plus haut. Ils facilitent la génération automatisée du SBOM en fournissant des directives claires sur la manière dont les informations sur les composants doivent être structurées et présentées.
Cependant, les systèmes conçus pour l’analyser ne sont pas encore pleinement matures. Par exemple. Les entreprises qui reçoivent ces inventaires se trouvent souvent confrontés à des questions sur la manière de les utiliser et de les partager avec d’autres parties. Par ailleurs, à cette problématique technique s’additionne des problématiques organisationnelles car le cadre d’utilisation entre organisations n’est pas encore clairement défini.
Néanmoins, des acteurs travaillent activement à mettre en place une architecture d’intégration sécurisée de ces SBOM au sein de leurs pipelines CI/CD. Actuellement, la récupération fiable du SBOM d’un tiers reste un défi. Les préoccupations sur l’échange et le partage émergent dès que l’on aborde ce sujet. La diversité des contrats avec les fournisseurs, qui souhaitent protéger leur propriété intellectuelle, et la difficulté de centralisation posent des défis au contenu de ce type d’inventaire. Chaque inventaire est élaboré de manière hétérogène, sans suivi ni cadre réglementaire uniforme imposé. D’un point de vue technique, chaque entité a la liberté de remonter les informations de son choix.
A date, nous constatons que les pionniers dans le domaine, optent pour la génération interne de leurs SBOM, y compris sur les logiciels tiers. Cette approche offre davantage de contrôle sur la qualité et la spécificité des données, soulignant la nécessité d’une réglementation plus détaillée et de normes plus strictes pour assurer la fiabilité des échanges d’inventaires logiciels.
Le SBOM intégré au cœur de vos processus logiciels
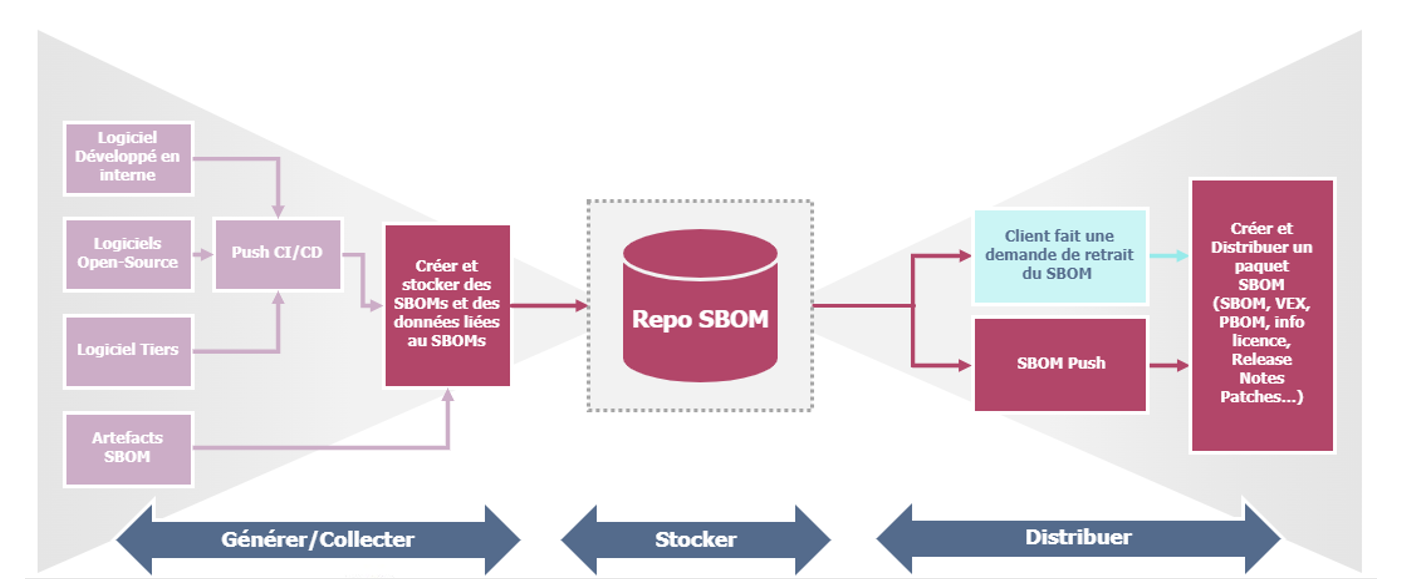
Toutes ces lacunes ont incité à concevoir un processus optimal à l’état théorique pour le moment, afin d’intégrer un SBOM au sein d’un pipeline CI/CD, processus pouvant être décomposé en quelques étapes.
- Création d’un espace de génération et de collecte du SBOM, en Automatisant la collecte de ces données pour garantir leur précision et leur exhaustivité ;
- Stockage des SBOM dans un Répertoire, en Configurant un référentiel centralisé pour stocker tous les SBOM générés. Il peut s’agir d’un référentiel de gestion de versions ou d’un système de stockage de données adapté ;
- Distribution d’un Paquet SBOM sur Demande d’un Client, en s’assurant que les SBOM sont facilement accessibles et que les clients peuvent les récupérer de manière sécurisée.
Projection sur l’intégration d’un SBOM au sein d’une chaîne d’approvisionnement logiciel
Cette prospective théorique ouvre la voie à une automatisation du processus de génération, stockage et diffusion des inventaires et rapports de vulnérabilité.
Cela offrira aux parties prenantes la capacité de :
- Recevoir en temps réel des SBOM et des rapports de vulnérabilité ;
- Authentifier la légitimité des artefacts reçus (conteneurs d’images, documents, etc..) ;
- Etablir une confiance et une validation par le bais de la transparence au cœur du processus de production logicielle.
Un futur radieux pour le SBOM ?
Les instances politiques prennent conscience du niveau d’impréparation de leurs infrastructures face à la montée en puissance des cyberattaques. Dans ce contexte, le SBOM est de plus en plus considéré comme un moyen efficace d’accroître la réactivité en matière de vulnérabilités susceptibles d’affecter un grand nombre d’entreprises de manière concomitante.
Même si le marché n’est pas encore tout à fait prêt pour une transition vers une utilisation généralisée de cette solution, il est courant que la réglementation, même si elle peut sembler arbitraire, influence profondément la trajectoire dans une nouvelle direction.
Il est probable que l’Europe finira par converger vers la réglementation établie aux États-Unis, même si celle-ci semble encore être à un stade préliminaire et incomplet, en particulier en ce qui concerne les mécanismes de partage et d’échange de ces inventaires.
Dans le contexte actuel, les acteurs concernés se voient contraints de réévaluer leurs critères de priorité. Il sera important de disposer des données sur la composition des logiciels, l’origine de ses composants, leur provenance, les vulnérabilités connues, et d’avoir confiance dans le processus de production et de contrôle de qualité.
Cependant, il est nécessaire de remettre à l’ordre du jour la série de défis auxquels ils se confrontent plus généralement :
- Données lacunaires ou incomplètes, l’absence de données exhaustives sur la composition des logiciels peut rendre difficile l’évaluation des risques.
- Approches ad hoc pour le partage de données, les méthodes non standardisées et les approches improvisées pour le partage d’informations peuvent rendre la communication inefficace et peu fiable.
- Coûts additionnels pour la collecte et la maintenance des données, la collecte, la vérification et la mise à jour des informations sur la composition des logiciels peuvent engendrer des surcoûts ;
- Absence de standardisation, le manque de normes dans la collecte et le partage des données rend difficile la comparaison et l’analyse des informations entre les différentes parties prenantes ;
- Gouvernance et confidentialité des données, La gestion des données sensibles sur la composition des logiciels soulève des préoccupations quant à leur confidentialité, intégrité et disponibilité

