
In nearly 90% of the incidents managed by Wavestone CERT [1], the Active Directory domain was compromised: rapid rebuilding capabilities are no longer an option. However, the backup and recovery of Active Directory environments is a subject that has long been assumed to be under control: backups are made daily, recovery tests are performed often and at regular intervals, BCP/DRP tests are conducted to ensure business continuity and recovery capabilities. But very often these processes have not evolved for several years and have not kept pace with the evolution of the cyber threat.
Thinking about the right way to deal with this topic in organisations is at the crossroads of AD security enhancement and cyber resilience projects.
Infrastructure and backup agents: weak points
Our various assessments over the last few months have shown that backup strategies have not always evolved towards the state of the art.
First problem: backup infrastructures are not resilient to cyber risk by default. For example, authentication on these backup infrastructures is very often linked to the Active Directory itself. Subsequently, the backup system could be compromised by the attacker, leading to a potential destruction of the backups… including those of the Active Directory!
And backups are a prime target for attackers. In more than 20% of the incidents managed by the Wavestone CERT in 2021, backups were impacted. It is therefore important to consider the cyber scenario – and especially the ransomware scenario – when thinking about the resilience of backups.
The second problem is that Domain Controllers (DC) backups are hosted in the backup tool, which often has a lower level of security than Active Directory. Indeed, an organisation that has already done some work to secure AD will have potentially greatly strengthened its tier 0 (always back to the tiering model!): setting up dedicated workstations for administration, multi-factor authentication, network filtering, dedicated hardware, limiting the number of privileged accounts, etc. Unfortunately, this will not necessarily be the case for the backup infrastructure. As these backups are not necessarily encrypted, an attacker could recover and exfiltrate them from a DC via the backup infrastructure, which is easier to compromise. Once the backup has been depleted, the attacker will be able to extend the scope of his compromise via a ‘pass the hash’ attack, after recovering the hashes, or a brute force attack, after extracting the secrets from the ntds.dit database to recover passwords in clear text, to be replayed on services whose authentication is not based on Active Directory.
Third problem: traditional backup methods rely on agents installed on Domain Controllers, whose high privileges sometimes increase the risk of systems becoming compromised. Backup agents almost always require administrative rights to the asset being backed up, which mechanically exposes the Domain Controllers and therefore the Active Directory domains. This leads to the paradoxical situation where the measure to reduce the risk of unavailability (installation of a backup agent on a DC) becomes the vulnerability itself that causes a risk that can become critical (unavailability of the entire information system).
Backup on disconnected media, on immutable infrastructure, or in the cloud: multiple strategies for multiple scenarios
To solve these two problems, multiple solutions exist, and their combination facilitates the construction of a robust strategy. This strategy must consider the context of the organisation as well as its cybersecurity maturity.
To address the first problem induced by the vulnerable agent, two approaches exist, both viable:
- Reduce the probability of exploitation of the vulnerability induced by the backup agent. In addition to the classic security maintenance issues (regular updates, rapid correction of agent vulnerabilities, etc.), this involves integrating a dedicated backup tool into tier 0, whose security level will have been reinforced.
- Get rid of the backup agent. How can this be done? By using the native Windows Backup feature, which allows a backup to be made and exported, which can be encrypted and taken out of the tier 0 asset, to a tier 1 asset, which itself can be backed up by the company’s standard backup solution.
To increase the resilience of Active Directory backups, a combination of measures should be taken wherever possible:
- Externalize the backup on media (offline version). The first variant can be set up quickly and at low cost: it involves setting up an external hard disk which will be disconnected once the backup has been made. Then, it is simply a matter of setting up the associated organisational processes so that the necessary actions can be carried out without the relevant agents forgetting. The second option, for the rare organisations that still have them, is to rely on tapes. This option is also dependent on a key process: the regular backup and outsourcing of the backup catalogue, so as not to lose time in the event of restoration, should it also disappear (a story inspired by real events encountered by our incident response teams). A word of caution: tape backups should be seen as a last resort to ensure that a copy of the data is retained in the event of a disaster scenario. In fact, this backup format does not lend itself to rapid reconstruction, due to the considerable time required before restoration to the production IS can begin: time required to repatriate the tapes and time required to read their content.
- Outsource the backup outside the (online) information system. Whether this is done using in-house scripts or market solutions (see our radar), after robust encryption, a backup can be outsourced. The advantage of market solutions is that they directly integrate the rapid reconstruction element (see next section) of a DC.
- Rely on a complementary but independent backup. To increase the availability of the backup infrastructure, it is sufficient to (redundantly) ensure that there is no risk of simultaneous compromise. To this end, taking advantage of their transition to the cloud, many organisations have recently chosen to add an additional DC, but hosted in the cloud (the others being traditionally still on-premises), thus naturally benefiting from its own backup mechanisms. Due to the internal replication mechanisms of AD, the DC hosted in the cloud will be compromised (compromise of some accounts or AD configurations) in the same time scale as the on-premises ones, but due to the closeness between the backed-up assets and the backup system, one will have a greater chance of having a backup of a DC still available.
- Make your backup infrastructure immutable by relying as much as possible on the solutions offered by backup software publishers. Indeed, most publishers now offer immutability mechanisms, which sometimes do not require the purchase of additional storage bays. By making backups immutable within their primary storage, you can be sure of an optimal reconstruction time since it will not be necessary to repatriate backups from offline storage (1.) or online storage (2.) before being able to start restoring. N.B.: 2. can and should benefit from this concept (Amazon S3, Azure blob, etc.).
| Immutable backup: The adage often associated with this is “write once, read many”, which sums up the concept. This is a backup that relies on files whose state cannot be changed after they have been created, making them resistant to attackers trying to delete them. In practice, neither the administrator of the backup software nor the administrator of the storage arrays can delete or alter a backup identified as immutable. |
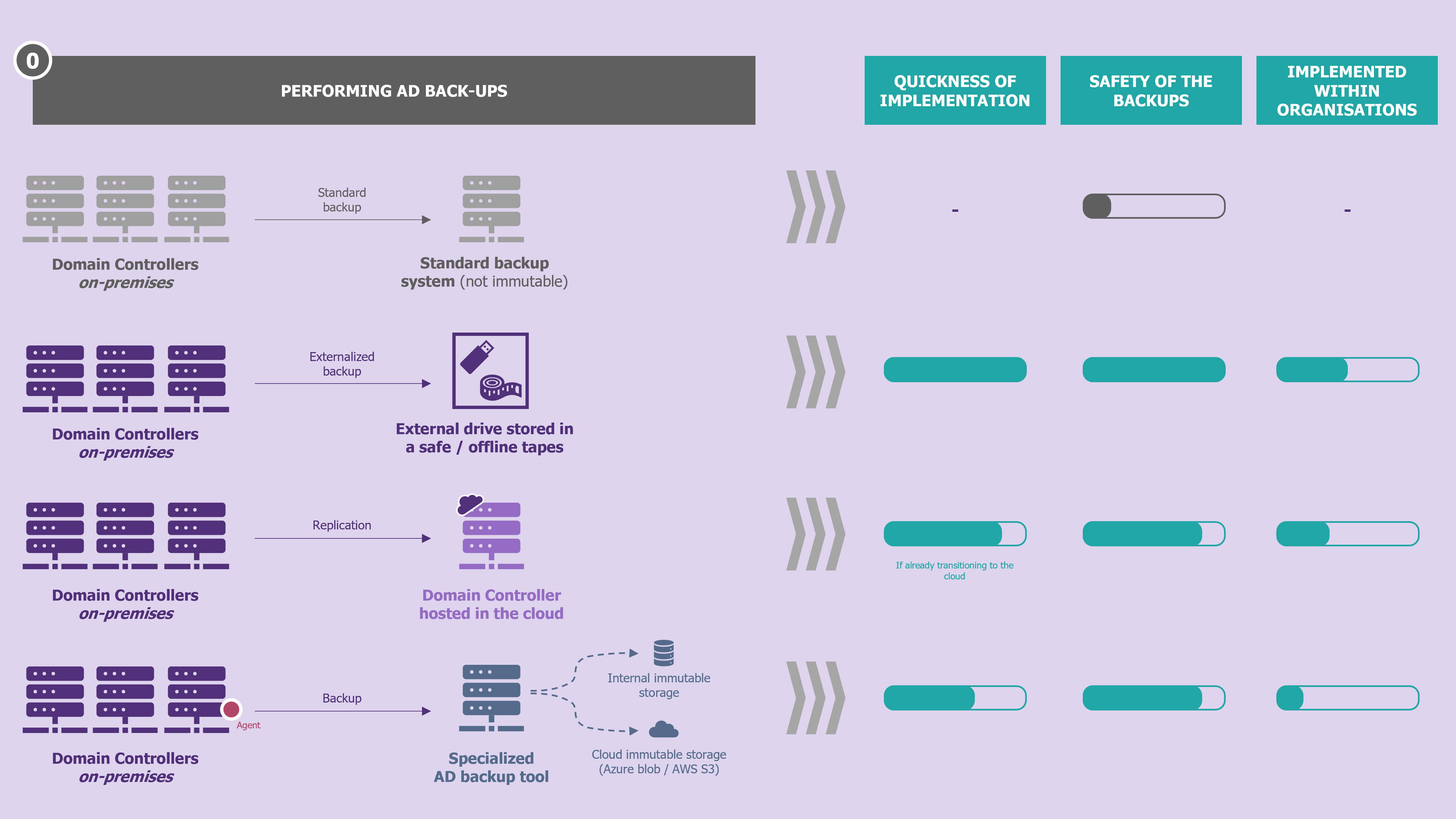
Finally, one last point of detail, knowing which DCs to back up and use for restoration when necessary is essential (DC Global Catalog, most recent OS version, etc.), as is knowledge of the frequency (ideally daily) and the retention period (a much more subjective subject).
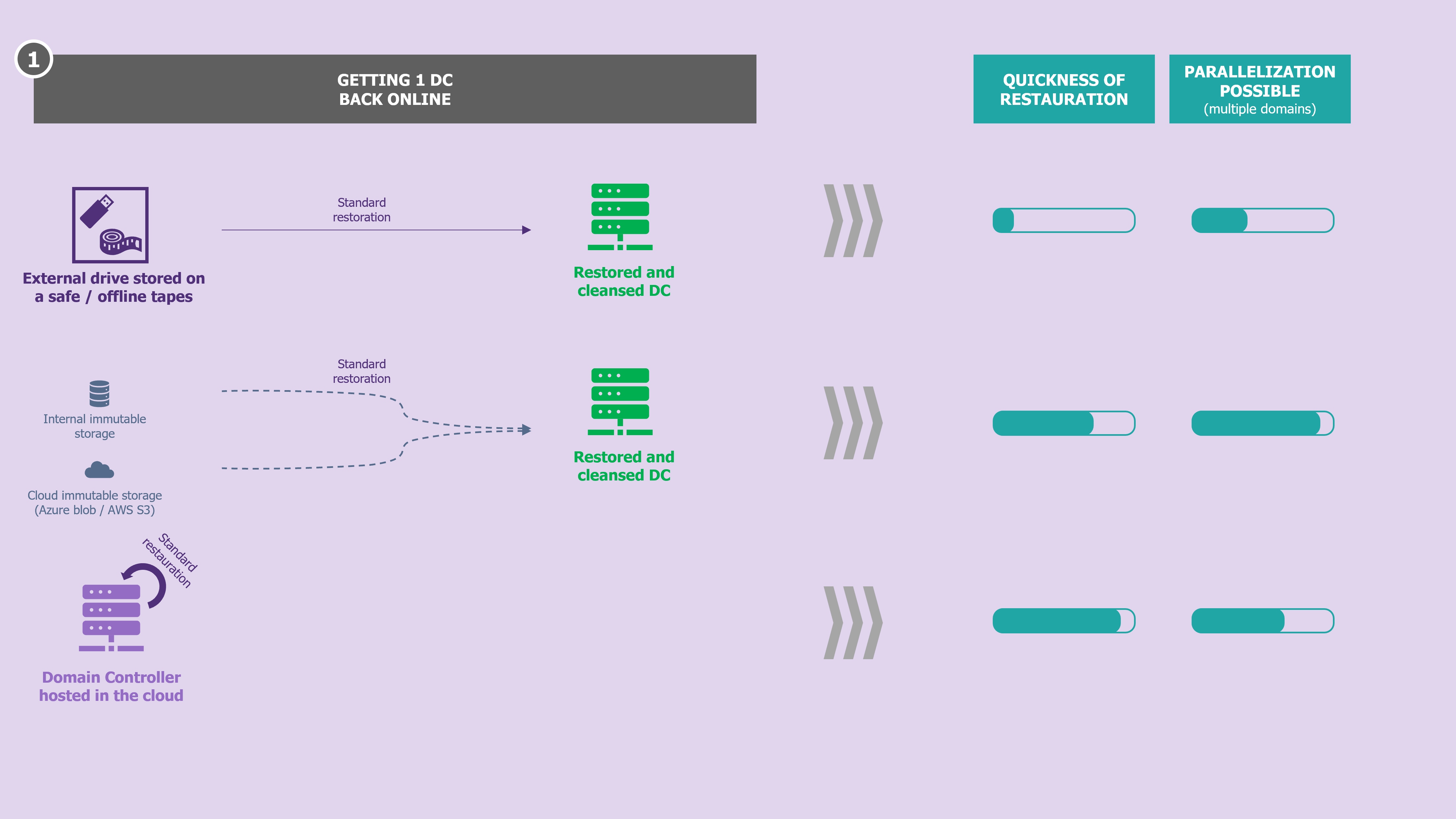
Fast rebuilding : often incompletely tested capabilities
Rebuilding tests are as old as the concept of DRP. But again, one can’t just rely on these annual tests to consider oneself prepared, given the state of the threat. Indeed, these tests are very often based on assumptions that will not be verified in the event of a major cyber-attack: available backups, confidence in the state of the information system, functional collaborative tools (workstations, messaging, ticketing tools, etc.), ready and available target hosting infrastructure, etc.
From what we observe in organisations, the times displayed and communicated on the reconstruction times of an AD domain are often underestimated a priori. The start and stop times of the stopwatch are often questionable: it starts when the backup recovery start button is pressed and stops when a DC is restored and operational (AD forest recovery procedure executed [2]). However, some points are often overlooked when comparing this time to the RTO time:
- unsatisfied dependency on another indispensable domain (domain with one or more approval relationships with other domains),
- ability to handle the authentication load that a service reopening will represent,
- execution time for “grooming” operations (mass password change, deactivation of certain services or accounts, clean-up in objects and groups, etc.),
- etc.
When the AD infrastructure is paralysed by a major cyber-attack, rebuilding it will quickly become the crisis unit’s priority, because of the dependence of applications and users on it. It is also the service with the lowest RTO. In the case where backups are available, certain questions quickly arise that must be addressed in the cyber defense strategy that is being defined (see our article on Successful Ransomware Crisis Management: Top 10 pitfalls to avoid):
- Is there a need for an area to accommodate sensible future infrastructure?
- Does creating users in Azure AD during the crisis allow the service to be reopened more quickly?
- If there are many AD domains (as is the case with very large organisations), in what order should they be created?
On the infrastructure side, firstly, in most cases, having an isolated and secure rebuild area saves time. This must be available, ready to host the number of VMs required to achieve the level of service considered acceptable in such a situation and under the control (accounts with sufficient rights, accessibility, etc.) of the team responsible for the Active Directory service only. This is to reduce the risk of compromise but also to avoid creating obstacles (requests to be made to another team) the day the need arises.
This zone can be on-premises or in a cloud service, depending on the costs and the organisation’s cybersecurity posture with regard to hosting DC on a cloud (if it is public). This dormant zone can also be used to host regular Active Directory recovery tests, to get as close as possible to a real situation. Finally, this infrastructure must obviously be in tier 0, if the organisation relies on this framework.
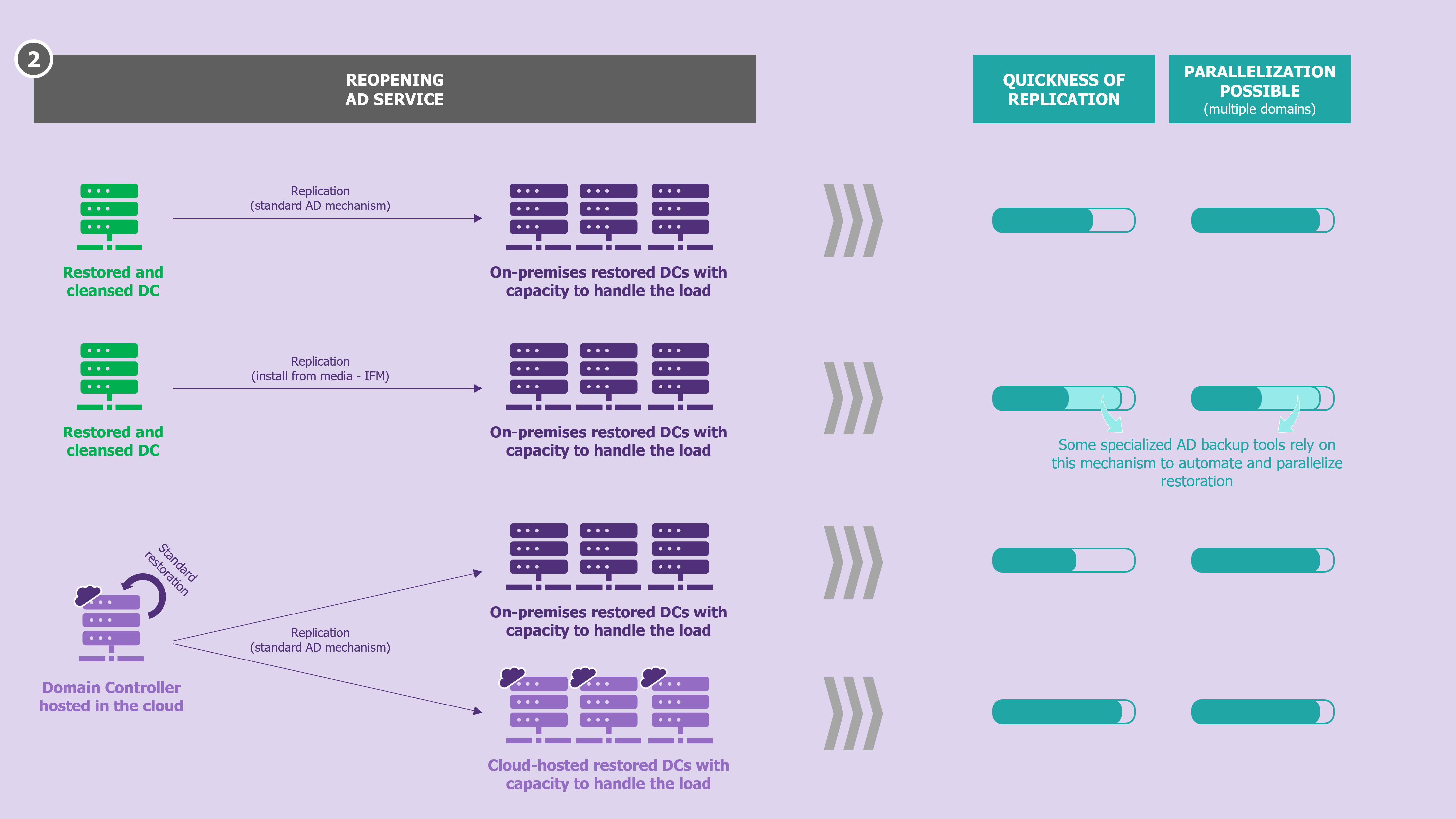
Then, on the process side, it is advisable to prepare several pieces of information in advance that will be essential when the need to rebuild the service arises:
- determine the minimum number of DCs and their location (rebuilding area in the cloud / on-premises, but also geographically in case of presence in multiple locations),
- determine the replication method (standard replication or use of IFM [3]) of the DCs to minimise the time between the availability of the first and last DC required to reopen the service,
- determine ready and deactivated filtering rules, which only need to be activated before the service is opened,
- establish the acceptable level of risk for the rebuild (simple rebuild and object grooming or pivot method),
- (in organisations with multiple domains serving multiple businesses) establish a rebuild sequence, which should have been determined in advance with the business managers, to reopen the service with the right priorities.
Here again, specialised AD backup and recovery tools provide value: they allow the recovery process of an AD forest to be carried out in a few clicks and in an automated manner. Parallelization of these operations is also made possible, making these tools an undeniable accelerator to consider for organizations with many forests!
Finally, on the resources side, it is important to have an organisation that can respond to this occasional but very important work overload. For this, the automation of reconstruction activities that can be automated, but also the existence of teams that have already practised the exercise many times, is often decisive.
Some organisations take advantage of Disaster Recovery testing to simulate the worst possible situation for the Active Directory service, rather than just simulating a partial recovery. This is undoubtedly good practice.
Ultimately, asking the question of the resilience of one’s Active Directory infrastructure draws on the more global subject of information system resilience, but also concepts around tiering, and considerations regarding regularly scheduled full-scale exercises. We could even make a bridge with DevOps: wouldn’t we dream of being able to redeploy an AD infrastructure almost automatically, in the image of what DevOps manages to do thanks to the ‘Infrastructure as Code’ concept? In the meantime, regular training remains the only way to develop confidence about one’s ability to quickly reopen a minimal AD service if it were to be completely destroyed.
[1] https://www.wavestone.com/en/insight/cert-w-2022-cybersecurite-trends-analysis/
[2] https://learn.microsoft.com/fr-fr/windows-server/identity/ad-ds/manage/ad-forest-recovery-guide
[3] Install From Media : https://social.technet.microsoft.com/wiki/contents/articles/8630.active-directory-step-by-step-guide-to-install-an-additional-domain-controller-using-ifm.aspx

