
L’utilisation des systèmes d’intelligence artificielle et des Large Langage Models (LLM) a explosé depuis 2023. Les entreprises, les cybercriminels, comme les particuliers commencent à les utiliser régulièrement. Cependant, comme toute nouvelle technologie, les IA ne sont pas sans risques. Pour illustrer ces derniers, nous avons simulé deux attaques réalistes dans de précédents articles : Attaquer une IA ? Un exemple concret ! ou Quand les mots deviennent des armes : prompt injection.
Cet article vient dresser un panorama sur la menace liée à l’IA et les principaux mécanismes de défense afin de démocratiser leur utilisation.
L’IA introduit de nouvelles techniques d’attaques, déjà largement exploitées par les Cybercriminels
Comme toute nouvelle technologie, l’IA introduit de nouvelles vulnérabilités et de nouveaux risques qu’il convient d’adresser en parallèle de son adoption. La surface d’attaque est grande : un acteur malveillant pourrait à la fois attaquer le modèle en lui-même (vol de modèle, reconstruction de modèle, détournement de l’usage initial) mais également ses données (extraire des données d’entraînement, modifier le comportement en ajoutant des fausses données, etc.).
Le Prompt injection est sans conteste la technique dont on parle le plus. Elle permet à un attaquant de réaliser des actions indésirables au modèle, comme extraire des données sensibles, exécuter du code arbitraire ou générer du contenu offensant.
Etant donné la variété grandissante des attaques sur les modèles d’IA, nous survolerons de manière non exhaustive les principales catégories :
Vol de données (impact sur la confidentialité)
Dès lors que des données servent à entraîner les modèles de Machine Learning, ces dernières peuvent être (partiellement) réutilisées pour répondre aux utilisateurs. Un modèle mal configuré peut alors être un peu trop verbeux, révélant involontairement des informations sensibles. Cette situation présente un risque de violation de la vie privée et d’atteinte à la propriété intellectuelle.
Et le risque est d’autant plus grand que les modèles sont « sur-entraînés » sur des données spécifiques (« overfitting »). Les attaques par oracle se déroulent quand le modèle est en production, lorsque l’attaquant questionne le modèle pour exploiter ses réponses. Ces attaques peuvent prendre plusieurs formes :
- Extraction/vol de modèle : un attaquant peut extraire une copie fonctionnelle d’un modèle privé en s’en servant comme d’un oracle. En interrogeant à plusieurs reprises l’accès API du modèle Machine Learning, l’adversaire peut collecter les réponses de celui-ci. Ces réponses serviront d’étiquettes pour former un modèle distinct qui imitera le comportement et les performances du modèle cible.
- Membership inference attacks (attaque par inférence d’appartenance) : cette attaque vise à vérifier si une donnée spécifique a été utilisée durant l’entrainement d’un modèle d’IA. Les conséquences peuvent être très importantes, notamment pour les données de santé : imaginez pouvoir vérifier si un individu est atteint d’un cancer ou non ! Cette méthode a été utilisée par le New York Times afin de prouver que ses articles ont été utilisés pour entrainer ChatGPT[1].
Déstabilisation et atteinte à la réputation (impact sur l’intégrité)
La performance d’un modèle de Machine Learning repose sur la fiabilité et la qualité de ses données d’entrainement. Les attaques par poison visent à compromettre les données d’entrainement pour affecter la performance du modèle :
- Déformation de modèle : l’attaque vise à manipuler délibérément un modèle durant l’apprentissage (soit à l’entraînement initial, soit après sa mise en production si le modèle continue à apprendre) afin d’introduire des biais et orienter les prédictions du modèle. En conséquence, le modèle biaisé pourra favoriser certains groupes ou certaines caractéristiques, ou être orienté vers des prédictions malveillantes.
- Backdoors : un attaquant peut entrainer et diffuser un modèle corrompu contenant une porte dérobée. Un tel modèle fonctionne normalement jusqu’à un input contenant un trigger modifie son comportement. Ce trigger peut être un mot, une date ou une image. Par exemple, un système de classification de logiciel malveillant peut laisser passer un logiciel malveillant s’il voit un mot clé spécifique dans son nom ou à partir d’une date spécifique. Du code malveillant peut aussi être exécuté[2] !
L’attaquant peut également rajouter un bruit soigneusement sélectionné pour tromper la prédiction d’un modèle sain. On parle d’exemple adversaire ou d’attaque par évasion :
- Attaque par évasion (adversarial attack): cette attaque a pour objectif de faire générer au modèle une sortie non prévue par le concepteur (se tromper dans une prédiction ou provoquer un dysfonctionnement dans le modèle). Cela peut être fait en modifiant légèrement l’entrée pour éviter d’être détectée comme entrée malveillante. Par exemple :
-
- Demander au modèle de décrire une image blanche qui contient un prompt injection caché, écrit blanc sur blanc dans l’image.
- Porter une paire de lunettes spécifique pour éviter d’être reconnu par un algorithme de reconnaissance faciale[3]
- Ajouter un sticker quelconque sur un panneau « Stop » pour que le modèle reconnaisse un panneau de « Limitation de 45km/h »[4]
Impact sur la disponibilité
Au-delà du vol de données et de l’impact sur l’image, les attaquants peuvent également entraver la disponibilité des systèmes d’Intelligence Artificielle (IA). Ces tactiques ne visent pas seulement à rendre les données indisponibles, mais aussi à perturber le fonctionnement régulier des systèmes. On peut citer l’attaque par empoisonnement, qui aura pour impact de rendre indisponible le modèle le temps de le réentraîner (ce qui aura également un impact économique dû au coût de réentraînement du modèle). Voici un autre exemple d’attaque :
- Attaque par déni de service (DDOS) du modèle : comme toutes les autres applications, les modèles de Machine Learning sont sensibles aux attaques de déni de service qui peuvent entraver la disponibilité des systèmes. L’attaque peut combiner un nombre élevé de requêtes, tout en envoyant des requêtes très lourdes à traiter. Dans le cas des modèles de Machine Learning, les conséquences financières sont plus importantes car les tokens/prompts coûtent très cher (par exemple, ChatGPT n’est pas rentable malgré leurs 616 millions d’utilisateurs mensuels).
Deux pistes pour sécuriser vos projets d’IA : adapter vos contrôles cyber existants, et développer les mesures spécifiques de Machine Learning
Tout comme les projets en sécurité, une analyse de risque préalable est nécessaire afin d’implémenter les bons contrôles, tout en trouvant un compromis acceptable entre la sécurité et le fonctionnement du modèle. Pour ce faire, nos méthodes de risques traditionnelles doivent évoluer afin d’inclure les risques précédemment détaillés, qui ne sont pas bien couverts par les méthodes historiques.
A la suite de ces analyses de risques, des mesures de sécurité devront être implémentées. Wavestone a recensé plus de 60 mesures différentes. Dans cette deuxième partie, nous vous présentons une petite sélection de ces mesures à implémenter selon la criticité de vos modèles.
1. Adapter les contrôles cyber aux modèles de Machine Learning
La première ligne de défense correspond aux mesures applicatives, infrastructurelles et organisationnelles de base de la cybersécurité. L’objectif est d’adapter des exigences qu’on connait déjà, qui sont présentes dans les différentes politiques de sécurité, mais qui ne s’appliquent pas forcément de la même manière pour des projets d’IA. Il faut prendre en compte ces spécificités, parfois assez fines.
L’exemple le plus parlant est celui de la réalisation de pentests IA. Les pentests classiques consistent à trouver une vulnérabilité pour rentrer dans le système d’information. Or, les modèles d’IA peuvent être attaqués sans rentrer dans le SI (comme les attaques par évasion et oracle). Les procédures de RedTeaming doivent évoluer pour traiter ces particularités, tout en faisant évoluer les mécanismes de détection et de réponse à incident afin de couvrir les nouvelles applications de l’IA.
Un autre exemple essentiel est celui de l’isolation des environnements d’IA utilisés tout au long du cycle de vie des modèles de Machine Learning. Cela permet de réduire les impacts d’une compromission en protégeant les modèles, les données d’entraînement et les résultats de prédiction.
Il faut également évaluer les réglementations et les lois auxquelles l’application de Machine Learning doit se conformer et respecter les dernières lois en vigueur sur l’intelligence artificielle (IA Act en Europe, par exemple).
Et enfin, une mesure plus que classique : les campagnes de sensibilisation et de formation. Il faut s’assurer que les parties prenantes (chef de projet, développeurs, etc.) soient formés aux risques des systèmes d’IA et que les utilisateurs soient avertis de ces risques.
2. Les contrôles spécifiques pour protéger les modèles de Machine Learning sensibles
Au-delà des mesures classiques à adapter, des mesures spécifiques doivent être identifiées et appliquées.
Pour vos projets les moins critiques, faites simple et implémentez la base
Poison control : afin de se prémunir des attaques par empoisonnement, il faut détecter toute « fausse » donnée ayant pu être injectée par un attaquant. La mesure consiste à mettre en œuvre une analyse statistique exploratoire pour repérer les données empoisonnées (analyser la distribution des données et repérer les données absurdes par exemple). Cette étape peut être incluse dans le cycle de vie d’un modèle de Machine Learning pour automatiser les actions en aval. Cependant, une vérification humaine sera toujours nécessaire.
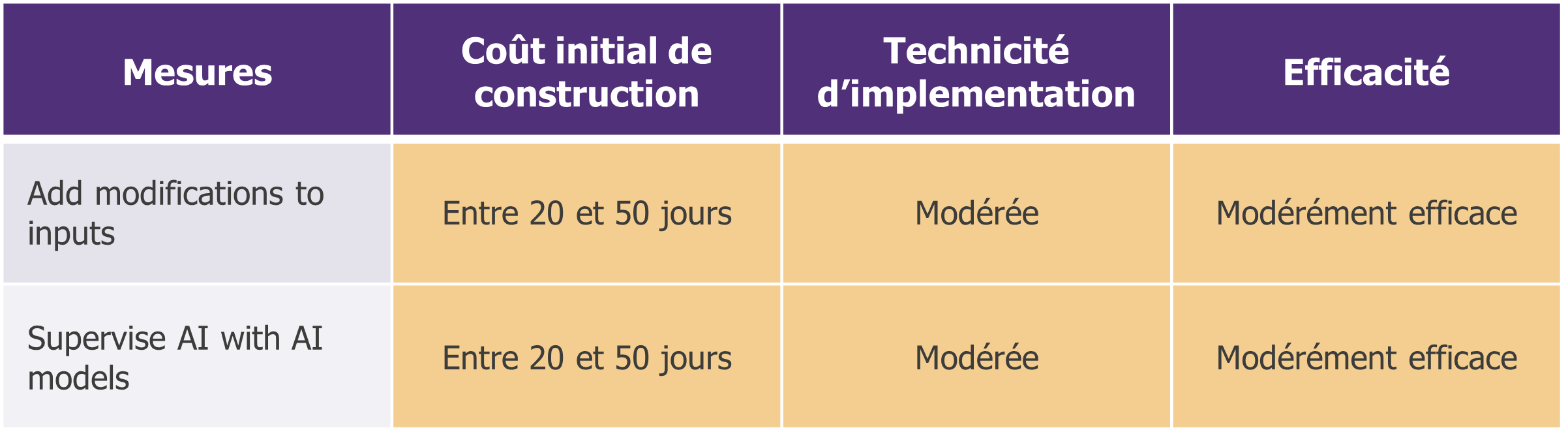
Input control (analyser les entrées fournies par un utilisateur) : pour contrer les attaques par prompt injection et par évasion, les entrées de l’utilisateur sont analysées et filtrées pour bloquer toutes les entrées malveillantes. Nous pouvons penser à des règles basiques (bloquer les requêtes contenant un mot spécifique) comme des règles statistiques plus spécifiques (format, consistance, cohérence sémantique, bruit, etc.). Cependant, cette approche peut avoir un impact négatif sur la performance du modèle, car les faux-positifs seraient bloqués.

Pour vos projets moyennement sensibles, viser un bon rapport investissement / couverture du risque
Des mesures, il y en a pléthores, et la littérature sur le sujet est très riche. En revanche, certaines mesures permettent de couvrir plusieurs risques à la fois. Il nous paraît intéressant de les considérer en premier.
Transform inputs : une étape de transformation de l’entrée est rajoutée entre l’utilisateur et le modèle. L’objectif est double :
- Supprimer ou modifier toute entrée malveillante en reformulant l’entrée ou en la tronquant par exemple. Une implémentation via des encodeurs est également possible (mais sera détaillée dans la partie d’après).
- Réduire la visibilité de l’attaquant pour contrer les attaques par oracle (qui nécessite de connaitre précisément l’entrée et la sortie du modèle) en rajoutant un bruit aléatoire ou en reformulant le prompt par exemple.
Selon la méthode d’implémentation, des impacts sur la performance du modèle sont à prévoir.
Supervise AI with AI models : tout modèle d’IA apprenant après sa mise en production doit faire l’objet d’une supervision spécifique dans des processus globaux de détection et de réponse aux incidents. Cela implique à la fois de collecter les journaux appropriés pour réaliser des investigations, mais également de surveiller la déviation statistique du modèle pour repérer toute dérive anormale. En d’autres termes, il s’agit d’évaluer dans le temps l’évolution de la qualité des prédictions. Le modèle Tay de Microsoft lancé sur Twitter en 2016 est un bon exemple d’un modèle qui a dérivé.
Pour vos projets critiques, allez plus loin pour couvrir les risques spécifiques
Il y a des mesures qui nous paraissent très efficaces pour couvrir certains risques. Bien sûr, cela implique de faire une analyse de risques en amont. Voici deux exemples (parmi tant d’autres) :
Randomized Smoothing : une technique d’entrainement visant à renforcer la robustesse des prédictions d’un modèle. Ce dernier est entraîné deux fois : une première fois avec les données d’entraînement réelles, puis une seconde fois avec ces mêmes données altérées par du bruit. L’objectif est d’avoir le même comportement, en présence d’un bruit dans l’entrée ou non. Cela limite ainsi les attaques par évasion, notamment pour les algorithmes de classification.
Apprentissage par exemples contradictoires (adversarial learning) : l’objectif est d’apprendre au modèle à reconnaitre une entrée malveillante pour le rendre plus robuste aux Adversarial Attacks. Concrètement, cela revient à labéliser des exemples contradictoires (soit une vraie entrée qui inclus une petite erreur / perturbation) comme des données malveillantes et à les ajouter durant la phase d’entraînement. En confrontant le modèle à ces attaques simulées, il apprend à reconnaître et à contrer les patterns malveillants. La mesure est très efficace mais elle implique un certain coût en ressources (phase d’entraînement plus longue) et peut avoir un impact sur la précision du modèle.

Les gardiens polyvalents – trois sentinelles de la sécurité en IA
Trois méthodes ressortent du lot par leur efficacité et leur capacité à mitiger plusieurs scénarios d’attaques simultanément : le GAN (Generative Adversarial Network), les filtres (encodeurs et auto-encodeurs qui sont des modèles de réseaux de neurones) et l’apprentissage fédéré.
Le GAN : le faussaire et le critique
Le GAN, ou Réseau Génératif Antagoniste (« Generative Adversarial Network » en anglais), est une technique d’entraînement de modèle d’IA qui fonctionne comme un faussaire et un critique travaillant ensemble. Le faussaire, appelé le générateur, crée des « copies d’œuvres d’art » (comme des images). Le critique, appelé le discriminateur, évalue ces œuvres pour identifier les fausses œuvres des vraies et donne des conseils au faussaire pour s’améliorer. Les deux travaillent en tandem pour produire des œuvres de plus en plus réalistes jusqu’à ce que le critique n’arrive plus à identifier les fausses données des vraies.
Un GAN peut aider à réduire la surface d’attaque sur deux façons :
- Avec le générateur (le faussaire) pour éviter les fuites de données sensibles. Une nouvelle base de données d’entrainement fictive peut être générée, semblable à l’originale, mais ne contenant pas de données sensibles ou personnelles.
- Avec le discriminateur (le critique) limite les attaques par évasion ou par empoisonnement en identifiant les données malveillantes. Le discriminateur compare les entrées d’un modèle avec ses données d’entrainement. Si elles sont trop différentes, alors l’entrée est classée comme malveillante. En pratique, il est capable de prédire si une entrée appartient aux données d’entraînement en lui associant un scope de vraisemblance.
Les auto-encodeurs : un algorithme d’apprentissage non supervisé pour filtrer les entrées et les sorties
Un auto-encodeur transforme une entrée dans une autre dimension, modifiant sa forme mais pas son essence. Pour prendre une analogie simplificatrice, c’est comme si le prompt était résumé et réécrit pour supprimer les éléments indésirables. En pratique, l’entrée est compressée par un encodeur supprimant ainsi le bruit (via une première couche du réseau de neurones), puis elle est reconstruite via un décodeur (via une deuxième couche). Ce modèle a deux utilisations :
- Si un auto-encodeur est positionné en amont du modèle, il aura la capacité de transformer l’input avant qu’il ne soit traité par l’application, supprimant de potentielles charges malveillantes. De cette manière, il devient plus difficile pour un attaquant d’introduire des éléments permettant une attaque par évasion par exemple.
- Nous pouvons utiliser ce même système en aval du modèle pour se protéger des attaques oracle (qui visent à extraire des informations sur les données ou le modèle en les interrogeant). Les sorties seront ainsi filtrées, réduisant la verbosité du modèle, c’est-à-dire en réduisant la quantité d’information en sortie du modèle.
Federated Learning : l’union fait la force
Lorsqu’un modèle est déployé sur plusieurs appareils, une méthode d’apprentissage délocalisée telle que l’apprentissage fédéré peut être employée. Le principe : plusieurs modèles apprennent localement avec leurs propres données et ne remontent au système central que leurs apprentissages. Cela permet à plusieurs appareils de collaborer sans partager leurs données brutes. Cette technique permet de couvrir un grand nombre de risques cyber des applications basées sur des modèles d’intelligence artificielle :
- La segmentation des bases de données d’entraînement joue un rôle crucial dans la limitation des risques d’empoisonnement par Backdoor et par Model Skewing. Du fait que les données d’entraînement sont spécifiques à chaque appareil, il devient extrêmement difficile pour un attaquant d’injecter des données malveillantes de manière coordonnée, étant donné qu’il n’a pas accès à l’ensemble global des données d’entraînement. Cette même division limite les risques d’extraction de données.
- Le processus d’apprentissage fédéré permet également de limiter les risques d’extraction de modèle. Le processus d’apprentissage rend extrêmement complexe le lien entre les données d’entraînement et le comportement du modèle, car celui-ci n’opère pas un apprentissage direct. Il devient alors difficile pour un attaquant de comprendre le lien entre les données d’entrée et les données de sorties.
Ensemble, le GAN, les filtres (encodeurs et auto-encodeurs) et l’apprentissage fédéré forment une bonne proposition de couverture de risque pour les projets de Machine Learning malgré la technicité de leur mise en œuvre. Ces gardiens polyvalents démontrent que l’innovation et la collaboration sont les piliers d’une défense robuste dans le paysage dynamique de l’intelligence artificielle.
Pour aller plus loin, Wavestone a rédigé pour l’ENISA un guide pratique pour sécuriser le déploiement d’apprentissage automatique dans lequel sont listés les différents contrôles de sécurité à établir.
En résumé
L’intelligence artificielle peut être compromise par des méthodes que l’on ne rencontrait pas usuellement sur nos systèmes d’information. Il n’existe pas de risque zéro : tout modèle est vulnérable. Pour mitiger ces nouveaux risques, des mécanismes de défense supplémentaires sont à prendre en main et à implémenter selon le niveau de criticité du projet. Un compromis devra alors être trouvé entre la sécurité et la performance du modèle.
La sécurité de l’IA est un domaine très actif, des internautes de Reddit jusqu’aux travaux de recherche poussés sur la déviation de modèle par exemple. C’est pourquoi il est important d’organiser une veille organisationnelle et technique sur le sujet.
[1] New York Times proved that their articles were in AI training data set
[2] Au moins une centaine de modèles d’IA malveillants seraient hébergés par la plateforme Hugging Face
[3] Sharif, M. et al. (2016). Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. ACM Conference on Computer and Communications Security (CCS)
[4] Eykholt, K. et al. (2018). Robust Physical-World Attacks on Deep Learning Visual Classification. CVPR. https://arxiv.org/pdf/1707.08945.pdf

