
L’arrivée de l’intelligence artificielle générative (GenAI) dans le monde des entreprises marque un tournant dans l’histoire du numérique. Cela se manifeste par des outils novateurs comme ChatGPT d’OpenAI (qui a su s’implanter dans Bing sous le nom de « Bing Chat », exploitant le modèle de langage GPT-4) et Copilot de Microsoft 365. Ces technologies, qui étaient auparavant de simples sujets d’expérimentation et faisaient l’actualité dans les médias, sont désormais au cœur des entreprises, redéfinissant les workflows et dessinant la trajectoire future de secteurs entiers.
Bien qu’il y ait eu des avancées significatives en la matière, il existe également des défis. Par exemple, des données sensibles de Samsung ont été exposées sur ChatGPT par des employés (l’intégralité du code source d’un programme de téléchargement d’une base de données)[1]. Pour ne rien arranger, ChatGPT [OpenAI], a subi une faille de sécurité qui a touché plus de 100 000 utilisateurs entre juin 2022 et mai 2023, et les informations d’identification compromises sont désormais échangées sur le Dark Web[2].
Ainsi, il n’est par surprenant qu’il y ait à la fois de l’enthousiasme et de la prudence à l’égard du potentiel de l’IA générative. Compte tenu de ces complexités, il est compréhensible que de nombreuses personnes soient confrontées à la difficulté de déterminer l’approche optimale de l’IA. Dans cette optique, cet article cherche à répondre aux questions les plus posées par nos clients.
Question 1 : L’IA générative n’est-elle qu’un effet de mode ?
L’IA est un ensemble de théories et de techniques mises en œuvre afin de créer des machines capables de simuler les fonctions cognitives de l’intelligence humaine (vision, écriture, mouvement…). Un sous-domaine de l’IA, particulièrement intéressant, est « l’IA générative ». Elle peut être définie comme une discipline utilisant des algorithmes avancés, notamment les réseaux de neurones artificiels, pour générer de manière autonome du contenu, qu’il s’agisse de textes, d’images ou de musique. Au-delà du chatbot bancaire qui répondant à vos interrogations, l’IA générative ne se limite pas à reproduire nos capacités de manière impressionnante, elle les améliore dans certains cas.
Notre observation du marché indique que : la portée de l’IA générative est large et profonde. Elle contribue à divers domaines tels que la création de contenu, l’analyse de données, la prise de décision, le support client et même la cybersécurité (par exemple, en identifiant des structures de données anormales pour contrer les menaces). Nous avons identifié trois domaines dans lesquels l’IA générative est particulièrement utile.
Personnalisation du marketing et de l’expérience client
L’IA générative permet de mieux comprendre les comportements et les préférences des clients. En analysant les modèles de données, elle permet aux entreprises d’élaborer des messages et des visuels sur mesure, améliorant ainsi l’engagement et garantissant des interactions personnalisées.
Solutions no-code et amélioration du support client
Dans un monde numérique en constante évolution, les concepts de solutions no-code et d’amélioration du service client sont de plus en plus mis en avant. Bouygues Telecom est un bon exemple d’entreprise exploitant des outils avancés. Ils analysent activement les interactions vocales enregistrées lors de conversations entre les conseillers et les clients, dans le but d’améliorer la relation client[3]. Dans le même registre, Tesla utilise l’outil d’IA « Air AI » pour une interaction fluide avec les clients, qui permet de gérer les appels commerciaux avec des clients potentiels, allant même jusqu’à programmer des essais de conduite.
En ce qui concerne la programmation, une expérience intéressante menée par l’un de nos clients se démarque. Impliquant 50 développeurs, le test a révélé que 25% des suggestions de code générées par l’IA ont été acceptées, entraînant une augmentation de 10% de la productivité. Cependant, il est encore tôt pour conclure sur l’efficacité réelle de l’IA générative en matière de programmation, mais les premiers résultats sont prometteurs et devraient s’améliorer. De plus, le problème lié aux droits de propriété intellectuel concernant le code généré par l’IA demeure un sujet de discussion.
Veille documentaire et outil de recherche
L’utilisation de l’IA en tant qu’outil de recherche peut permettre de gagner des heures de travail, notamment dans les domaines où les corpus réglementaires et documentaires sont vastes (ex : secteur financier). Chez Wavestone, nous avons développé en interne, deux outils d’IA. Le premier, CISO GPT, permet aux utilisateurs de poser des questions spécifiques sur la sécurité dans leur langue maternelle. Une fois la question posée, l’outil parcourt la documentation afin d’extraire et de présenter les informations pertinentes. Le second outil, la bibliothèque de références GPT, fournit des CV d’employés de Wavestone ainsi que des références relatives à des missions antérieures pour la rédaction de propositions commerciales.
Cependant, bien que des outils comme ChatGPT (qui utilise des données provenant de bases de données publiques) soient indéniablement bénéfiques, c’est lorsque les entreprises exploitent leurs propres données qu’elles peuvent changer la donne. Pour cela, les entreprises doivent intégrer des capacités d’IA générative en interne ou mettre en place des systèmes assurant la protection de leurs données (comme des solutions cloud telles qu’Azure OpenAI ou des modèles propriétaires). Selon nous, l’IA générative vaut plus que le simple buzz qui l’entoure et est destinée à s’installer durablement. Il existe de réelles applications commerciales et une véritable valeur ajoutée, mais également des risques de sécurité. Votre entreprise doit initier cette dynamique pour pouvoir mettre en œuvre des projets d’IA générative de manière sécurisée.
Question 2 : Quelle est la réaction du marché à l’utilisation de ChatGPT ?
Pour approfondir le point de vue de ceux qui sont en première ligne en matière de cybersécurité, nous avons demandé aux CISO de nos clients leur avis sur les implications et les opportunités de l’IA générative. Par conséquent, le graphique ci-dessous illustre les opinions des CISO sur le sujet.
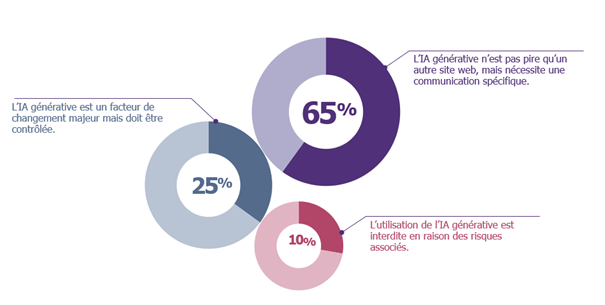
Selon notre enquête, les retours des CISO peuvent être regroupés en trois catégories distinctes :
Les pragmatiques (65%)
La plupart de nos répondants reconnaissent les risques potentiels de fuite de données avec ChatGPT, mais les assimilent aux risques rencontrés sur les forums ou lors d’échanges sur des plateformes telles que Stack Overflow (pour les développeurs). Ils estiment que le risque de fuites de données n’a pas changé de manière significative avec ChatGPT. Cependant, le buzz actuel justifie des campagnes de sensibilisation dédiées pour souligner l’importance de ne pas utiliser des données spécifiques à l’entreprise ou des données sensibles.
Les visionnaires (25%)
Un quart des personnes interrogées considère ChatGPT comme un outil révolutionnaire. Ils ont constaté son adoption dans des départements tels que la communication et les services juridiques. Ils ont pris des mesures proactives pour comprendre son utilisation (quelles données, quel cas d’usage) et ont ensuite établi un ensemble de lignes directrices. Il s’agit d’une approche plus collaborative pour définir un cadre d’utilisation.
Les sceptiques (10%)
Une partie du marché émet des réserves concernant ChatGPT. Pour eux, il s’agit d’un outil trop facile à utiliser à mauvais escient, qui fait l’objet d’une attention médiatique excessive et qui comporte des risques inhérents selon divers secteurs d’activité. Ainsi, en fonction de votre activité, cela peut être pertinent lorsque vous jugez que le risque de fuite de données et de perte de propriété intellectuelle est trop élevé par rapport aux bénéfices potentiels.
Question 3 : Quels sont les risques liés à l’IA générative ?
En évaluant les différents points de vue sur l’IA générative au sein des organisations, nous avons classé les préoccupations en quatre catégories distinctes de risques, du moins grave au plus critique :
Altération et dénaturation du contenu
Les organisations utilisant l’IA générative doivent protéger l’intégrité de leurs systèmes intégrés. Lorsque l’IA est manipulée de manière malveillante, cela peut conduire à la déformation de contenu authentique, conduisant à la désinformation. Cela peut produire des résultats biaisés, ce qui nuit à la fiabilité et à l’efficacité des solutions basées sur l’IA. Plus spécifiquement, pour les grands modèles de langage (Large Language Models – LLM) comme l’IA générative, il existe une préoccupation notable concernant l’injection d’invite (prompt injection). Pour atténuer cela, les organisations devraient :
- Développer un système de classification des entrées (inputs) malveillantes qui évalue la légitimité de l’entrée d’un utilisateur, en veillant à ce que seuls les prompts légitimes soient traités.
- Limiter la taille et modifier le format des entrées utilisateur. En ajustant ces paramètres, les chances de réussite de l’injection d’invite sont considérablement réduites.
Menaces de tromperie et de manipulation
Même si une organisation décide d’interdire l’utilisation de l’IA générative, elle doit rester vigilante face à l’augmentation potentielle de l’hameçonnage, des escroqueries et des attaques de type « deepfake ». Bien que ces menaces existent depuis un certain temps dans le domaine de la cybersécurité, l’introduction de l’IA générative intensifie leur fréquence et leur sophistication.
Ce potentiel est clairement illustré par une série d’exemples frappants. Ainsi, Deutsche Telekom a publié une vidéo de sensibilisation montrant la capacité de l’IA générative à vieillir l’image d’une jeune fille à partir de photos/vidéos disponibles sur les réseaux sociaux.
De plus, HeyGen est un logiciel d’IA générative capable de doubler des vidéos dans plusieurs langues tout en conservant la voix originale. Il est désormais possible d’entendre Donald Trump s’exprimer en français ou Charles de Gaulle converser en portugais.
Ces exemples illustrent clairement comment les attaquants peuvent exploiter ces outils pour imiter la voix d’un PDG, élaborer des emails d’hameçonnage convaincants ou créer des vidéos « deepfake » d’un réalisme saisissant, ce qui intensifie les défis en matière de détection et de défense.
Pour plus d’informations sur l’utilisation de l’IA générative par les cybercriminels, consultez l’article dédié sur RiskInsight.
Confidentialité des données et protection de la vie privée
Si les organisations décident d’autoriser l’utilisation de l’IA générative, elles doivent être conscientes que les immenses capacités de traitement de données offertes par cette technologie peuvent engendrer des risques non négligeables en matière de confidentialité et de protection de la vie privée. Ces modèles, bien qu’excellents dans la génération de contenu, sont susceptibles de divulguer des données d’entraînement sensibles ou de reproduire des contenus soumis au droit d’auteur.
De plus, en ce qui concerne la protection des données personnelles, si l’on se réfère à la politique de confidentialité de ChatGPT, le chatbot est susceptible de collecter des informations comme les détails du compte, les données d’identification provenant de votre appareil ou navigateur, ainsi que les informations saisies dans le chatbot (qui pourraient être utilisées pour entraîner l’IA générative)[4]. Selon l’article 3(a) des conditions générales d’Open AI, les entrées et sorties (inputs/outputs), appartiennent à l’utilisateur. Cependant, étant donné que ces données sont stockées et enregistrées par OpenAI, des préoccupations émergent quant à la propriété intellectuelle et aux éventuelles fuites de données (comme mentionné supra dans le cas de Samsung). Ces risques peuvent nuire considérablement à la réputation et à l’activité d’une organisation.
C’est pour ces raisons qu’OpenAI a mis en place l’abonnement ChatGPT Business, proposant un contrôle accru sur les données de l’organisation (avec, par exemple, le chiffrement AES-256 pour les données au repos, TLS 1.2+ pour les données en transit, l’authentification SSO SAML et une console d’administration dédiée)[5]. Mais en réalité, tout dépend de la confiance que vous accordez à votre fournisseur et du respect des engagements contractuels. De plus, il existe aussi la possibilité de développer ou de former des modèles d’IA internes en utilisant les données de l’organisation pour une solution adaptée aux besoins spécifiques.
Vulnérabilités des modèles et attaques
Alors que de plus en plus d’organisations utilisent des modèles d’apprentissage automatique, il est essentiel de comprendre que ces modèles ne sont pas infaillibles. Ils peuvent être confrontés à des menaces qui affectent leur fiabilité, leur précision ou leur confidentialité, comme cela sera expliqué dans la section suivante.
Question 4 : Comment un modèle d’IA peut-il être attaqué ?
L’IA introduit des complexités supplémentaires qui s’ajoutent aux vulnérabilités existantes du réseau et de l’infrastructure. Il est crucial de noter que ces complexités ne sont pas spécifiques à l’IA générative, mais qu’elles sont présentes dans divers modèles d’IA. Comprendre ces modèles d’attaque est essentiel pour renforcer les défenses et garantir le déploiement sécurisé de l’IA. Il existe trois principaux modèles d’attaque (liste non exhaustive) :
Pour des informations détaillées sur les vulnérabilités des grands modèles de langage et de l’IA générative, référez-vous au “OWASP Top 10 for LLM” de l’Open Web Application Security Project (OWASP).
Attaques par évasion
Ces attaques ciblent l’IA en manipulant les entrées des algorithmes d’apprentissage automatique afin d’introduire des perturbations mineures qui entraînent des modifications significatives des sorties. De telles manipulations peuvent amener le modèle d’IA à classer de manière inexacte ou à ignorer certaines entrées. Un exemple classique serait de modifier des panneaux de signalisation pour tromper les voitures autonomes (identifier un panneau « stop » comme un panneau « priorité »). Cependant, les attaques par évasion peuvent également s’appliquer à la reconnaissance faciale. Une personne pourrait utiliser des motifs de maquillage subtils, des autocollants placés de manière stratégique, des lunettes spéciales ou des conditions d’éclairage spécifiques pour tromper le système, entraînant une mauvaise identification.
En outre, les attaques par évasion ne se limitent pas à la manipulation visuelle. Dans les systèmes de commande vocale, les attaquants peuvent intégrer des commandes malveillantes dans du contenu audio ordinaire, de manière à ce qu’elles soient imperceptibles pour les humains mais reconnaissables par les assistants vocaux. Par exemple, des chercheurs ont démontré l’existence de techniques audio contradictoires ciblant des systèmes de reconnaissance vocale utilisés dans des enceintes intelligentes, telles qu’Alexa d’Amazon. Ainsi, une chanson ou une publicité apparemment ordinaire pourrait contenir une commande dissimulée ordonnant à l’assistant vocal d’effectuer un achat non autorisé ou de divulguer des informations personnelles, le tout à l’insu de l’utilisateur[6].
Empoisonnement
L’empoisonnement est un type d’attaque dans lequel l’attaquant modifie les données ou le modèle pour influencer le comportement de l’algorithme d’apprentissage automatique (par exemple, pour saboter ses résultats ou insérer une porte dérobée). C’est comme si l’attaquant conditionnait l’algorithme en fonction de ses motivations. Ces attaques sont également appelées : attaques causatives.
Conformément à cette définition, les attaquants utilisent des attaques par empoisonnement pour orienter un algorithme d’apprentissage automatique vers un résultat souhaité. Ils introduisent des échantillons malveillants dans l’ensemble des données d’apprentissage, ce qui conduit l’algorithme à se comporter de manière imprévisible. Un exemple connu est celui du chatbot de Microsoft, TAY, qui a été dévoilé sur Twitter en 2016. Conçu pour imiter les adolescents américains et converser avec eux, il s’est rapidement mis à agir comme un activiste d’extrême droite[7]. Cela souligne le fait que, dans leurs premières phases d’apprentissage, les systèmes d’IA sont sensibles aux données qu’ils rencontrent. Les utilisateurs de 4Chan ont intentionnellement empoisonné les données de TAY avec leur humour et leurs conversations controversées.
Toutefois, l’empoisonnement des données peut également être involontaire et résulter de préjugés inhérents aux sources de données ou de préjugés inconscients de ceux qui organisent les ensembles de données. Cela s’est manifesté lorsque les premières technologies de reconnaissance faciale ont eu des difficultés à identifier les teints de peau plus foncés. Il est donc nécessaire de disposer de données d’entraînement diversifiées et non-biaisées pour se prémunir contre les distorsions délibérées ou involontaires des données.
Enfin, la prolifération en ligne d’algorithmes d’IA en open source, tels que ceux présents sur des plateformes comme Hugging Face, présente un autre risque. Les acteurs malveillants pourraient modifier et empoisonner ces algorithmes pour favoriser des biais spécifiques, conduisant des développeurs peu méfiants à intégrer par inadvertance des algorithmes corrompus dans leurs projets, perpétuant ainsi les biais ou les intentions malveillantes.
Attaque oracle
Ce type d’attaque consiste à tester/sonder un modèle avec une série d’entrées soigneusement conçues, tout en analysant les sorties. Grâce à l’application de diverses stratégies d’optimisation et à des requêtes répétées, les attaquants peuvent déduire des informations confidentielles, mettant ainsi en péril la vie privée des utilisateurs, la sécurité globale du système où les règles de fonctionnement internes.
Un exemple pertinent est celui du chatbot Bing de Microsoft, alimenté par l’IA. Peu après son lancement, un étudiant de Stanford, Kevin Liu, a exploité le chatbot à l’aide d’une attaque par injection d’invite, l’amenant à révéler ses directives internes et son nom de code « Sidney », alors que l’une des règles fondamentales du système était de ne jamais révéler ce type d’informations[8].
Un précédent article de RiskInsight présentait un exemple d’attaque oracle et par évasion, ainsi que d’autres types d’attaques qui, bien que non spécifiques à l’IA, représentent néanmoins un risque important pour ces technologies.
Question 5 : Quel est l’état de la réglementation ? Comment l’IA générative est-elle réglementée ?
Depuis notre article de 2022, il y a eu des développements significatifs dans la réglementation de l’IA à travers le monde.
L’Union Européenne (UE)
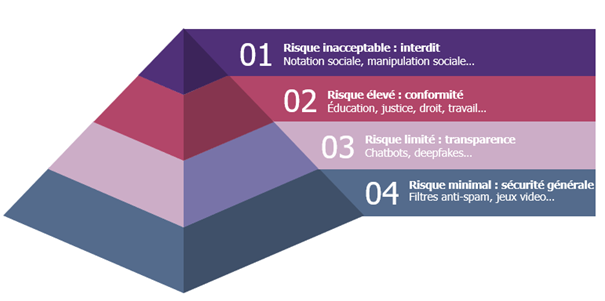
L’objectif de la stratégie numérique de l’UE est de réguler l’IA, en garantissant son développement innovant et son utilisation, tout en assurant la sécurité et les droits fondamentaux des individus et des entreprises vis-à-vis de l’IA. Le 14 juin 2023, le Parlement européen a adopté et amendé la proposition de règlement sur l’Intelligence Artificielle, qui catégorise les risques liés à l’IA en quatre niveaux distincts : inacceptable, élevé, limité et minimal[9].
États-Unis
Le Bureau de la politique scientifique et technologique de la Maison Blanche, guidé par les perspectives de diverses parties prenantes, a présenté le « Blueprint for an AI Bill of Rights »[10]. Bien que non contraignant, ce document souligne l’engagement en faveur des droits civiques et des valeurs démocratiques dans la gouvernance et le déploiement de l’IA.
Chine
Compte tenu des préoccupations croissantes en matière d’IA, l’administration chinoise du cyberespace a proposé des mesures administratives pour les services d’intelligence artificielle générative. Visant à protéger les intérêts nationaux et à préserver les droits des utilisateurs, ces mesures offrent une approche holistique de la gouvernance de l’IA. Elles ont pour but d’atténuer les risques potentiels associés aux services d’intelligence artificielle générative, tels que la diffusion de fausses informations, les violations de la vie privée, les atteintes à la propriété intellectuelle et la discrimination. Toutefois, la portée territoriale de ces mesures pourrait poser problème aux fournisseurs étrangers de services d’IA en Chine[11].
Royaume-Uni
Le Royaume-Uni emprunte une voie distincte, en mettant l’accent sur une approche pro-innovation dans sa stratégie nationale en matière d’IA. Le Département pour la Science, l’Innovation et la Technologie a publié un livre blanc intitulé « AI Regulation: A Pro-Innovation Approach », axé sur le développement par le biais de réglementations minimales et d’investissements accrus dans l’IA. Le cadre britannique ne prescrit pas de règles ou de niveaux de risque à des secteurs ou technologies spécifiques. Il se focalise plutôt sur la réglementation des résultats générés par l’IA dans des applications précises. Cette approche est guidée par cinq principes fondamentaux : la sûreté & la sécurité, la transparence, l’équité, la responsabilité & la gouvernance, et la contestabilité & la réparation[12].
Cadres de référence
Au-delà des règlementations formelles, plusieurs documents d’orientation existent, tels que le cadre de gestion des risques associés à l’IA du NIST et la norme ISO/IEC 23894. Ces textes fournissent des recommandations pour la gestion des risques liés à l’IA, se concentrant sur des critères destinés à instaurer la confiance dans les algorithmes. En fin de compte, l’enjeu ne se limite pas à la cybersécurité, il s’agit aussi et surtout de confiance.

Avec un paysage réglementaire aussi vaste, les organisations peuvent se sentir dépassées. Pour les aider, nous suggérons de se concentrer sur des considérations clés lors de l’intégration de l’IA dans leurs opérations, afin d’établir une feuille de route pour atteindre la conformité.
- Identifier tous les systèmes d’IA existants au sein de l’organisation et établir une procédure ou un protocole pour identifier les nouvelles initiatives en matière d’IA.
- Évaluer les systèmes en utilisant des critères dérivés de cadres de référence, tels que le NIST.
- Classer les systèmes d’IA selon la classification du règlement sur l’IA de l’UE (inacceptable, élevé, limité, minimal).
- Déterminer l’approche de gestion des risques adaptée à chaque catégorie.
Question bonus : Cela étant dit, que puis-je faire maintenant ?
À mesure que le paysage numérique évolue, Wavestone met l’accent sur une approche globale de l’intégration de l’IA générative. Nous préconisons qu’un déploiement d’IA fasse l’objet d’une analyse de sensibilité rigoureuse, allant de l’interdiction pure et simple à une mise en œuvre guidée et une conformité stricte. Pour les systèmes classés à haut risque, il est primordial d’appliquer une analyse de risque détaillée basée sur les normes établies par l’ENISA et le NIST. Bien que l’IA introduise une couche sophistiquée, les principes fondamentaux de l’hygiène informatique ne doivent jamais être négligés. Nous recommandons l’approche suivante :
- Piloter & Valider : commencez par évaluer le potentiel de transformation de l’IA générative dans votre contexte organisationnel. De plus, il est essentiel de comprendre les outils à votre disposition, de s’orienter parmi les diverses options disponibles et de prendre des décisions éclairées en fonction des besoins spécifiques et des cas d’utilisation.
- Perspective Stratégique : Selon notre enquête auprès des CISO de nos clients, déterminez le niveau idéal d’adoption de l’IA pour votre entreprise. Vos aspirations correspondent-elles aux repères d’adoption de 10%, 65% ou 25% ?
- Atténuation des Risques : Ancrez votre stratégie dans une évaluation des risques approfondie, en adéquation avec le niveau d’adoption de l’IA que vous envisagez.
- Élaboration de Politiques : Basez-vous sur votre analyse avantages-risques pour élaborer des politiques d’IA solides et agiles.
- Apprentissage Continu & Vigilance Réglementaire : Maintenez un engagement constant pour rester au fait de l’évolution du paysage réglementaire, et tenez-vous informé des derniers outils, méthodes d’attaque et stratégies de défense.
[1] Des données sensibles de Samsung divulgués sur ChatGPT par des employés (rfi.fr)
[2] https://www.phonandroid.com/chatgpt-100-000-comptes-pirates-se-retrouvent-en-vente-sur-le-dark-web.html
[3] Bouygues Telecom mise sur l’IA générative pour transformer sa relation client (cio-online.com)
[4] Quelles données Chat GPT collecte à votre sujet et pourquoi est-ce important pour votre vie privée en ligne ? (bitdefender.fr)
[5] OpenAI lance un ChatGPT plus sécurisé pour les entreprises – Le Monde Informatique
[6] Selective Audio Adversarial Example in Evasion Attack on Speech Recognition System | IEEE Journals & Magazine | IEEE Xplore
[7] Not just Tay: A recent history of the Internet’s racist bots – The Washington Post
[8] Microsoft : comment un étudiant a obligé l’IA de Bing à révéler ses secrets (phonandroid.com)
[9] Artificial intelligence act (europa.eu)
[10] https://www.whitehouse.gov/wp-content/uploads/2022/10/Blueprint-for-an-AI-Bill-of-Rights.pdf
[11] https://www.china-briefing.com/news/china-to-regulate-deep-synthesis-deep-fake-technology-starting-january-2023/
[12] A pro-innovation approach to AI regulation – GOV.UK (www.gov.uk)

